
Descrevemos anteriormente a Neural Style Transfer (Transferência de Estilo Neural) e Deep Dream (Sonho Profundo), que estavam entre as primeiras aplicações populares da tecnologia AI em obras artísticas há 5 anos, mas rapidamente abriram caminho para um modelo mais poderoso e capaz chamado Inversão Textual. Stable Diffusion é uma ferramenta gratuita que usa a técnica de inversão textual para criar obras de arte usando IA. A ferramenta fornece aos usuários acesso a uma grande biblioteca de arte gerada por um modelo de IA que treinou o enorme conjunto de imagens do ImageNet e o conjunto de dados LAION. Os modelos de difusão resultantes são capazes de criar imagens incrivelmente realistas em uma variedade de mídias, incluindo pinturas digitais, arte baseada em fotos, quadrinhos e até mesmo animações. A ferramenta é incrivelmente fácil de usar e pode criar imagens em segundos. Podemos ver no site da Lexica muitos exemplos de prompts que geram belas obras de arte por Stable Diffusion.
Depois de treinar com sucesso uma incorporação pessoal, a criatividade de IA do Stable Diffusion é quase infinita. Os algoritmos que alimentam o Stable Diffusion são duas redes neurais que funcionam em conjunto. Eles são chamados de autoencoder e rede adversária generativa, que são um tipo de rede neural projetada para aprender padrões em dados. A arquitetura é alimentada com bilhões de prompts de imagem e texto ao longo de milhares de horas de computador para ensiná-la a processar a linguagem e entender as imagens. Após o treinamento, pode associar certas palavras ou frases a certos elementos visuais. Por exemplo, ele pode aprender quando você digita a palavra “floresta”, deve gerar uma imagem contendo árvores e folhas.
O prompt de amostra para gerar a maioria dos retratos a seguir é
"[realbenny-t2 | panda] retrato frontal feliz como pixar, personagem da disney
ilustração de artgerm, tooth wu, studio ghibli, foco nítido, artstation".

Figura. Exemplos de retratos gerados por IA Stable Diffusion usando a incorporação pessoal treinada com o prompt de entrada fornecido. Temos muitos controles no Stable Diffusion para instruir a direção da criatividade da IA.
Se você estiver interessado em aprender como usar o Stable Diffusion para gerar imagens de perfil pessoal a partir de prompts de texto, depois de ler este artigo, você poderá treinar um modelo de embeddings pessoais para a IA Stable Diffusion!
Instalando a Stable Diffusion
O repositório oficial da Stable Diffusion chamado AUTOMÁTICO1111 fornece instruções passo a passo para instalação no Linux, Windows e Mac. Não vamos passar por eles aqui, mas vamos deixar algumas dicas caso você decida instalar em um Mac com chip M1 Pro. Se você não estiver usando o M1 Pro, pode pular esta seção com segurança.
Instalação no Mac M1 Pro
Se o Xcode não estiver totalmente instalado. Execute isto para concluir a instalação:
xcodebuild -runFirstLaunch
Embora a interface do usuário da Web funcione bem, ainda há alguns problemas ao executar esse fork no Apple Silicon. Todos os samplers parecem estar funcionando agora, exceto para “DPM fast” (que retorna ruído aleatório), e DDIM e PLMS (ambos falham imediatamente com o seguinte erro: “AssertionError: Torch não compilado com CUDA ativado”).
Instalar o HomeBrew
Primeiro, você precisa instalar as dependências necessárias usando Homebrew.
xcode-select --install /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/benny.cheung/.bash_profile eval "$(/opt/homebrew/bin/brew shellenv)" brew -v
Instale o Rosetta 2
A mágica por trás da tradução do código intel_64 bits para arm64 automaticamente!
sudo softwareupdate --install-rosetta --agree-to-license
Instalar requisitos de difusão estável
O script pode ser baixado aqui, ou siga as instruções abaixo.
brew install cmake protobuf rust python git wget
O script pode ser baixado aqui, ou siga as instruções abaixo.
