
Criar seu avatar pessoal com IA pode ser uma maneira divertida e emocionante de explorar os recursos de tecnologias de IA de ponta. Um avatar de IA é uma representação digital de uma pessoa criada usando ferramentas e técnicas de inteligência artificial (IA). Pode assumir várias formas, como um modelo 3D, um personagem animado ou um assistente virtual. Os avatares criados com IA estão se tornando cada vez mais populares em áreas como jogos, entretenimento, assistentes virtuais e mídias sociais.
As possíveis razões pelas quais podemos criar um avatar com IA incluem:
Jogos: Poderíamos criar um avatar para representar o usuário em um videogame, proporcionando ao usuário uma experiência de jogo mais personalizada.
Mídia social: um avatar de IA pode servir como uma imagem de perfil única e atraente nas plataformas de mídia social.
Assistentes virtuais: poderíamos criar um avatar para servir como assistente virtual, que poderia responder aos comandos de voz e ajudar o usuário em tarefas como agendar compromissos ou suporte ao cliente.
Neste artigo, percorreremos o processo de criação de um avatar pessoal com IA usando ferramentas de IA de última geração, como Stable Diffusion, ChatGPT, ElevenLabs e D-ID. Posteriormente, também examinaremos os modelos de dados e estruturas de classes necessários para criar um sistema de chatbot animado, e como a entrada do usuário é processada e classificada para gerar respostas adequadas.
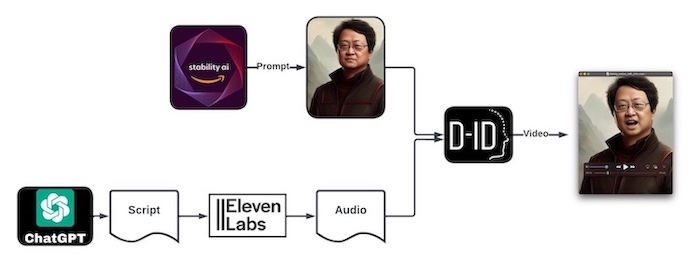
Figura. Ilustração do fluxo de trabalho de criação do avatar animado com IA. (1) Geração da imagem do avatar usando Stable Diffusion (2) Geração de texto usando ChatGPT (3) Geração de uma voz usando ElevenLabs (4) Combinação da imagem do seu avatar e da voz gerada usando D-ID.
Por exemplo, Veja meu avatar de IA pessoal em ação: Demonstração do Avatar Pessoal Animado com IA.
Figura. Demonstração de um avatar animado com IA pessoal.
Para aprender como treinar um modelo pessoal para o Stable Diffusion, leia nossos posts anteriores sobre os tópicos:
Etapa 1: Gerando uma imagem de avatar usando Stable Diffusion
Stable Diffusion é uma ferramenta de IA de ponta que pode ser usada para gerar imagens de faces de alta qualidade. Para usar o Stable Diffusion, você precisa fornecer alguns parâmetros iniciais, como sexo, idade e penteado, e isso gerará uma imagem realista de um rosto que corresponda a esses parâmetros.
Para gerar sua imagem pessoal de avatar, comece construindo uma incorporação pessoal descrita em nossa postagem anterior em Dreambooth Training for Personal Embedding. Você pode escolher qualquer combinação de parâmetros que desejar, dependendo do tipo de avatar que deseja criar. Após escolher seus parâmetros, execute o Stable Diffusion para gerar sua imagem de avatar.
Prompt: a pessoa bennycheung é o símbolo do nosso modelo de incorporação pessoal
Benny Cheung como um personagem de fantasia, ultra realista, intrincado, elegante,
altamente detalhado, em resolução 8K, pintura digital, plano de fundo detalhado, em alta tendência no ArtStation,
suave, foco nítido, ilustração, no estilo de wlop, greg rutkowski.
Prompt negativo: é isso mesmo, precisamos dizer muito bem ao Stable Diffusion o quê NÃO fazer!
