
E as lições que aprendi
Esta é uma tradução feita por Bernardo Perelló do artigo de Alfonso de la Rocha, o original pode ser visto aqui. 14 de Junho de 2020

Eu já mencionei em minha publicação dedicada ao meu projeto paralelo do painel financeiro que, para mim, a maneira mais efetiva de se aprender algo novo é mergulhar em um “projeto de estimação” que me motiva o suficiente para não o abandonar no meio do caminho. Eu me obriguei a desenvolver o projeto utilizando de novas tecnologias das quais eu gostaria de aprender, então durante o processo, eu acabei ficando com o projeto paralelo finalizado além de um monte de novas habilidades. O painel financeiro foi uma desculpa para aprender GraphQL e ReactJS (para ser honesto, desde então eu tenho usado ativamente o ReactJS mais e mais, então valeu a pena). Hoje eu vou compartilhar minha “desculpa” para aprimorar minhas habilidades em programação concorrente em Go (com goroutines, waitgroups, locks, o usual): Um crawler IPFS construído em libp2p.
Preparando o contexto
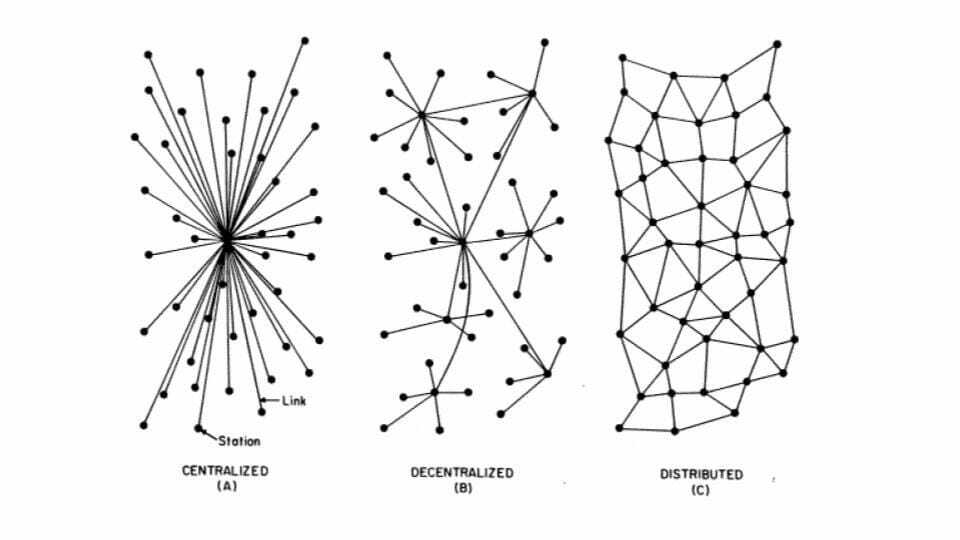
Não é nenhum segredo que atualmente eu estou fascinado pelo p2p, tecnologias distribuídas, e seus futuros (e não apenas o futuro) impactos na arquitetura da internet e da sociedade em geral. Um dia eu estava pensando em como funcionaria implantar uma rede p2p para orquestrar em produção todos os dispositivos de uma federação de data center quando percebi algo: as infraestruturas do data center são altamente monitoradas para detectar qualquer desvio mínimo da operação de linha de base do sistema. Em infraestruturas tradicionais (e centralizadas) a analítica é “simples”, você pode ter um sistema de monitoramento central para coletar cada métrica de sua infraestrutura, porque você é o proprietário e gerente dela. Mas quando você tem um sistema descentralizado de propriedade de várias entidades onde você opera apenas uma pequena parte da rede, como você pode monitorar seu status geral e garantir que os sistemas estejam funcionando como deveriam? Você mantém apenas uma visão local da rede e deseja saber sobre o status de toda a rede. O monitoramento e a analítica em redes distribuídas, não estruturadas e auto-organizadas são difíceis, especialmente sem uma infraestrutura centralizada para orquestrar tudo. Então com a desculpa de me aprofundar em simultaneidade e libp2p (e acionado por algumas circunstâncias externas), decidi começar a explorar esse problema em uma pequena escala.
