
Esse artigo é uma tradução de (Freddy Coen) feita por (Diogo Jorge). Você pode encontrar o artigo original aqui. (https://freddycoen.medium.com/evm-starter-kit-1790bcc992ef).
Nota: Esta postagem está dividida em duas partes. A Parte 1 vai cobrir o básico da EVM e é um pré-requisito para a Parte 2, na qual nós vamos desmistificar o bytecode do smart contract compilado. Para entender as interações entre a stack, memória e armazenamento e escrever códigos mais eficientes, nós vamos fazer um passo a passo através da execução de duas transações completas.
Você, muito provavelmente, já ouviu falar sobre Web3, mas em seu sentido amplo, o que ela é? Em termos simples, a Web3 adiciona à internet uma camada descentralizada de estado confiável, abrindo a porta para uma grande variedade de inovações empoderadoras. Além disso, esse estado de camada não só armazena dados como também programas que podem ser executados confiavelmente e modificar o estado. A infraestrutura mais popular da Web3 é potencializada pela Máquina Virtual da Ethereum (EVM). O conceito da EVM origina-se do yellow paper da Ethereum, e é uma implantação de seus códigos operacionais. Este artigo vai introduzir o básico da EVM assim como oferecer um exemplo prático detalhado sobre como o bytecode compilado é executado no nível mais baixo. Qualquer feedback é muito apreciado:)
Parte 1: O Básico da EVM
Primeiro de tudo, porque uma máquina virtual? Quando falamos de redes descentralizadas como a Ethereum, é importante que você consiga executar um programa independentemente do sistema operacional ou da arquitetura de hardware de uma máquina individual. Do mesmo modo que o JVM permite que você rode programas em JAVA em qualquer máquina, a EVM permite que você rode o bytecode da EVM em qualquer máquina. (Em outras palavras, o bytecode resultante desses programas não tem que variar dependendo da arquitetura subjacente como arm ou x86, da máquina específica, a VM abstrai o hardware).
A EVM é uma máquina virtual que implementa os opcodes definidos no yellow paper da Ethereum. Ela oferece acesso a armazenamento persistente e um processador baseado em stack que é limitado a palavras de tamanho de 1024 256-bit. Diferente de linguagens como C ou C++, onde os tipos de valores são armazenados na stack e os tipos de referência no heap, a EVM não armazena nenhum valor na stack, mas os carrega da memória quando necessário.
Outro ponto importante a se notar é que a EVM está completamente isolada do sistema operacional, não tendo acesso ao sistema de arquivos ou outros processos para garantir que cada máquina na rede tenha resultados equivalentes para uma computação. Por último mas não menos importante, a EVM é baseada em contas, diferente do modelo UTXO do Bitcoin, que armazena o saldo do usuário através da soma de todos os recibos de transação. Isto simplesmente significa que os dados são mapeados em uma chave de conta. Existem dois tipos de contas: contas de proprietários externos (EOA’s) e contas de contratos. Contas externas são controladas por pares de chave público-privado e podem iniciar transições de estado ao enviar uma transação. Contas de contratos, por outro lado, são contas que armazenam um programa específico.
Antes de entrar em um exemplo prático, vamos passar pelo vocabulário de lugares onde a EVM pode acessar e armazenar informação.
A Máquina Virtual da Ethereum tem cinco áreas onde ela pode armazenar dados - stack, armazenamento, memória, calldata e logs os quais são explicados nos parágrafos seguintes.
Armazenamento
Armazenamento na EVM é persistente, o que significa que ele persiste entre as transações. O armazenamento é representado na forma de uma merkle patricia trie e vários clientes Ethereum usam diferentes implementações de base de dados para isso. Por exemplo, as implementações de cliente Python e Go da Ethereum usam leveldb para armazenar suas tentativas. Você pode já ter ouvido falar sobre esse termo chique “Merkle Patricia Trie” como parte da distribuição de airdrop da Uniswap, mas em essência ele permite duas coisas. Primeiro, ele nos permite verificar eficientemente a integridade dos dados, e segundo, ele nos permite verificar a inclusão de um pedaço de informação específico com apenas uma pequena amostra dos dados que formam a árvore. Estas são duas propriedades atrativas quando se fala de compartilhamento de dados em uma rede descentralizada.
A integridade do estado global é garantida por cada novo cabeçalho de bloco na forma de um estado raiz. Este estado raiz representa o nó raiz de uma merkle patricia trie composta de um mapeamento de chaves de conta de 160 bit que corresponde ao estado da conta, o que inclui um saldo da conta, um código hash, um nonce e uma raiz de armazenamento. A raiz de armazenamento é novamente um nó raiz de merkle patricia trie e armazena as variáveis de estado do contrato através de um mapeamento de palavras de 256-bit a palavras de 256-bit. Os pontos hash do código apontam ao código fonte do smart contract referido. Note que um EOA terá esses dois campos vazios como parte do estado da conta. Tenha em mente que a blockchain mesmo apenas armazena os blocos (incluindo um hash do estado raiz no cabeçalho), enquanto os clientes armazenam o conteúdo dos três inteiros em uma base de dados.
Memória Armazenamento temporário durante o tempo decorrido de execução de uma transação, pense nisso como uma RAM.
Calldata Os campos de dados de uma transação é uma memória de apenas leitura.
Logs Área de output de apenas inscrição para emitir Logs
Stack Armazena valores temporariamente durante o tempo decorrido para ser usado por operações. Qualquer operação leva palavras do stack de palavras empurradas para a pilha ou ambos. Ela serve como um mediador para ler, escrever e manipular os dados de armazenamento, memória, calldata ou os logs.
Parte 2: Entendendo seu código no nível mais baixo, um exemplo prático.
Solidity é a linguagem de alto nível mais popular para EVM e se beneficia de um rico ecossistema de ferramentas e suporte. Neste exemplo prático, nós vamos escrever um programa simples em Solidity e investigar como o bytecode compilado executa. Solidity é similar a outras linguagens orientadas ao objeto já que ela é baseada em classes chamadas contratos os quais quando deployed criam uma instância única daquela classe ao rodar a função construtora. O bytecode resultante desta instância (após a execução do construtor) é armazenada como o código de programa da respectiva conta de contrato (como parte do estado da conta, mencionado na seção de Armazenamento acima).