(((Ruga))), pão, chapéu, desfigurado, brega, feio, supersaturado, grão,
baixa resolução, deformado, embaçado, anatomia ruim, rosto desfigurado, mutação,
mutado, membro extra, feio, mãos mal desenhadas, membro ausente, borrado, membros flutuantes,
membros desconectados, mãos malformadas, borrão, fora de foco, pescoço longo, corpo longo, feio,
nojento, mal desenhado, infantil, mutilado, desfigurado, velho, surreal, texto, borrado,
preto e branco, monocromático, gêmeos siameses, múltiplas cabeças, pernas extras,
braços extras, fotos de moda (colagem: 1.25), meme, deformado, alongado, retorcido, dedos,
estrabismo, heterocromia, olhos fechados, borrado, marca d'água, casamento, grupo.
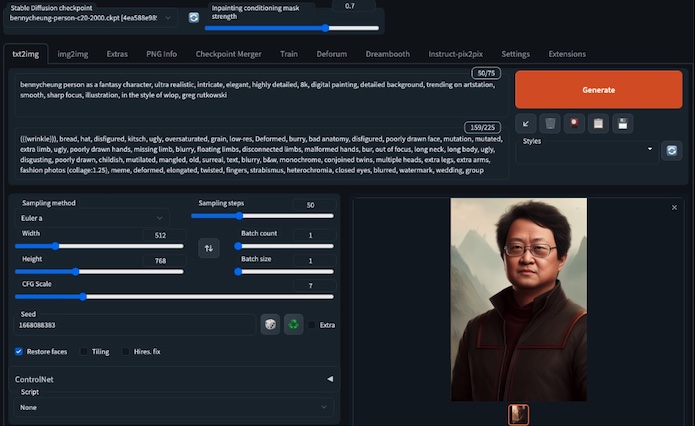
Figura. Use o Stable Diffusion (via interface do usuário da Web AUTOMATIC1111 ) para gerar a imagem do avatar a partir de um prompt.
Etapa 2: Gerando texto usando o ChatGPT
O ChatGPT é uma poderosa ferramenta de processamento de linguagem natural (NLP - natural language processing , no original) que pode ser usada para gerar texto com base em um determinado prompt. Para usar o ChatGPT, você precisa fornecer um prompt e ele gerará um pedaço de texto que segue esse prompt.
Para gerar o script para o seu avatar de IA, comece escolhendo um prompt que o ajudará a criar o tipo de diálogo que você deseja que seu avatar tenha. Por exemplo, você pode escolher um prompt como “Apresente-se” ou “Conte-me sobre seus interesses”. Após escolher seu prompt, execute o ChatGPT para gerar o script.
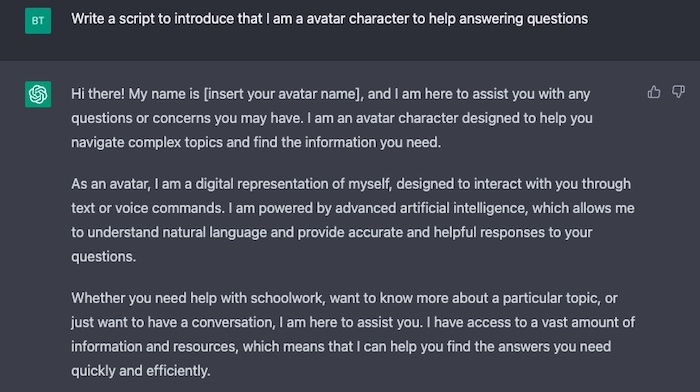
Figura. Use o ChatGTP para escrever um script para o discurso do avatar.
Etapa 3: gerar uma voz usando o ElevenLabs
O ElevenLabs é uma ferramenta de IA de ponta que pode ser usada para gerar vozes realistas com base em um determinado texto. Para usar o ElevenLabs, precisamos fornecer um script de texto e ele gerará uma voz que fale o texto de maneira natural e realista. Podemos contar com o ElevenLabs utilizando alguns créditos gratuitos para começar.