- Abra Terminal.app
- Execute os seguintes comandos:
$ cd ~/Documents/
$ curl https://raw.githubusercontent.com/dylancl/stable-diffusion-webui-mps/master/setup_mac.sh -o setup_mac.sh
$ chmod +x setup_mac.sh
$ ./setup_mac.sh
Após a instalação, você encontrará agora run_webui_mac.sh no stable-diffusion-webui diretório. Execute este script para iniciar a interface do usuário da web usando./run_webui_mac.sh. Esse script ativa automaticamente o ambiente conda, obtém as alterações mais recentes do repositório e inicia a interface do usuário da Web. Na saída, o ambiente conda é desativado.
As notas de instalação pós-preparação:
Após a instalação, não queremos que o PostgreSQL e o Redis sempre iniciem quando o Mac for reiniciado, faça isso para remover o serviço
brew services stop postgresql@14
brew services stop redis
Como funciona o Stable Diffusion?
Stable Diffusion é um modelo de geração de texto para imagem onde você pode inserir um prompt de texto como,
metade (realbenny-t1 | yoda) pessoa, guerra nas estrelas,
Arte de Artgerm e Greg Rutkowski e Alphonse Mucha
Steps: 30, Sampler: LMS, CFG scale: 7, Seed: 3711471449, Size: 512x512, Model hash: 7460a6fa, Denoising Strength: 0,75, Mask Blur: 4
- Combinação de
realbenny-t1uma incorporação autotreinada eYodada rede padrão, exibido como uma pessoa. - Plano de fundo e tema como em
guerra estelar - Combinação de estilos artísticos de
artgrem,Greg Rutkowskiealphonse mucha
Ele produz uma imagem (512x512) como saída como esta, que se parece comigo e com a criatura híbrida yoda!

Visão de alto nível
Existem três partes no sistema:
- Um modelo de linguagem que transforma o prompt de texto que você insere em uma representação que pode ser usada pelo modelo de difusão por meio de mecanismos de atenção cruzada. Eles usam um tokenizer Bert “da prateleira” com um transformador para esta parte.
- O modelo de difusão é um U-Net condicional ao tempo. Leva como entrada sua representação de prompt de texto e uma fonte de ruído gaussiano. Ele remove o ruído da representação, aproximando-se do seu prompt de texto. Isso é repetido várias vezes e essas alterações são conhecidas como intervalos de tempo.
- Um decodificador que pega a saída do modelo de difusão e o transforma em uma imagem completa. O modelo de difusão opera em 64x64, e o decodificador aumenta para uma resolução de 512x512, com o objetivo de manter características semelhantes na imagem resultante, conforme visto na entrada de 64x64.
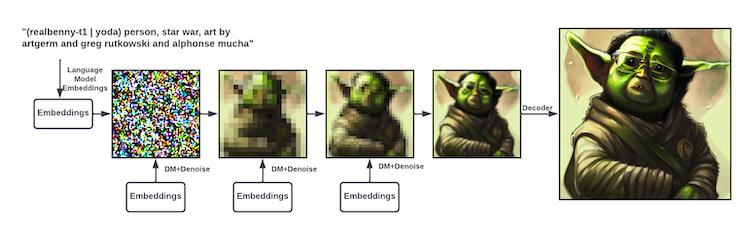
Figura. O modelo de linguagem cria uma incorporação do prompt de texto. É alimentado no modelo de difusão com algum ruído aleatório. O modelo de difusão limpa o ruído durante as incorporações (embeddings). Isso é repetido várias vezes. Então, no final, o decodificador dimensiona a imagem para um tamanho maior.
A publicação de Marc Päpper tem uma ótima explicação sobre os conceitos de treinamento técnico, que não é abordado neste artigo.
Do ruído à imagem realista
Todas as partes da arquitetura Stable Diffusion foram treinadas em uma enorme quantidade de imagens e texto para criar uma incorporação que cobre a maior parte do nosso espaço semântico humano. Quando os conceitos são combinados em um novo prompt de texto, os conceitos são combinados em uma nova representação que cobre os conceitos de entrada. O modelo de difusão latente é treinado para descobrir uma imagem fora do ruído, mas guiada pela incorporação do autoencoder e do modelo de texto, a imagem acaba sendo uma combinação dos conceitos que foram inseridos no prompt. O decodificador ajuda a ampliar e criar uma imagem de alta resolução a partir do processo de criação da imagem.