Para começar você pode tanto baixar os binários estáticos do compilador de solidity aqui, ou usar a versão JS do compilador solidity, o qual pode ser convenientemente usado dentro do seu projeto em javascript, ou dentro de um navegador com base IDE, como o Remix. De ambas as formas, a compilação vai gerar o bytecode de EVM resultante de seu programa juntamente com seu ABI (uma interface que diz a outras aplicações como interagir com seu contrato).
O bytecode da EVM é uma representação hexadecimal de uma sequência de códigos operacionais conhecidos como opcodes da EVM (uma lista completa de opcodes de EVM pode ser encontrada aqui). Cada opcode tem uma quantidade fixa de gas alocada e é uma medida do consumo de recursos. Neste exemplo prático nós vamos usar o Remix para escrever um contrato bem simples e ver como ele se traduz em uma série de códigos de operação que são executados pela EVM.
Abaixo temos um smart contract bem básico que nos permite perceber o que o bytecode gerado faz no deploy assim como quando a função é chamada posteriormente. O contrato Example tem um armazenamento público variável que recebe um valor de 1 pela função construtora no deploy. Ainda que simplista, analisar o bytecode desse smart contract vai ilustrar as interações básicas entre a stack, memória e armazenamento permitindo que você aplique a mesma metodologia em contratos mais complexos.
contract Example { uint256 public exampleNumber; constructor(){ exampleNumber = 1; } }
Rodando o compilador vai gerar o seguinte bytecode:
Nota: A parte do bytecode em deploy está em negrito, posteriormente falaremos mais sobre a diferença entre runtime (tempo de execução) bytecode e deployment bytecode _ “608060405234801561001057600080fd5b50600160008190555060b2806100276000396000f3fe6080604052348015600f57600080fd5b506004361060275760003560e01c80620511a014602c575b600080fd5b60326046565b604051603d91906059565b60405180910390f35b60005481565b6053816072565b82525050565b6000602082019050606c6000830184604c565b92915050565b600081905091905056fea2646970667358221220d6d4f6b7d89f1a77922be220ca2512cf050c8eb988d06ec97a32525e80f98ae464736f6c63430008070033”
O qual se traduz nos seguintes opcodes (você pode checar pessoalmente aqui):
“PUSH1 0x80 PUSH1 0x40 MSTORE CALLVALUE DUP1 ISZERO PUSH2 0x10 JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST POP PUSH1 0x1 PUSH1 0x0 DUP2 SWAP1 SSTORE POP PUSH1 0xB2 DUP1 PUSH2 0x27 PUSH1 0x0 CODECOPY PUSH1 0x0 RETURN INVALID PUSH1 0x80 PUSH1 0x40 MSTORE CALLVALUE DUP1 ISZERO PUSH1 0xF JUMPI PUSH1 0x0 DUP1 REVERT JUMPDEST POP PUSH1 0x4 CALLDATASIZE LT PUSH1 0x27 JUMPI PUSH1 0x0 CALLDATALOAD PUSH1 0xE0 SHR DUP1 PUSH3 0x511A0 EQ PUSH1 0x2C JUMPI JUMPDEST PUSH1 0x0 DUP1 REVERT JUMPDEST PUSH1 0x32 PUSH1 0x46 JUMP JUMPDEST PUSH1 0x40 MLOAD PUSH1 0x3D SWAP2 SWAP1 PUSH1 0x59 JUMP JUMPDEST PUSH1 0x40 MLOAD DUP1 SWAP2 SUB SWAP1 RETURN JUMPDEST PUSH1 0x0 SLOAD DUP2 JUMP JUMPDEST PUSH1 0x53 DUP2 PUSH1 0x72 JUMP JUMPDEST DUP3 MSTORE POP POP JUMP JUMPDEST PUSH1 0x0 PUSH1 0x20 DUP3 ADD SWAP1 POP PUSH1 0x6C PUSH1 0x0 DUP4 ADD DUP5 PUSH1 0x4C JUMP JUMPDEST SWAP3 SWAP2 POP POP JUMP JUMPDEST PUSH1 0x0 DUP2 SWAP1 POP SWAP2 SWAP1 POP JUMP INVALID LOG2 PUSH5 0x6970667358 0x22 SLT KECCAK256 0xD6 0xD4 0xF6 0xB7 0xD8 SWAP16 BYTE PUSH24 0x922BE220CA2512CF050C8EB988D06EC97A32525E80F98AE4 PUSH5 0x736F6C6343 STOP ADDMOD SMOD STOP CALLER “
Ele pode parecer intimidante mas realmente não é, uma vez que você passa por ele todo, opcode por opcode, o que faremos abaixo.
Uma vez que você vê como as coisas estão sendo executadas você vai ser capaz de pensar em formas de aplicar diferentes opcodes que consomem menos gas para atingir o mesmo fim. Para aprender os tipos e sintaxes de solidity você vai precisar de uma semana no máximo. Entretanto, se você quer entender profundamente e melhorar seu código, é bem útil entender o que acontece no nível mais baixo.
Como mencionado antes, o bytecode é uma representação hex dos opcodes da EVM que são documentadas no yellow paper. Quando é feito o deploy de um novo contrato, o bytecode é executado como parte da calldata. O bytecode inclui uma seção que é conhecida como a init section, a qual não é armazenada como parte do estado do código da conta do contrato, mas retorna o runtime bytecode dos contratos atuais e roda a função construtora, que no nosso caso determina um valor inicial para nossa variável de armazenamento público exampleNumber. A parte init do bytecode está em negrito acima. Para criar o contrato como parte do estado da blockchain, uma transação de deploy como qualquer outra tem que ser iniciada exceto que o endereço do recebedor esteja definido para estar vazio quando o campo de dados contém o bytecode compilado. Uma vez executada a transação uma conta é criada para aquele contrato e o bytecode é executado. Com isso em mente, vamos executar esse bytecode que é executado no deployment e desmistificar esta série de opcodes passando por cada um deles sequencialmente. Nós vamos passar por eles executando uma série de opcodes e visualizando a stack resultante. Quando não é mostrado nenhuma stack isso indica uma stack vazia, i.e todas as palavras saíram.