Contando os nós
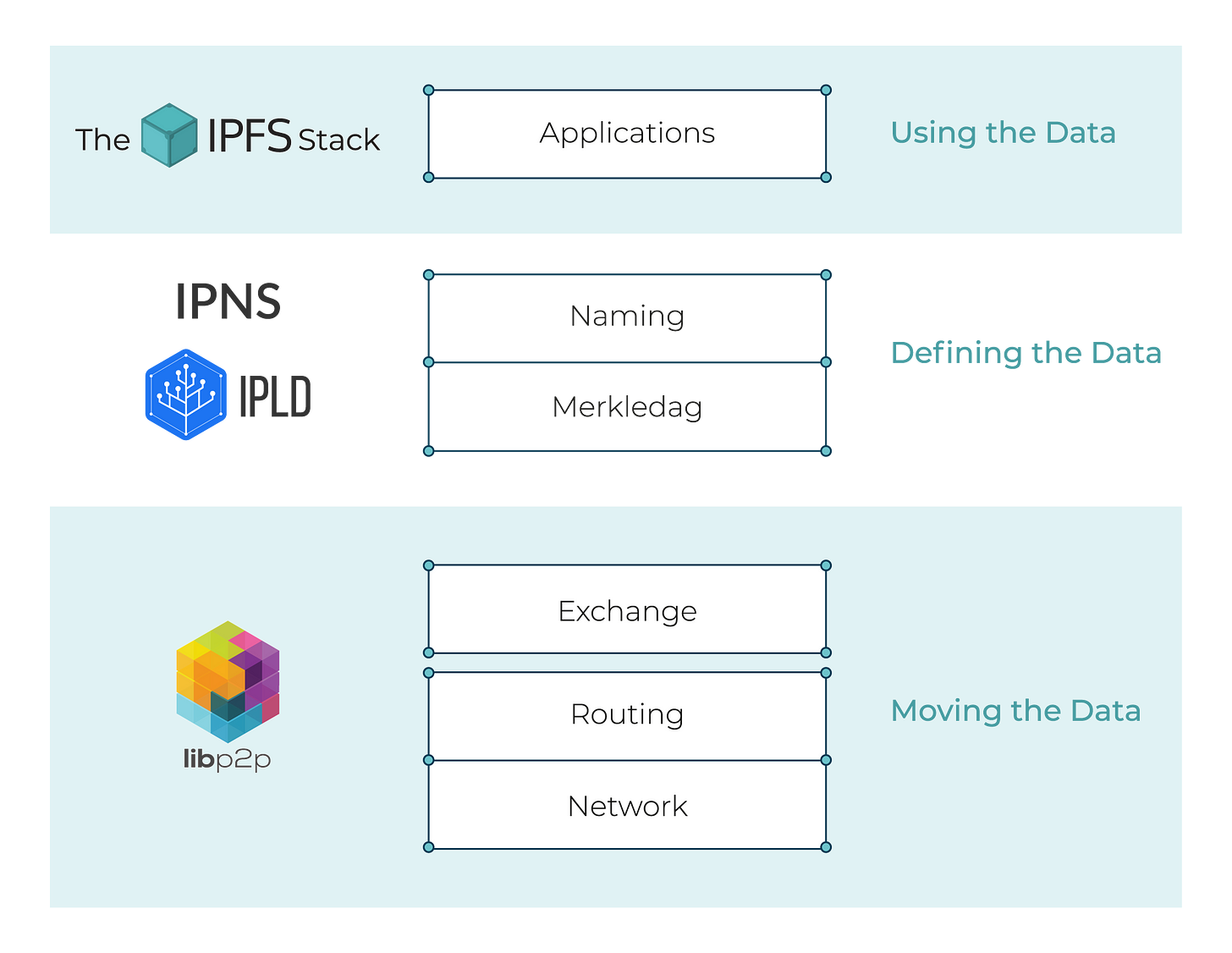
Eu escolhi começar pequeno, mas ambicioso. Eu queria explorar o problema em uma rede real, então configurar uma rede de 8 nós na minha máquina local para fins experimentais seria trapaça. Então decidi tentar coletar algumas métricas de uma das maiores redes p2p existentes, IPFS. Especificamente, eu tentaria monitorar o número total de nós ativos na rede e seu churn diário (uma proporção do número de nós que restaram ao longo do dia). Uma primeira pesquisa sobre o problema mostrou vários resultados de trabalhos acadêmicos tentando mapear a rede IPFS e implementações existentes de rastreadores de rede libp2p. Então, outros já haviam abordado esse problema antes. Bastando de introdução, peguei uma página em branco do meu caderno, comecei a rabiscar um possível design para minha ferramenta, e acabei com a seguinte arquitetura para meu rastreador: • O crawler seria formado por três processos distintos: o processo crawler (encarregado de percorrer aleatoriamente o DHT em busca de nós conectados —mais sobre isso daqui a pouco—); o processo de vivacidade (responsável por verificar se os nós já vistos ainda estão vivos); e o processo de relatório (exibindo o estado atual da análise, nada extravagante). • Para rastrear a rede, escolhi um esquema bastante desestruturado, um passeio aleatório do roteamento DHT. Os crawlers escolheriam um ID de nó aleatório e perguntariam à rede “ei, pessoal! dê-me uma lista dos x nós mais próximos a este pessoal ”. O rastreador tentaria então fazer uma conexão efêmera com esses nós para ver se eles estão ativos e, se eles estão, adicioná-los à lista de nós ativos na rede. Dessa forma, percorremos aleatoriamente a rede em busca de nós ativos. Talvez eu pudesse ter usado uma pesquisa mais estruturada onde, em vez de escolher um novo ID de nó aleatoriamente, peguei todos os pares dos meus k-buckets, olhar se eles estavam vivos, solicitei uma lista de pares dos k-buckets para esses nós recursivamente e etc . Minha primeira implementação seguiu esse esquema. Pode ter acabado sendo mais preciso, mas parecia mais lento do que a abordagem aleatória. • O passeio aleatório procurou por nós ativos na rede, mas eu precisava de uma maneira de verificar se esses nós ainda estavam vivos ou se eles haviam saído da rede. Este é o propósito do processo de vivacidade. Esse processo é muito simples, enquanto o crawler pesquisa e atualiza a lista de nós ativos, esse processo percorre a lista de nós ativos e tenta fazer conexões efêmeras com eles para ver se ainda estão vivos. • Por fim, o processo de geração de relatórios apenas pega as métricas armazenadas e as exibe periodicamente. Inicialmente, as únicas métricas que coleto dos nós vistos são: o momento em que foi visto pela última vez e se está atrás de um NAT ou não. Esta última métrica é muito importante para verificar se um nó ainda está vivo, pois mesmo que a conexão efêmera falhe pode ser porque ele está atrás de um NAT e não porque está fora. Então é por isso que precisamos saber de antemão se o nó está por trás de um NAT para saber como identificar os nós de saída.