As imagens aleatórias são criadas usando “ruído”. O ruído é um tipo de dado que não contém nenhuma informação útil. O modelo usa um processo chamado “difusão” para gerar as imagens de saída. Na difusão, os dados fluem por várias camadas de ruído, que são imagens geradas aleatoriamente que não contêm nenhuma informação. Quando o modelo é apresentado inicialmente com um prompt de texto, ele não tem conhecimento prévio de como a imagem de destino deve ser. Como resultado, ele começa gerando aleatoriamente uma imagem que não contém nenhum elemento visual.
Ou seja, quando a imagem inicial é apenas “ruído”. O algoritmo seleciona algumas imagens que correspondem às palavras-chave do prompt. É tentar encaixar as imagens no “ruído”. O algoritmo começa captando padrões amplos nas imagens de entrada. Por exemplo, pode aprender que certas cores são mais comumente associadas a certos tipos de imagens. Em seguida, ele usa esses padrões amplos para criar imagens detalhadas com as cores apropriadas. Depois de gerar algumas imagens, o algoritmo começará a captar padrões mais específicos e continuará a refinar as imagens
A mágica é que a arquitetura Stable Diffusion aprendeu conceitos visuais sobrepostos durante seu treinamento. É capaz de combinar conceitos como “meio homem / meio yoda” e criar uma imagem completa porque aprendeu as duas partes individuais desse conceito durante o treinamento. A arquitetura também foi capaz
- para usar os conceitos específicos, como Star Wars ou Yoda, treinando em uma grande quantidade de imagens desses conceitos
- para usar uma incorporação treinada adicional de
realbenny-t1no topo como um novo conceito
À medida que os dados fluem por cada camada, eles captam mais e mais padrões de seus arredores, resultando em uma imagem mais detalhada. À medida que os modelos aprendem mais e mais padrões de seus arredores, lentamente começam a adicionar mais detalhes. Isso continua até chegar ao final do processo de difusão, momento em que é capaz de produzir uma imagem hiper-realista que corresponde perfeitamente à entrada do usuário.
Quando o modelo atinge a camada final, ele pode produzir imagens altamente realistas que correspondem ao prompt de texto. O processo de criação de uma imagem a partir de um prompt de texto é conhecido como “inversão textual”. Ao combinar todas essas imagens e conceitos, ele pode criar novas imagens realistas, usando o conhecimento adquirido.
Antes de entrarmos no processo de treinamento para um modelo de incorporação pessoal, vamos discutir a diferença entre uma incorporação e uma hiper rede.
Diferença entre incorporação (embedding) e uma hiper-rede (hypernetwork)
A camada de Incorporação no Stable Diffusion é responsável por codificar as entradas (por exemplo, o prompt de texto e os rótulos de classe) em vetores de baixa dimensão. Esses vetores ajudam a orientar o modelo de difusão para produzir imagens que correspondam à entrada do usuário. A camada Hiper-rede é uma forma do sistema aprender e representar seu próprio conhecimento. Ele permite que a Stable Diffusion crie imagens com base em sua experiência anterior.
Incorporação
- Incorporação: O resultado da inversão textual. A inversão textual tenta encontrar um prompt específico para o modelo, que cria imagens semelhantes aos seus dados de treinamento. O modelo permanece inalterado e você só pode obter coisas das quais o modelo já é capaz. Portanto, uma incorporação é basicamente apenas uma “palavra-chave” que será expandida internamente para um prompt muito preciso.
Uma incorporação é quando as características dos objetos são mapeadas em um espaço vetorial. Por exemplo, em uma tarefa de aprendizagem de máquina, um conjunto de treinamento pode consistir em vetores de recursos que representam os objetos sobre os quais ele está tentando aprender. A técnica de incorporação converte as características de cada objeto em um vetor de números. O vetor pode então ser usado como entrada para outro algoritmo de aprendizagem de máquina, como uma rede neural.
Hiper-rede
- Hiper-rede: É uma camada adicional que será processada, depois que uma imagem for renderizada pelo modelo. A Hiper-rede irá distorcer todos os resultados do modelo em direção aos seus dados de treinamento, então, na verdade, “alterando” o modelo com um tamanho de arquivo pequeno de ~80 MB por hiper-rede.