PUSH1 0x80 PUSH1 0x40 -> push 0x80 and 0x40 para dentro da stack

MSTORE -> armazena valor 0x80 no local 0x40 na memória e extravasa ambas palavras para fora do stack (este é um mostrador de memória grátis que vem com a solidity compilado como referência à primeira palavra não usada na memória e evita sobrescrever a memória que é usada internamente pela solidity)
CALLVALUE DUP1-> empurra para o topo do stack e duplica a quantidade de ether que foi especificada como o campo valor no deploy da transação usando o opcode DUP1
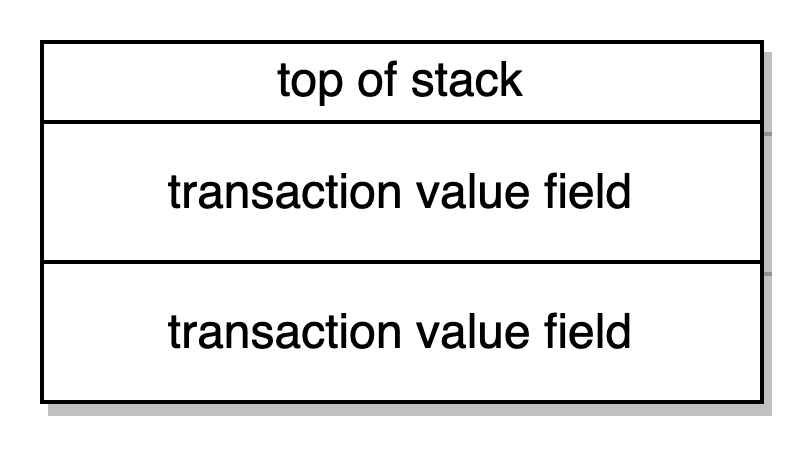
ISZERO-> checa se a palavra no topo da stack é zero e a retira. Se ela for zero ela envia 0x1 se não for, 0x0. No caso do nosso exemplo, vamos seguir o caminho de execução como se nós tivéssemos definido o campo do valor da nossa transação de deploy para 0. Assim, ISZERO retorna 0x1 no topo da stack.
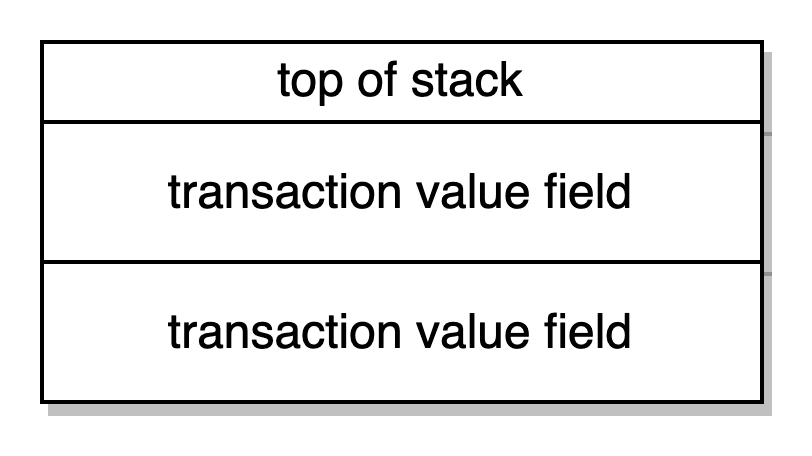
**PUSH2 0x10 **-> manda 2 bytes 0x0010 para dentro da stack JUMPI -> Salta para instrução com o contador do programa igual à palavra no topo da stack 0x0010 se a segunda palavra da stack é 0x1 (se o campo do valor da transação for 0), caso contrário, continua. Assim, em nosso caso nós saltamos para o contador 0x0010 do programa e continuamos a execução uma vez que o nossa transação de deployment definiu o campo valor como zero. Se nós tivéssemos definido o campo do valor como zero, nós não saltaríamos nesse ponto, mas continuaríamos a execução com PUSH1 0x0 DUP1 REVERT. Isto mandaria 0x0 para cima da stack, duplicaria aquela palavra e causaria uma reversão com as duas palavras de cima indicando a razão para a reversão.
Nota: tudo que vem acontecendo até agora foi para checar se o construtor era pagável e se o deploy da transação enviou algum ether com ele. Uma vez que o construtor não era pagável em nosso exampleContract, enviar ether com nossa transação de deploy deveria reverter o deploy. Por isso o salto condicional acima.
Contador 0x0010 do programa: JUMPDEST POP-> Destinos de salto válidos são indicados pelo opcode JUMPDEST. Uma vez que nós não enviamos ether com nossa transação de deploy, a execução init salta para este contador do programa e nós continuamos a execução enquanto retira uma palavra com o POP opcode, o que nos deixa com a stack vazia.
Nota: Desta parte em diante o construtor está sendo executado como parte do código init.