Para gerar a voz do seu avatar de IA, comece fornecendo ao ElevenLabs o script que geramos usando o ChatGPT. O ElevenLabs usará técnicas avançadas de aprendizado profundo para gerar uma voz que corresponda ao script.
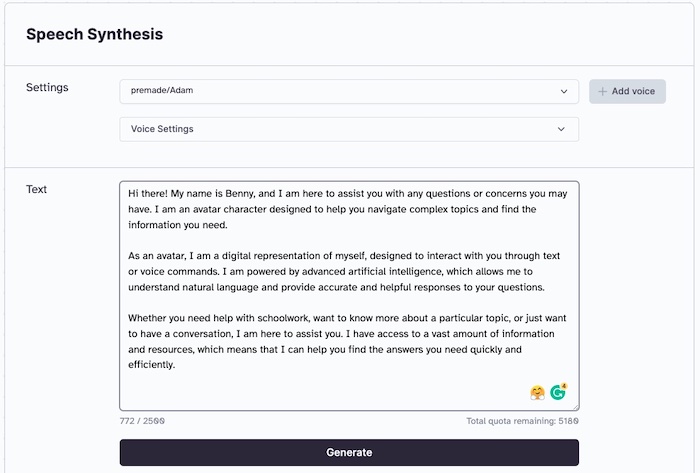
Figura. Use ElevenLabs para definir a voz e o script de entrada, para gerar um arquivo de áudio MP3
Processo de geração de voz explicado
O processo de geração de uma voz realista envolve várias etapas técnicas:
Etapa 1: análise de texto - O texto de entrada é analisado pela primeira vez usando algoritmos de processamento de linguagem natural ( NLP ) para extrair recursos importantes, como sintaxe, semântica e prosódia. Essa análise ajuda a entender a estrutura e o conteúdo do texto, incluindo o tom, o estilo e a emoção pretendida.
Etapa 2: modelagem acústica - Depois que o texto de entrada é analisado, o ElevenLabs usa técnicas de aprendizado profundo para treinar um modelo acústico com base no texto. O modelo acústico é uma rede neural que aprende a mapear o texto para os recursos acústicos correspondentes da fala, como tom, volume e duração.
Etapa 3: síntese de voz - Após treinar o modelo acústico, o ElevenLabs usa um algoritmo de síntese para gerar a forma de onda de voz correspondente. O algoritmo de síntese usa o modelo acústico para gerar uma sequência de recursos acústicos, convertidos em uma forma de onda contínua usando um vocoder. O vocoder é uma rede neural que converte os recursos acústicos em um sinal de áudio de alta qualidade que se assemelha muito à fala humana natural.
Etapa 4: pós-processamento - Finalmente, o ElevenLabs aplica técnicas de pós-processamento para melhorar ainda mais a qualidade e a naturalidade da voz gerada. Essas técnicas podem incluir filtragem, redução de ruído e mudança de afinação, entre outras.
O ElevenLabs usa uma combinação de algoritmos avançados de NLP, técnicas de aprendizado profundo e processamento de sinais para gerar vozes realistas e de alta qualidade a partir do texto de entrada. Essa ferramenta possui uma ampla gama de aplicativos, incluindo assistentes virtuais, narração de audiolivros, narrações para vídeos e muito mais.
Etapa 4: Combinando a imagem do seu avatar e a voz gerada usando D-ID.
D-ID é uma sofisticada ferramenta de IA que pode ser usada para combinar uma imagem com uma voz para criar um vídeo realista de uma pessoa falando. Para usar o D-ID, precisamos fornecer uma imagem e uma voz, e isso gerará um vídeo da pessoa na imagem falando com a voz dada. Podemos contar com o D-ID utilizando alguns créditos gratuitos para começar.