No Stable Diffusion, a hiper-rede é responsável por reter a memória das imagens que o sistema gerou anteriormente. Isso significa que quando o usuário fornece uma nova entrada, o sistema pode usar seu conhecimento anterior para criar uma imagem mais precisa. As hiper-redes permitem que o sistema aprenda mais rápido e melhore com o tempo.
Vantagens e desvantagens
As vantagens e desvantagens são basicamente as mesmas: cada imagem que contém algo que descreva seus dados de treinamento parecerá com seus dados de treinamento. Se você treinou um gato específico, terá muita dificuldade em tentar obter qualquer outro gato usando a hiper-rede. No entanto, parece depender de palavras-chave já conhecidas do modelo.
Para nosso caso de uso, está gerando autorretrato a partir de prompts de texto. Descobrimos que o treinamento com incorporação pessoal resultou em resultados mais rápidos e melhores quando comparados às hiper-redes. Percebemos menos erros da IA ao tentar gerar imagens realistas, e nossos sujeitos de teste descobriram que as imagens resultantes eram mais desejáveis.
Processo de Incorporação de Treinamento (Inversão Textual)
Para garantir que sua rede neural seja treinada adequadamente, é imperativo fornecer quantidades adequadas de imagens que representem você em uma variedade de aparências, poses e planos de fundo. Se você apenas fornecer à IA fotos de você fazendo uma pose ou vestindo uma roupa, ela só poderá gerar imagens que correspondam a essa entrada. Dar à sua IA um conjunto diversificado de imagens para aprender garantirá uma gama mais ampla de opções e imagens.
Segundo o vídeo de Jame Cunliffe, aprendemos que apenas 20 imagens são suficientes.
- 3 de corpo inteiro com ângulo diferente
- 5 de meio corpo com ângulo diferente
- 12 closes com diferentes ângulos e expressões faciais
- Estou um pouco paranoico - apenas dê um pouco mais
O processo de treinamento espera que as imagens fornecidas sejam de dimensão 512x512. Se suas imagens forem de tamanho diferente, você pode usar o Birme para ajustar e redimensionar as imagens para que correspondam aos requisitos adequados para a leitura da rede neural.
BIRME ‘Redimensione qualquer imagem para 512x512 gratuitamente; é claro que você pode usar o Photoshop se tiver a licença.
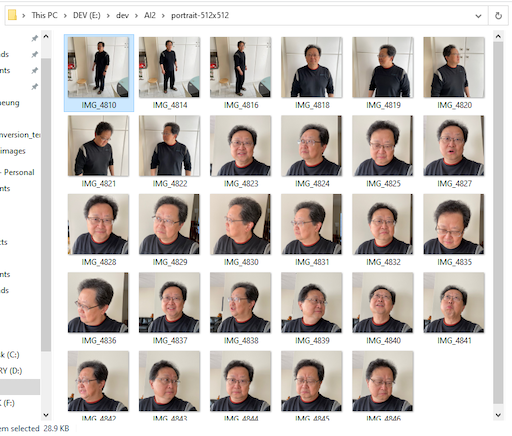
Figura. Apenas para demonstração de várias postagens de retratos pessoais de rostos não tão bonitos.
Recomendamos seguir o estilo de Greg Rutkowski
- use o seguinte prompt para preparar o processo de treinamento da hiper-rede, para seguir as variações de estilo
Um retrato de um homem, tendência no Artstation, Greg Rutkowski, 4k
Posteriormente, estamos utilizando o txt2img para obter uma amostra durante o treinamento. É por isso que estamos inserindo um prompt aqui primeiro, caso nos esqueçamos.