PUSH1 0x1 PUSH1 0x0 -> manda 0x01 para a stack (o valor que nós definimos para exampleNumber no construtor). Manda 0x0 para a stack (nós apenas temos uma variável de armazenamento, então será localizada no slot de armazenagem 0x0)
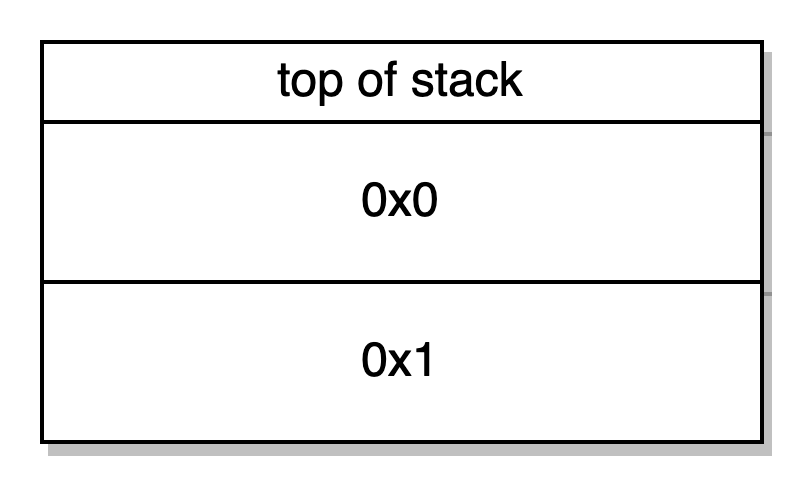
DUP2 SWAP1-> duplica a segunda palavra da stack e troca a primeira palavra pela segunda palavra
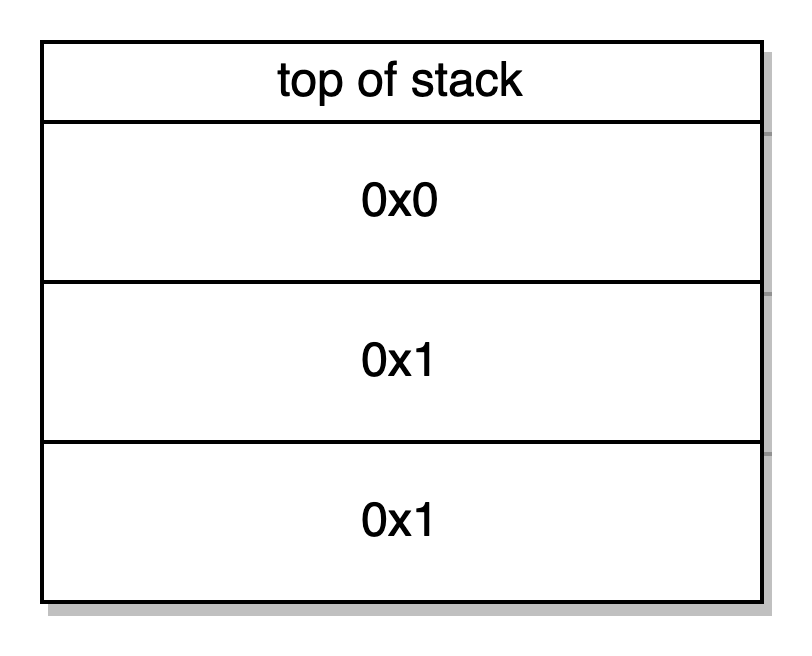
SSTORE -> armazena o valor da palavra de cima (0x1) dá o valor da segunda palavra (0x0) no slot de armazenagem, e retira ambas as palavras. O valor 1 está agora sendo armazenado no slot 0 o qual é o ponteiro da nossa variável exampleNumber.
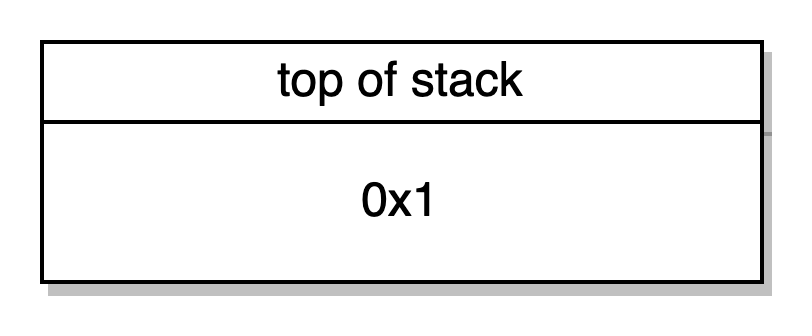
POP-> Remove o valor da stack, deixando-a vazia
Nota: Desta parte em diante, a cópia real do runtime bytecode começa e está retornando para nossa transação de deploy, a qual a armazena na seção código da conta do contrato recém gerado do estado global da blockchain.
PUSH1 0xB2 DUP1 PUSH2 0x27 PUSH1 0x0-> manda 0xB2 na stack, duplica-o, manda 0x27 e 0x0 na stack.
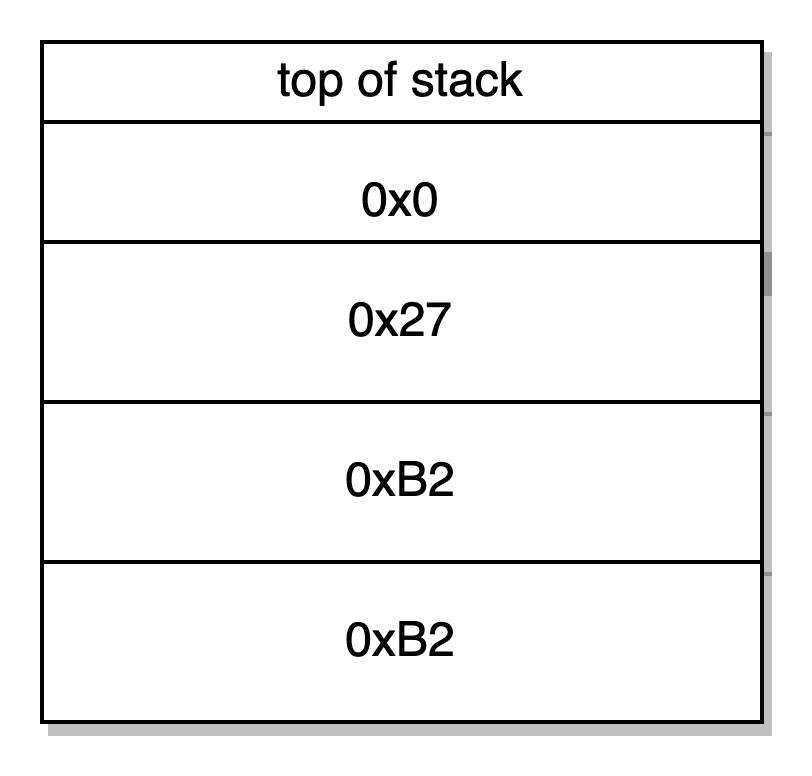
CODECOPY -> copia o código runtime para a memória usando a palavra do topo 0x0 como offset de memória para escrever o código, segunda palavra 0x27 como offset do bytecode para ler (isto é 39 em decimal, e se você olhar o bytecode você poderá ver que o código do runtime começa no 40o byte), e a terceira palavra 0xB2 como o comprimento em bytes para copiar (comprimento do runtime bytecode). As três palavras são retiradas da stack.