Para criar um avatar pessoal da IA, comece fornecendo D-ID com sua imagem pessoal do avatar e a voz que geramos usando o ElevenLabs. O D-ID usará técnicas avançadas de visão computacional e NLP para criar um vídeo do nosso avatar de IA falando com uma voz realista.
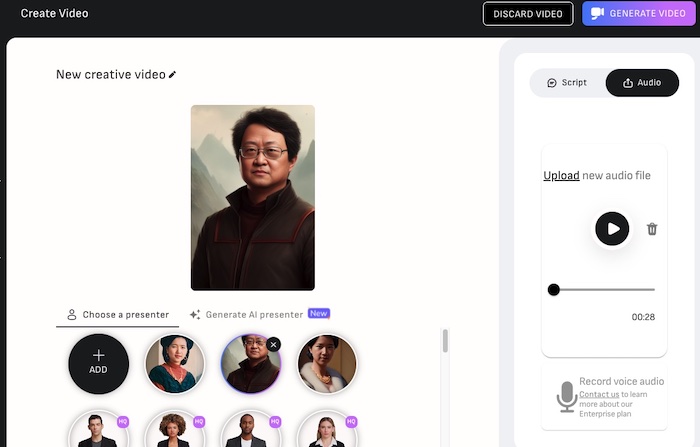
Figura. Use o D-ID para fazer upload do arquivo de áudio gerado e adicione a imagem de avatar personalizada para gerar vídeo
Processo de geração de vídeo explicado
O processo de combinação de uma imagem com uma voz para criar um vídeo realista envolve várias etapas técnicas:
Etapa 1: detecção e alinhamento do rosto - O D-ID primeiro detecta o rosto na imagem de entrada e o alinha com uma posição neutra. A ferramenta usa algoritmos de detecção de pontos faciais para identificar e localizar com precisão os principais recursos faciais, como olhos, nariz e boca, essenciais para gerar movimentos faciais realistas durante a fala.
Etapa 2: sincronização labial - Depois que o rosto está alinhado, o D-ID gera movimentos labiais realistas para sincronizar com a voz dada. A ferramenta usa uma combinação de técnicas de aprendizado profundo e algoritmos de visão computacional para analisar a voz e gerar movimentos labiais correspondentes que combinam com o somo som.
Etapa 3: geração de expressão facial - O D-ID também gera expressões faciais realistas com base na voz de entrada. Ele usa algoritmos de NLP para analisar o conteúdo da fala e gerar expressões emocionais correspondentes, como sorrir, franzir a testa ou levantar as sobrancelhas, consistentes com o conteúdo da fala.
Etapa 4: renderização de vídeo - Finalmente, o D-ID combina todos os elementos gerados, como movimentos labiais, expressões faciais e voz, para criar um vídeo realista da pessoa que fala. A ferramenta usa técnicas avançadas de computação gráfica para renderizar o vídeo com visuais de alta qualidade e sincronização labial perfeita.
O D-ID usa uma combinação de algoritmos e técnicas sofisticados de IA para gerar vídeos realistas de pessoas falando com base em imagens e vozes. A ferramenta pode ser usada para uma ampla gama de aplicativos, como criar mensagens de vídeo personalizadas, gerar avatares para assistentes virtuais ou aprimorar as experiências de videoconferência.
Design de Chat Bot Animado
Se queremos projetar um Chat Bot que combine as técnicas de geração de um avatar e uma voz para interagir com os usuários, pode ser alcançado através de um design de sistema que inclui os seguintes componentes:
Interface do usuário: O primeiro componente do design do sistema é a interface do usuário, que permite aos usuários interagirem com o Chat Bot. Isso pode ser na forma de um aplicativo da Web ou aplicativo de celularl ou mesmo de um widget de bate-papo incorporado em um site. Os usuários podem inserir mensagens de texto ou comandos de voz através da interface do usuário, à qual o Chat Bot processará e responderá.
Processamento de linguagem natural (NLP): O segundo componente do design do sistema é o processamento de linguagem natural, usado para entender as mensagens de entrada do usuário. O componente NLP usará técnicas como análise de texto, análise de sentimentos e reconhecimento de intenções para entender o significado por trás da entrada do usuário.