Mostre-me o código!
Você pode achar o código para a ferramenta neste repositório. O arquivo README inclui algumas informações sobre a decisão de design e a implementação, mas se você está apenas curioso para ver a ferramenta funcionando, você pode clonar o repositório, compilar o código e executá-lo para ver a mágica acontecer:
$ git clone https://github.com/adlrocha/go-libp2p-crawler
$ go build
$ ./go-libp2p-crawler -crawler=<num_workers> -liveliness=<num_liveliness> -verbose
Os sinalizadores -crawler e -liveliness permitem que você escolha o número de goroutines dedicadas a pesquisar novos nós e verificar se os nós ainda estão vivos, respectivamente. Para aqueles que desejam saber um pouco mais sobre como implementei essa ferramenta, deixe-me orientá-lo em sua implementação: • A primeira coisa que o sistema faz ao inicializar é iniciar um novo nó libp2p para cada processo do crawler que deseja ser inicializado. Esses nós se conectam aos nós de bootstrap do IPFS. Quando um nó é inicializado, ele começa a procurar novos nós. • Um nó pode executar apenas o processo de crawler ou pode executar o processo de rastreador e de vivacidade simultaneamente de acordo com o número de crawlers e de vivacidade escolhidos para a execução (lembre-se de que os nós de rastreador são projetados para que não possam executar apenas verificações de vivacidade, para que você nunca tenha mais trabalhadores de vivacidade do que trabalhadores de crawler. Esta é uma escolha de design e pode ser facilmente modificada). • Para armazenar os dados sobre nós vistos, nós ativos na rede, etc. Optei por usar o LevelDB. O sistema tem várias goroutines escrevendo no mesmo armazenamento de dados, então usar o LevelDB foi uma maneira bastante direta de evitar data races. Após alguns testes iniciais, também optei por usar bloqueios para remover explicitamente quaisquer possíveis data races. • O processo de relatório mostra apenas informações sobre o número de nós vistos e que saíram hoje, o número de nós ativos na rede (pelo menos nossa visão dela) e o churn diário. Também estou armazenando informações sobre quando o nó foi visto pela última vez e se ele está atrás de um NAT para que eu também possa calcular a taxa de nós atrás de um NAT ou uma estimativa aproximada do tempo médio em que um nó permanece conectado. Também pensei em explorar outras métricas como o RTT médio com o resto da rede, os transportes disponíveis nos nós vistos, e outras métricas interessantes sobre a rede, mas optei por focar em métricas simples no momento (crawling foi difícil suficiente para valer a pena o esforço).