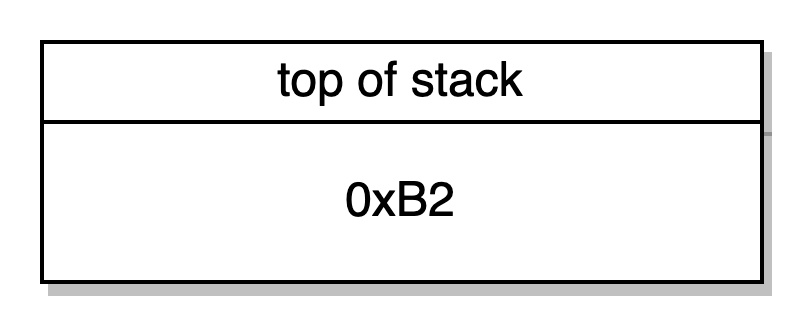
PUSH1 0x0 RETURN -> mandar 0x0 para o topo da stack e retornar. O opcode RETURN irá retornar o bytecode de runtime que estava armazenado na memória no offset 0x0 com comprimento 0xB2.
RETURN -> finaliza a execução e retorna o código de runtime com um resultado. A primeira palavra da stack é a memória offset do resultado, e a segunda palavra é o offset final na memória do resultado.
INALID -> indica o final do código init e o começo do código do runtime. Agora tivemos sucesso no deploy do nosso contrato na blockchain e seu runtime bytecode é parte do estado global sob o endereço das nossas contas de contrato. Agora nós avançamos e vamos dar uma olhada no runtime bytecode chamando uma função específica do nosso contrato em deploy ao iniciar uma nova transação. Nosso contrato Example tem apenas uma função que é um getter para a variável de armazenamento exampleNumber (getters são gerados automaticamente pela solidity para variáveis de estado público). Tenha em mente que estados puramente de leitura não necessitam de uma transação e podem ser feitos simplesmente lendo da base de dados do seu nó. Entretanto, para manter essa ilustração simples nós vamos ler o valor ao engatilhar uma transação da mesma forma que chamaríamos qualquer função que mudaria o estado.
Vamos passar pela única função getter do runtime bytecode exampleNumber(). Quando chamamos uma função num smart contract o campo de dados da transação irá conter os primeiros quatro bytes do hash keccak256 da assinatura da função seguida pelos argumentos de input. No nosso caso não temos nenhum argumento de input e por isso o campo de dados da nossa transação apenas contém aqueles 4 bytes. No caso do exampleNumber() ele gera 0x511A0 como input para o campo de dados. Além disso, nossa transação terá 0 como campo do valor desde que o getter seja impagável. Vamos ver como a função getter e a chamada do exampleNumber() executam, indo passo a passo na execução do runtime bytecode.
Nota: Uma vez que haverá muitos jumps condicionais nesta parte do bytecode, há uma tabela no final desta postagem mapeando cada instrução do runtime bytecode para seu contador do programa, de forma que você pode conferir o jump para o local correto.
PUSH1 0x80 PUSH1 0x40 MSTORE -> definindo a ponteira de memória livre como foi feito no começo do código init.
CALLVALUE DUP1 ISZERO -> Manda o input do campo valor da transação para a stack, duplica o input, checa se é zero, retira ele, se for verdadeiro empurra 0x1 ou 0x0. Vamos novamente considerar que nossa transação não enviou nenhum ether como parte de seu campo valor, então nós empurramos 0x1 para a stack. Você pode provavelmente já adivinhar o que está acontecendo aqui, estamos checando novamente se o ether foi incorretamente enviado para uma função impagável.
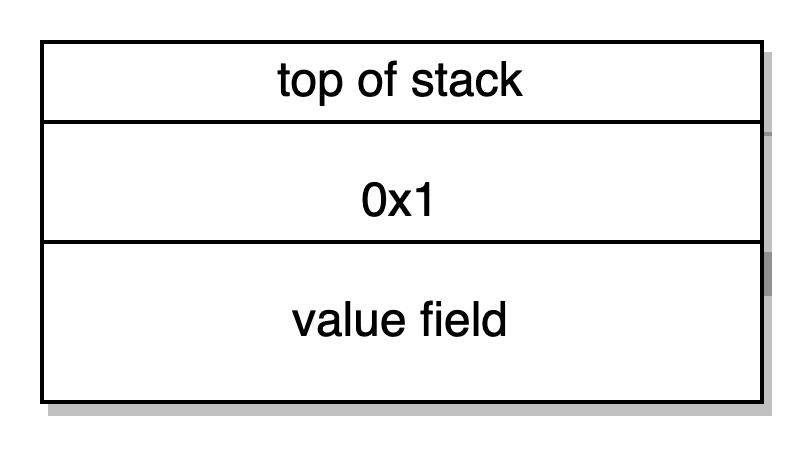
PUSH1 0xF JUMPI-> manda 0xF para o topo da stack e salta para a instrução no contador 0xF do programa se a segunda palavra da stack é 0x1. Se o ether foi enviado como parte do campo valor na nossa transação nós não poderemos saltar para o contador 0xF do programa e continuaríamos revertendo daqui (PUSH1 0X0 DUP1 REVERT) porque nossa única função exampleNumber() é impagável.
Dica de otimização do gas: Você pode economizar um pouco de gas (CALLVALUE DUP1 ISZERO PUSH1 0xF JUMPI) fazendo todas suas funções pagáveis para evitar a checagem do campo valor como também foi demonstrado por aqui por Mudit Gupta.
Desta parte em diante o bytecode vai validar que o campo de dados da nossa transação (calldata) tem pelo menos 4 bytes (requerimento mínimo uma vez que é o tamanho de um seletor de função como mencionado previamente).