Geração de Avatar: O terceiro componente do design do sistema é a geração de avatar, que usa uma ferramenta como o Stable Diffusion para criar uma imagem realista do Chat Bot. O avatar pode ser personalizado para se ajustar à marca ou personalidade do Chat Bot e pode até incluir expressões faciais e movimentos labiais gerados pelo D-ID.
Geração de voz: O quarto componente do design do sistema é a geração de voz, que usa o ElevenLabs para gerar uma voz realista para o Chat Bot. A voz pode ser personalizada para se ajustar à marca ou personalidade do Chat Bot e pode até incluir tons emocionais e inflexões com base no texto de entrada.
Gerenciamento de Diálogo: O quinto componente do design do sistema é o gerenciamento de diálogo, responsável pelo gerenciamento do fluxo da conversa entre o usuário e o Chat Bot. Esse componente usa uma ferramenta como o ChatGPT para gerar respostas com base na entrada do usuário e no contexto atual da conversa.
Integração e Implantação: O componente final do design do sistema é a integração e implantação do Chat Bot. Isso inclui integrar todos os componentes em um sistema coeso, testar e validar o Chat Bot e implantá-lo em um ambiente de produção.
O design do sistema para um Chat Bot que combina geração de avatar e voz incluiria componentes para interface do usuário, NLP, geração de avatar e voz, gerenciamento de diálogo e integração e implantação. A combinação desses componentes criará uma experiência altamente personalizada e envolvente para os usuários, aprimorando a experiência e a satisfação gerais do usuário.
Chat Bot animado
Para promover o recurso Chat Bot que usa um avatar animado para fornecer a resposta, funcionará de maneira semelhante a um ChatBot baseado em texto (ou apenas de voz)t, mas com o elemento adicionado de uma representação visual animada do Chat Bot.
Quando o usuário digita uma mensagem ou comando, o Chat Bot usa o processamento de linguagem natural (NLP) para entender a intenção do usuário e gerar uma resposta apropriada. A resposta será traduzida em texto, que será usado como base para gerar uma resposta animada do avatar do Chat Bot.
Para conseguir isso, o Chat Bot usará uma ferramenta de geração de avatar como Stable Diffusion para criar uma imagem animada realista do Chat Bot. O avatar pode ser personalizado para corresponder à marca ou personalidade do Chat Bot e pode incluir uma variedade de expressões faciais, movimentos e gestos.
Depois que o avatar for gerado, ele será integrado à interface do Chat Bot, que o usuário verá ao receber uma resposta. Os movimentos, gestos e expressões do avatar serão sincronizados com o texto de resposta gerado pelo Chat Bot, criando uma experiência mais envolvente e personalizada para o usuário.
Projeto do sistema
Na interface do usuário, a mensagem ou comando seria passado para o componente de processamento de linguagem natural (NLP), que analisaria a entrada para entender a intenção do usuário e gerar uma resposta. A resposta gerada pelo componente NLP será passada para o componente de geração de avatar, que criará uma imagem animada do Chat Bot em resposta à mensagem ou comando do usuário.
Simultaneamente, o texto de resposta gerado pelo componente NLP será passado para o componente de geração de voz, que usará o ElevenLabs para gerar uma resposta de voz do Chat Bot. As respostas de avatar e voz serão devolvidas à interface do usuário, onde o usuário poderá ver e ouvir a resposta do Chat Bot.
O componente de gerenciamento de diálogo seria responsável por gerenciar o fluxo da conversa, garantindo que as respostas do Chat Bot sejam apropriadas e relevantes para o contexto atual. Por fim, todo o sistema seria integrado e implantado em um ambiente de produção, onde poderia interagir com os usuários em tempo real.