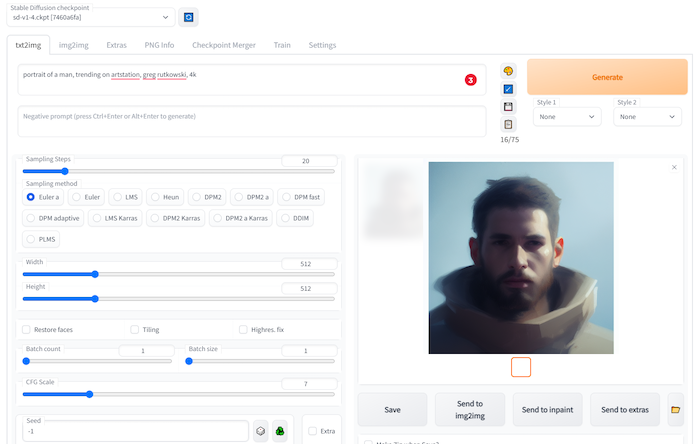
Figura. Digite um prompt de teste na página txt2img; posteriormente, ele será usado para treinar os resultados da amostra. Você pode usar a amostra de treinamento para monitorar o progresso do treinamento.
Stable Diffusion treinando a incorporação
Descobrimos que treinar com incorporação é mais fácil do que treinar com uma hiper-rede para gerar autorretratos. Nosso treinamento rendeu bons resultados com os quais estamos satisfeitos.
Observações importantes sobre requisitos de hardware
É importante observar que você precisará de uma GPU com pelo menos 8 GB de VRAM para treinar um modelo de incorporação pessoal. Este é um requisito de hardware essencial para gerar imagens de qualidade, e a falta de uma GPU boa o suficiente pode resultar em baixa qualidade de imagem ou baixo desempenho.
Se você não possui uma placa de vídeo compatível, considere o uso de infraestrutura em nuvem para treinamento. Você pode criar seu próprio modelo de incorporação usando Runpod.Io, Google Colab ou outra plataforma que forneça acesso à nuvem para um hardware habilitado para GPU necessário para o treinamento.
Etapa 1 - Criar uma nova Incorporação
- Dê um nome - esse nome também é o que você usará em seus prompts, por exemplo
realbenny-t1para 1 token erealbenny-t2para incorporações de 2 tokens. O nome deve ser único o suficiente para que o processo de inversão textual não confunda sua incorporação pessoal com outra coisa. - Defina alguma inicialização - eu gosto de usar "face" ou "pessoa", pois me dá uma variedade decente de resultados e é simples de lembrar ao escrever prompts.
- Defina o número de vetores por token (recomende usar 1 ou 2, pois é bem equilibrado entre palatabilidade e precisão para faces, mas depende de suas preferências).
- Mais vetores tendem a precisar de mais imagens, então esteja preparado para gerar mais com tantos vetores
Passo 2 - Processar Imagens
Esta etapa basicamente torna as imagens 512x512 e pode renomeá-las
- Selecione um diretório de origem de imagens (por exemplo,
/home/data/minhas_imagens) - Selecione um destino de imagens (por exemplo,
/home/data/my_images/preprocess) - Opcionalmente, selecione inverter e adicionar legenda (usando BLIP para gerar legenda automaticamente para a imagem). Quando estamos treinando o rosto de uma pessoa, inverter o rosto não é uma boa ideia.