POP PUSH1 0x4 CALLDATASIZE → remove a palavra do topo da stack e manda 0x4 em seu lugar. O opcode CALLDATASIZE empurra o tamanho do campo de dados da transação para a stack.

LT-> checa se o tamanho da calldata (palavra no topo) é menor que quatro bytes (segunda palavra), se for, então 0x1 é mandado para a stack, senão 0x0. As duas palavras do topo são retiradas da stack. Uma vez que nossa transação para chamar exampleNumber() tinha uma calldata de exatamente 4 bytes, 0x0 é enviado para cima da stack para indicar que o tamanho da calldata é maior ou igual a quatro bytes.
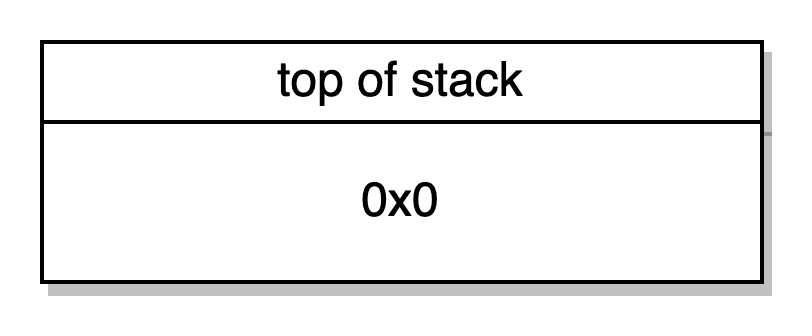
PUSH1 0x27 JUMPI-> manda 0x27 para cima do stack e salta para este contador do programa se a segunda palavra da stack é 0x1 (se a calldata fosse menor que 4 bytes), de onde nosso caminho de execução irá reverter e falhar. Se diferente, (se a calldata for maior que 4 bytes) então continua. No nosso caso, a gente continua, uma vez que o input da nossa transação é uma função seletora válida de 4 bytes.
Daqui em diante o bytecode vai iterar pela tabela da função JUMP ao comparar a função seletora da calldata de nossa transação com as funções disponíveis no contrato e saltar para a mais apropriada para executar seu runtime bytecode. Uma vez que muitos saltos vão ocorrer nós não vamos passar pelo bytecode, byte por byte, e ao invés disso vamos seguir o fluxo de execução continuando no contador de programa correspondente.
PUSH1 0x0 CALLDATALOAD PUSH1 0xE0-> manda 0x0 para a stack e manda o input da calldata de 32 bytes para a stack, empurrando 0xE0 para cima na stack.
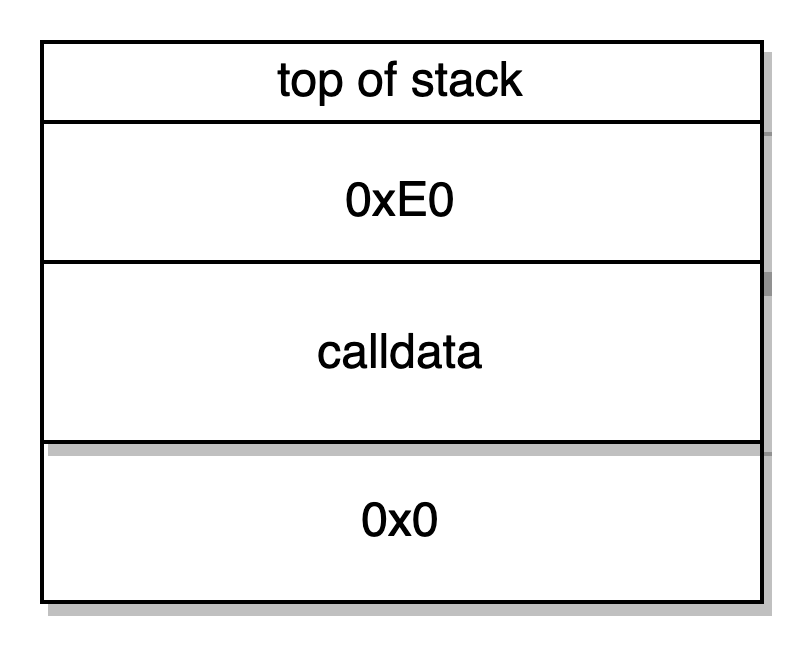
SHR -> opcode para mudar para a direita. Aqui nós mudamos o input de calldata para direita 0xE0 (224) vezes. 32 bytes era o tamanho do input de calldata para os quais os primeiros 4 bytes eram a função seletora. Assim, a segunda palavra da stack foi reduzida para ser a função seletora propriamente dita. Além disso, o opcode SHR retira a primeira palavra da stack nos deixando com:

DUP1 PUSH3 0x511A0 -> duplica a função seletora e manda os próximos três bytes para a stack: 0x511A0 (se lembra desse hexadecimal? Este eram os primeiros 4 bytes do keccak256 do exampleNumber(), o qual nós calculamos mais cedo como input para nosso campo de dados.

EQ -> manda 0x1 na stack se a segunda palavra é igual à palavra no topo, i.e se a função seletora da calldata é igual a 0x511A0. No contrato Example nós tínhamos apenas uma função runtime, a getter para recuperar o valor exampleNumber. Lembre-se, na 0x511A0 estão os primeiros 4 bytes do hash kekkak256 do “exampleNumber()”. Assim, o que o código runtime está fazendo aqui é checar qual função a transação está chamando. Uma vez encontrado um match a execução salta para o contador do programa correspondente onde aquele código runtime da função está localizado. No nosso caso há apenas uma função, então a primeira comparação é um match bem sucedido e nós mandamos 0x1 para o topo da stack.

Dica para otimização do Gas: caso nós tenhamos mais funções em nosso smart contract nós devemos continuar fazendo essa comparação até encontrarmos a função relevante para executar. Você pode otimizar o uso de gas no tempo de execução de seu contrato nomeando suas funções mais usadas, de forma que elas apareçam cedo na ordem da busca. Se há mais de 4 funções em seu smart contract, a busca binária é aplicada. A ordem de suas funções aparecem em ordem ascendente. Portanto, você pode nomear suas funções mais usadas para que elas apareçam primeiro (no meio).