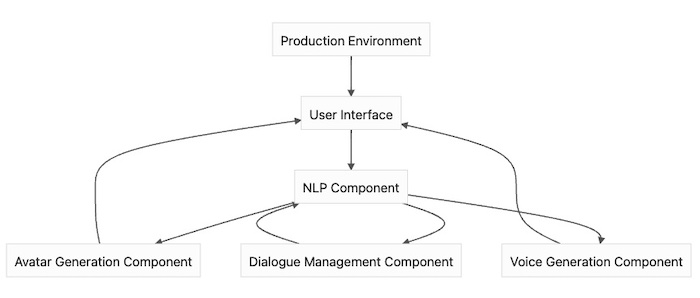
Figura. Neste diagrama, a interface do usuário (A) é conectada ao componente NLP ( B ), que, por sua vez, está conectado ao componente de geração de avatar ( C ) e ao componente de geração de voz ( D ). O componente de geração de avatar e o componente de geração de voz enviam sua saída de volta à interface do usuário, e o componente de gerenciamento de diálogo ( E ) é responsável por gerenciar o fluxo da conversa entre os componentes. Finalmente, todo o sistema é integrado e implantado em um ambiente de produção ( F ).
Modelo de dados do sistema
O modelo de dados do sistema pode ser resumido na tabela a seguir,
| Modelo de dados | Descrição |
| Entrada do usuário | A mensagem ou comando digitado pelo usuário |
| Pré-processamento de texto | O componente NLP processa a entrada do usuário removendo palavras vazias , radicalizações ou lematizações |
| Classificação de Intenção | O componente NLP classifica a entrada do usuário em uma ou mais categorias de intenção |
| Estado de Diálogo | O estado atual da conversa, incluindo contexto e histórico |
| Postura de Avatar | A postura atual do avatar, refletindo suas emoções e estado físico |
| Resposta do Diálogo | A resposta gerada pelo Chatbot para responder à solicitação do usuário |
| Saída de voz | A resposta de áudio gerada pelo componente de geração de voz com base na resposta do diálogo |
| Expressão Facial | A expressão facial do avatar, refletindo suas emoções e tom de voz |
| Sincronização labial | A sincronização entre a saída de voz e os movimentos labiais do avatar |
| Resposta | A resposta final do Chatbot, que inclui a pose ou postura do avatar e a saída de voz |
Este modelo de dados do sistema representa os vários componentes e estruturas de dados envolvidos na criação e geração de respostas de um Chatbot. A entrada do usuário é o ponto de partida da interação e é processada pelo componente de pré-processamento de texto, que aplica várias técnicas de NLP à entrada para facilitar a análise.
O componente Classificação de Intenção classifica a entrada do usuário em uma ou mais categorias de intenção, usadas para determinar a resposta apropriada. O componente Estado do Diálogo armazena o estado atual da conversa, incluindo contexto e histórico, e é atualizado a cada nova entrada do usuário.
O componente Postura do Avatar armazena a pose atual do avatar, refletindo suas emoções e estado físico. O componente Expressão Facial usa essas informações para gerar uma expressão facial que corresponda ao tom e à emoção da saída de voz.
O componente Resposta ao Diálogo gera a resposta à entrada do usuário, passada para o componente Saída de voz. Esse componente gera a resposta de áudio com base na resposta de diálogo, sincronizada com o componente Sincronização Labial para garantir que os movimentos labiais do avatar correspondam ao áudio.
Por fim, o componente Resposta combina a saída do Postura do Avatar e Saída de Voz para criar a resposta final exibida ao usuário. Juntos, esses componentes e estruturas de dados criam uma experiência de conversação que é envolvente e responde às necessidades do usuário.