- Clique em “Pré-processar”
Passo 3 - Treine
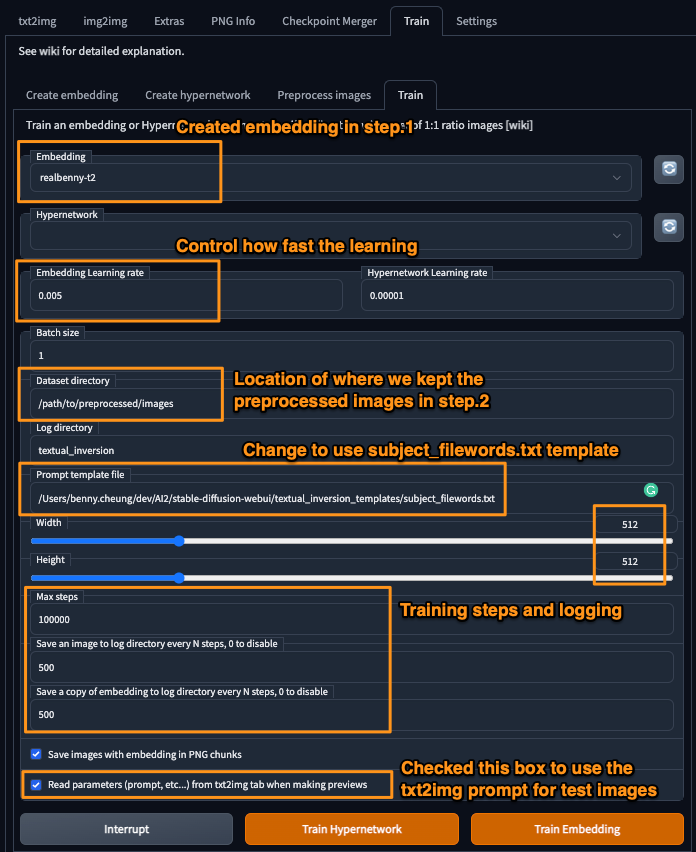
Figura. Mostrando uma tela de exemplo de configurações de difusão estável - treinamento para incorporação
- Cole o diretório de destino da etapa 2. na caixa "Diretório do conjunto de dados" (por exemplo,
/home/data/my_images/preprocess) - Definir a taxa de aprendizado é muito importante, isso afetará o treinamento da rede neural
- mais alta = aprendizado “mais rápido”, mas cuidado com o NaN! (parâmetros explodidos)
- Eu fui tão baixa quanto 0,0005 e tão alta quanto 0,005
- com menos vetores, uma taxa de aprendizado ligeiramente maior pode ajudar. Usei 0,005 com 1 vetor e parece OK.
- Se não estiver usando um estilo, altere o arquivo de modelo de prompt para
subject_filewords.txt- style.txt e subject.txt são iguais, mas não use o nome do arquivo como (legenda)
- Eu preferi criar um novo arquivo de modelo, chamado
palavras de arquivo.txt, que contém apenas o modelo de[nome] e [palavras do arquivo].
- Reduza as etapas máximas - porque 100.000 leva muitas horas. Acima de 30000 passos fazem muito pouca diferença. Além disso, não importa se o número de passos é muito grande, podemos interromper o treinamento a qualquer momento.
- Pressione “Train” - verifique seu diretório de log para imagens e incorporações.
Etapa 4 - Colocar a incorporação em uso
Depois que a incorporação treinada é concluída, encontramos os resultados na pasta textual_inversion/<data>/embeddings. Podemos revisar as imagens de exemplo e encontrar aquela que melhor se ajusta ao tipo de imagem que você deseja gerar. Depois de encontrar um arquivo de incorporação com o qual esteja satisfeito, você vai desejar criar uma cópia dele e colocá-la em sua pasta de modelos de incorporações.
Por exemplo, observamos que o melhor é textual_inversion/<data>/embeddings/realbenny-t2-30000.pt
- copie o melhor arquivo treinado da incorporação
.ptpara a pasta de nível superiorincorporaçõese renomeie-o pararealbenny-t2.pt - reinicie a IU do Stable Diffusion. Você pode ver que as incorporações são carregadas automaticamente,
... Loaded a total of 2 textual inversion embeddings. Embeddings: realbenny-t2, realbenny-t1 …
- A palavra-chave de incorporação
realbenny-t2está pronto para ser usada. No nosso caso, também treinamos uma incorporação adicionalrealbenny-t1com 1 token para que possamos usar diferentes incorporações para diferentes parâmetros de geração.
Notas de bônus: atenção imediata/ênfase
Há uma adição recente ao Stable Diffusion. Quando usamos () no prompt aumenta a atenção do modelo para palavras incluídas e [] o diminui. Você pode combinar vários modificadores: Folha de dicas:
uma (palavra)- aumentar a atençãopalavrapor um fator de 1,1uma ((palavra))- aumentar a atençãopalavrapor um fator de 1,21 (= 1,1 * 1,1)uma [palavra]- diminuir a atençãopalavrapor um fator de 1,1a (palavra:1.5)- aumentar a atençãopalavrapor um fator de 1,5a (palavra: 0,25)- diminuir a atençãopalavrapor um fator de 4 (= 1/0,25)uma \(palavra\)- use caracteres literais()no prompt
Com (), um peso pode ser especificado assim: (text:1.4). Se o peso não for especificado, presume-se que seja 1,1. A especificação do peso só funciona com () não com [].