PUSH1 0x2C JUMPI -> manda 0x2C (o local das funções exampleNumber() código runtime) para o topo da slack e salta para ela uma vez que a palavra no topo da stack era 0x1, indicando que o jump deveria acontecer.
Contador 0x2C do programa: JUMPDEST PUSH1 0x32 PUSH1 0x46 JUMP -> nós saltamos para o contador 0x2C do programa indicado como um destino de salto válido pelo opcode JUMPDEST, se a função seletora na calldata correspondeu à função seletora do nosso getter no exampleNumber(). Nós mandamos 0x46 para a stack e saltamos o contador 0x46 do programa.
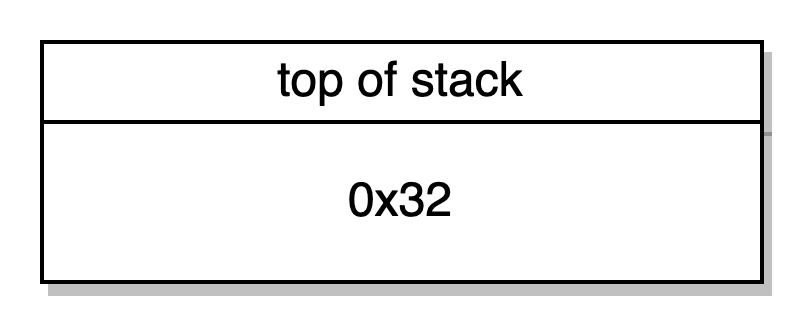
Contador de programa 0x46: JUMPDEST PUSH1 0x0 SLOAD DUP2 JUMP -> nós saltamos para o contador 0x46 do programa, validado pelo JUMPDEST opcode. O slot de armazenagem 0 fica carregado na stack (o qual é o slot de armazenagem da nossa única variável de estado example number) e a segunda palavra da stack é duplicada e nós saltamos para o contador 0x32 do programa.
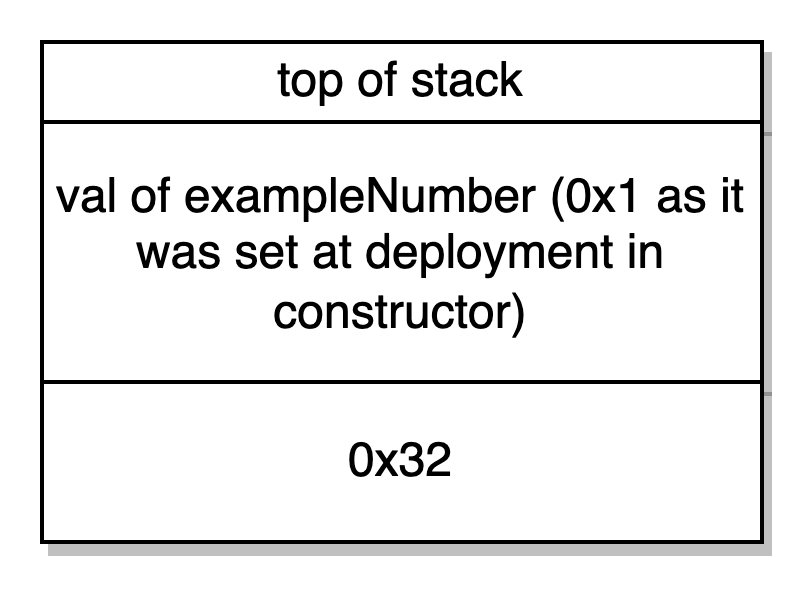
Contador de programa 0x32: UMPDEST PUSH1 0x40 MLOAD PUSH1 0x3D -> Manda 0x40 para a stack e carrega aquele local da memória o qual é 0x80. Lembre-se que 0x80 era a ponteira de memória definida no início. Nós mandamos 0x3D para a stack.

SWAP2 SWAP1PUSH1 0x59 JUMP -> troca o 3o e 1o elemento da stack deixando-nos com a stack à esquerda. Nós empurramos 0x59 na stack e saltamos para o contador 0x59 do programa.

Contador 0x59 do programa: JUMPDEST PUSH1 0x0 PUSH1 0x20 DUP3 -> manda 0x0 e 0x20 para a stack e duplica a 3a palavra no topo da stack.

ADD SWAP1 POP PUSH1 0x6C PUSH1 0x0 DUP4 ADD DUP5 PUSH1 0x4C -> mais manipulações da stack levando à stack abaixo (como um exercício, verifique, não confie ;)) e nós saltamos para a palavra no topo da stack 0x4c.