Design de classe
Aqui está um exemplo das estruturas de dados de classe para cada modelo de dados dos componentes que podem ter um layout como:
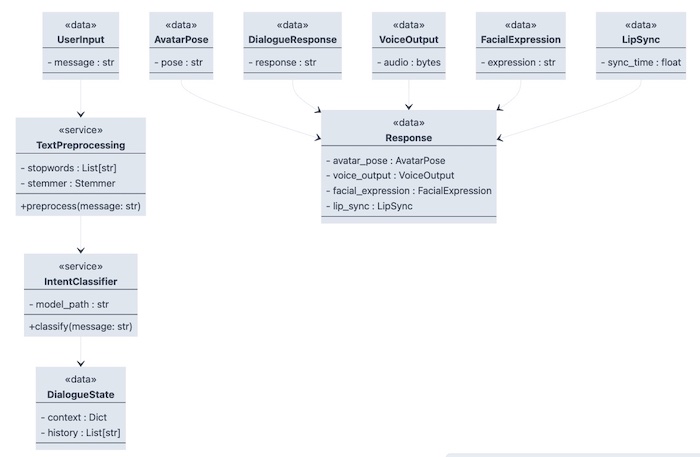
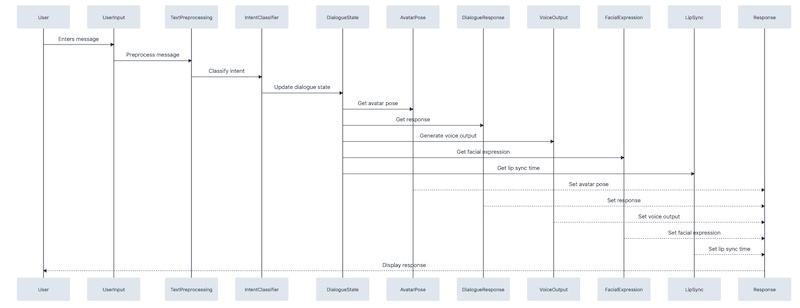
Aqui está um exemplo de diagrama de sequência que mostra como a entrada do usuário afetaria as classes mencionadas acima:
Observações finais
Neste artigo, exploramos o emocionante mundo dos avatares e chatbots da IA. Discutimos como ferramentas e técnicas de IA de ponta, como Stable Diffusion, ChatGPT, ElevenLabs e D-ID, podem ser usadas para criar um avatar de IA realista e interativo. Exploramos os detalhes técnicos de como essas ferramentas e componentes funcionam juntos para criar uma experiência de conversação atraente para os usuários.
Também analisamos os modelos de dados e as estruturas de classes envolvidas na criação de um sistema de chatbot animado e como a entrada do usuário é processada e classificada para gerar respostas apropriadas. Examinamos os vários componentes envolvidos na geração da expressão facial e sincronização labial do avatar, bem como a saída de voz sincronizada com os movimentos do avatar.
Vimos que os avatares e chatbots da IA têm um enorme potencial para revolucionar a maneira como interagimos com a tecnologia. Com os avanços na tecnologia de IA, podemos criar avatares mais realistas e envolventes que podem aprimorar a experiência do usuário e fornecer novas maneiras de se conectar com outras pessoas. As possibilidades são infinitas e podemos esperar desenvolvimentos ainda mais emocionantes nesse campo nos próximos anos.
Referências
Prompt Engineering, Create Your Own AI Animated Avatar: A Step-by-Step Guide, Youtube, Feb 2023
aprendemos como criar avatar de IA com ferramentas e técnicas de IA de ponta aqui. O avatar da IA foi criado usando MidJourney, ChatGPT, ElevenLabs e D-ID.
Outras postagens de blogs
Benny Cheung, Stable Diffusion Training for Personal Embedding, Benny’s Mind Hack, Nov 2022.
Benny Cheung, Dreambooth Training for Personal Embedding, Benny’s Mind Hack, Nov 2022.
Ferramentas IA
ChatGPT para criação de scripts: ChatGPT
Stable Diffusion para geração de imagem usando Automatic1111: Stable Diffusion
Elevenlabs para geração de áudio: Elevenlabs
D-ID para geração de vídeo: D-ID
Este artigo foi escrito por Benny Cheung e traduzido por Adriano P. de Araujo. O original em inglês pode ser encontrado aqui.