Se você quiser usar qualquer um dos caracteres literais ()[] no prompt, use a barra invertida para escapá-los: anime_\(personagem\).
Observações Finais
Esperançosamente, as informações fornecidas sobre Stable Diffusion neste artigo fornecerão informações suficientes sobre a arquitetura para criar seu próprio modelo de incorporação pessoal. Além de seu uso para fotos de perfil, você pode encontrar outros casos práticos de uso para gerar imagens com base em prompts de texto!
O leitor interessado pode continuar estudando o próximo artigo sobre Treinamento Dreambooth para incorporação pessoal, que descreve como treinar uma incorporação de hiper-rede do Stable Diffusion.
Isto é apenas o começo. Vá em frente e treine sua incorporação!
Referências
publicações formais
- Robin Rombach, et. al.,Síntese de imagens de alta resolução com modelos de difusão latente, arXiv:2112.10752v2 cs.CV, 13 de abril de 2022
- Nataniel Ruiz, et. no.,DreamBooth: modelos de difusão de texto para imagem de ajuste fino para geração orientada por assunto, arXiv:2208.12242v1 cs.CV, 25 de agosto de 2022, Google Research
- On-linePostagem no blog DreamBooth
Outra postagem de blog relacionada
- Tomás Capelle, Fazendo do meu filho um mestre Jedi com difusão estável e Dreambooth, Pesos e vieses, outubro de 2022.
- A versão mais recente do Stable Diffusion tem o treinamento sobre incorporação. Isso é equivalente ao Dreambooth. Basicamente, você passa várias imagens diferentes de alguém (ou algo) para o modelo e ele aprenderá a retratar essa pessoa ou coisa. Para tornar mais fácil para o modelo entender esse novo ��conceito”, você também dá ao modelo a classe desse conceito.
- Mark Papper, Como e por que a difusão estável funciona para geração de texto para imagem, blog papper.com, agosto de 2022.
- Esta postagem de blog explicou os detalhes técnicos mais profundos sobre como funciona a geração de imagem do Stable Diffusion.
Stable Diffusion
- Recursos de Stable Diffusion 1.4
- Repositório Stable Diffusion AUTOMÁTICA1111
- Como Treinar Guia de Hiper-rede
Tutoriais em vídeo
- James Cunliffe, Crie arte a partir do seu rosto com IA gratuitamente, parte 2 - Sem Google Colab - Sem código - Automatic1111 Guide, vídeo do Youtube, outubro de 2022.
- Na Parte 1 desta série, mostrei como criar arte de IA usando suas próprias imagens e a versão do Google Colab de #dreambooth. Desta vez, usaremos #stablediffusion com #automatic1111, aproveitando o recurso #hiper-rede. Contanto que você tenha uma GPU poderosa o suficiente, você pode executá-lo em seu próprio computador gratuitamente. Siga o tutorial e use os links abaixo para começar a trabalhar!
- Ele tem instruções completas sobre como instalar estable diffusion no Windows
- Roedor Nerd, Inversão textual - faça qualquer coisa em Stable Diffusion, vídeo do Youtube, outubro de 2022
- Este vídeo é um pouco longo, mas explica bem o último treinamento com incorporação. Além disso, utiliza um exemplo ilustrativo de como definir o número de tokens 1, 2, 4, 16, afetando a palatabilidade da imagem gerada. Essencialmente, mais tokens gerarão imagens mais precisas que se assemelham à imagem incorporada; menos token fornecerá maior palatibilidade para a imagem gerada.
Ferramentas de suporte
- Brincar com Vocabulário para ver muitos exemplos de prompts que geram belas artes de difusão estável.
- Usar Birme para redimensionar a coleção de imagens
- O processo de treinamento espera que as imagens fornecidas sejam de dimensão 512x512. Se suas imagens tiverem um tamanho diferente, você pode usar este site para ajustar e redimensionar as imagens para que correspondam aos requisitos adequados para a leitura da rede neural.
Este artigo foi escrito por Benny Cheung e traduzido por Diogo Jorge. O artigo original pode ser encontrado aqui.