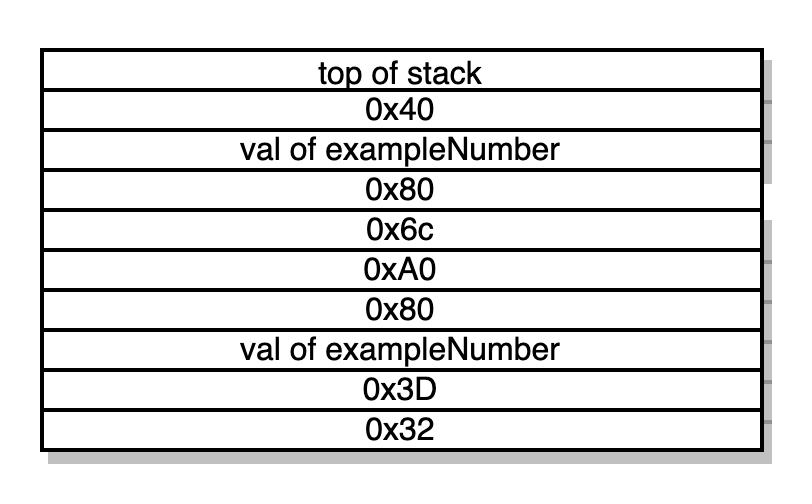
Contador 0x4c do programa: JUMPDEST PUSH1 0x53 DUP2 PUSH1
0x72 JUMP -> mais manipulações… e saltando para 0x72
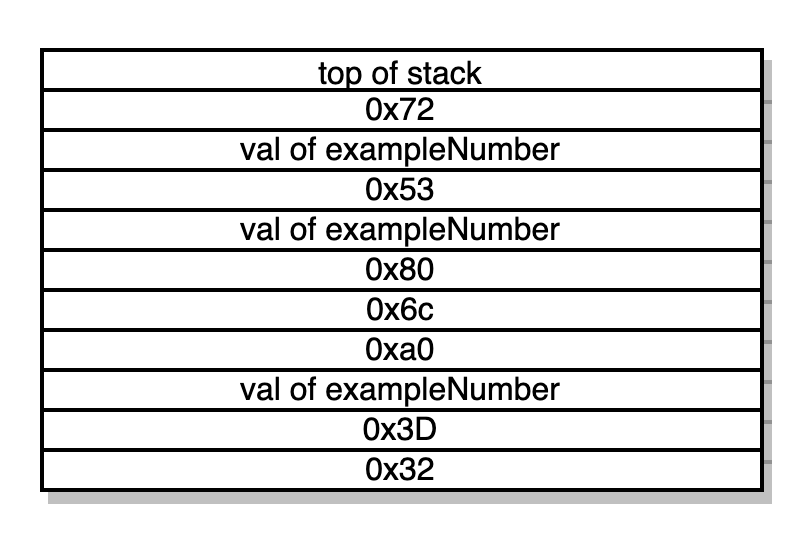
Contador 0x72 do programa: JUMPDEST PUSH1 0x0 DUP2 SWAP1 POP SWAP2 SWAP1 POP JUMP -> mais manipulações da stack e saltando para 0x53
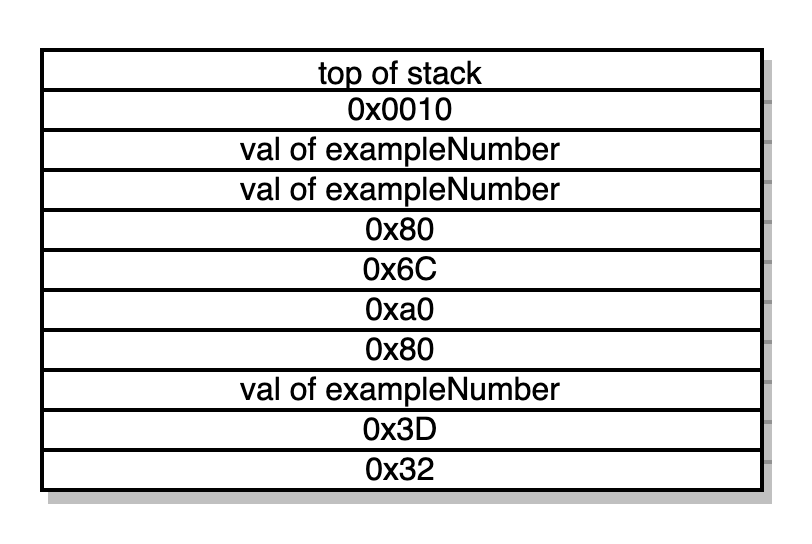
Contador 0x53 do programa: JUMPDEST DUP3 MSTORE POP POP JUMP →duplica a 3a palavra da stack (o valor de examplenNumber) e a armazena no local 0x80 (nossa ponteira de memória livre) na memória e retira as duas palavras do topo da stack. Salta para pc 0x6C

Contador 0x6C de programa: JUMPDEST SWAP3 SWAP2 POP POP JUMP -> manipulação da stack e salta para 0x3D
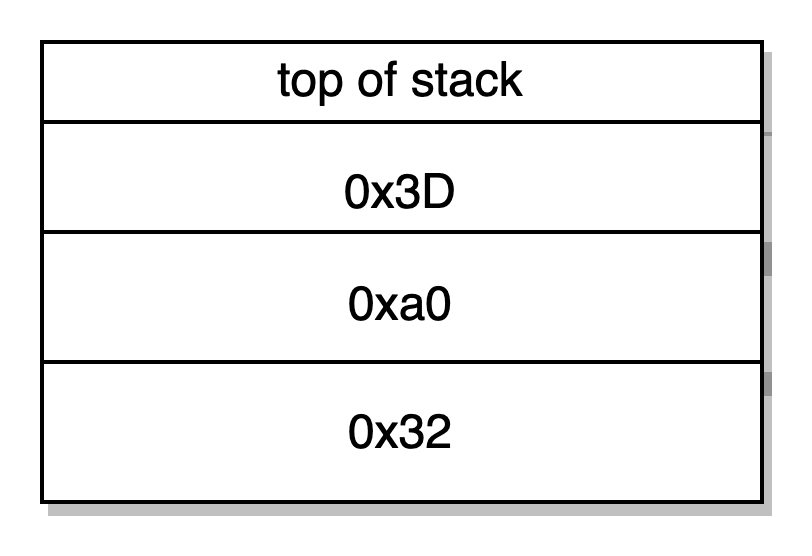
Contador 0x3D do programa: JUMPDEST PUSH1 0x40 MLOAD DUP1 SWAP2 SUB SWAP1 -> carrega a ponteira 0x80 da memória livre e algumas operações da stack levando para:
RETURN -> retorna o valor ao local 80 da memória (a ponteira de memória livre) do comprimento 0x20 (palavra de 32 byte). A última palavra da stack não é usada.
TL;DR: O runtime bytecode da função getter do exampleNumber() carregou a única variável do slot zero, a armazenou na memória no local da nossa ponteira de memória livre e a retornou com o RETURN opcode.
Tada! Era isso! Nós fomos do código fonte até o deploy do bytecode resultante e chamando uma função no runtime bytecode armazenado. Espero que te ajude e te dê uma idéia do que acontece “por trás das cortinas”. Este foi um exemplo bastante simplista para demonstrar como fazer debug no nível da EVM e espero que o ajude a colocar a mão na massa com casos mais complexos. Um exemplo mais detalhado desta análise byte a byte pode ser encontrado aqui. Divirta-se!