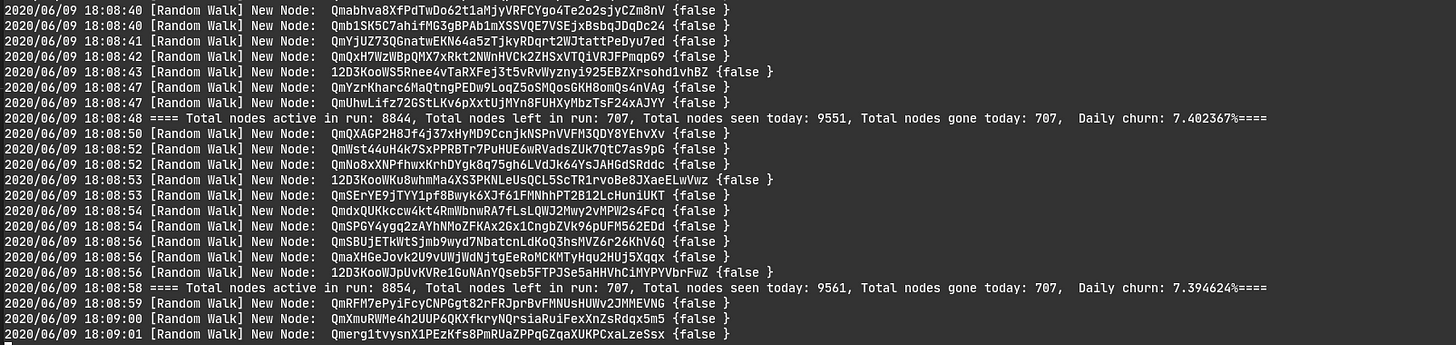
Exemplo de execução da ferramenta
Após longas execuções da ferramenta, comecei a perceber como o número total de nós que deixavam a rede estava sendo reiniciado ao atingir ~ 500. Esse bug realmente mexeu comigo, fiz vários testes isolados aos contadores, a todas as goroutines e forma independente, até que optei por fazer uma implementação alternativa sem LevelDB (que você encontra no branch feature/noLevelDB do repo). Com essa implementação alternativa o problema foi resolvido e, você sabe o que estava acontecendo? A estrutura que usei para armazenar os dados e o fato de que no processo de vivacidade eu tive que usar um iterador para fazer um loop pelos dados estava atrapalhando a sincronização. Eu estava contabilizando nós adicionais e reiniciando contadores quando não deveria. Outra razão pela qual optei por usar o LevelDB foi para persistir a lista de nodes vistos, mas devido ao bug, e considerando que eu poderia usar outros esquemas menos complexos para persistir os dados, não investi mais tempo tentando consertar o bug para este post (embora seja algo que definitivamente farei quando encontrar tempo).
Concluindo!
Para ser honesto, eu tive o melhor momento da minha vida brincando com esse projeto. Eu já disse isso algumas vezes neste boletim, mas deixe-me fazer mais uma vez, eu gostaria de poder fazer disso meu trabalho em tempo integral! Eu adoraria saber o seu feedback se você testar a ferramenta. De acordo com seu feedback, talvez faça sentido aumentar o projeto e mantê-lo ativamente. Enquanto isso, depois de me aprofundar um pouco na libp2p, tive mais algumas ideias para explorar e já comecei um novo “projeto rápido e sujo” para aprender algo novo. O próximo combina WASM, libp2p e Rust. Fique atento para ver os resultados (dependendo da minha disponibilidade nas próximas semanas posso publicar os resultados em um mês ou mais). Te vejo em breve!