
Aproveite o poder dos Modelos de Difusão com dados de melhor qualidade.
O ControlNet tem sido uma das maiores histórias de sucesso do ML (Machine Learning ou aprendizagem automática) em 2023. O projeto, que acumulou mais de 21.000 estrelas no GitHub, foi o centro das atenções na CVPR (Conferência sobre Visão Computacional e Reconhecimento de Padrões) - e por um bom motivo: é uma maneira fácil e interpretável de exercer influência sobre os resultados dos modelos de difusão.
Em vez de executar o mesmo modelo de difusão no mesmo prompt várias vezes, esperando obter um resultado razoável, você pode orientar o modelo por meio de um mapa de entrada. Daí o slogan atrevido do ControlNet: "Deixe-nos controlar os modelos de difusão!" Existem modelos distintos do ControlNet para "controlar" a saída por meio de mapas de borda Canny, máscaras de segmentação, pontos-chave de pose e até mesmo rabiscos.
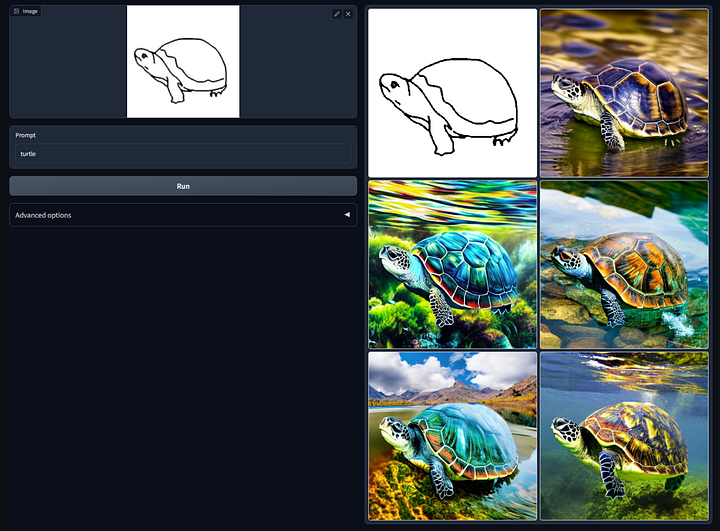
######Controle da difusão estável por meio de mapas de rabiscos com o prompt "turtle". Imagem do repositório GitHub do ControlNet 1.0.
Um dos recursos que torna o ControlNet tão popular é sua acessibilidade. Em uma era de modelos de base com centenas de bilhões de parâmetros, os modelos ControlNet têm apenas 1,45 GB (o mesmo tamanho do modelo de difusão subjacente). Em um momento em que modelos como o GPT-3.5 estão sendo treinados em dezenas de milhares de GPUs a um custo de centenas de milhares ou até milhões de dólares, um modelo ControlNet pode ser treinado em casa em uma única GPU em apenas 600 horas de GPU! Em outras palavras, você pode treinar seu próprio modelo ControlNet.
Apesar do sucesso notável do ControlNet 1.0, o modelo sofreu com alguns bugs bastante desagradáveis. Aqui está um exemplo:

######Ilustração de um modo de falha do ControlNet 1.0. Esquerda: imagem de entrada. Direita: saídas com alto "peso" da ControlNet, levando a cores supersaturadas.
Embora, para a maioria das entradas, o modelo tenha produzido imagens impressionantes e realistas, em alguns casos, como no cenário acima, a saída do modelo foi significativamente supersaturada.
Quando o criador da ControlNet, Lvmin Zhang, publicou o ControlNet 1.1, que resolveu esses problemas, as mudanças foram tão substanciais que ele criou um repositório GitHub totalmente novo!
 ######Resolução de problemas no ControlNet 1.1. Esquerda: a mesma imagem de base da figura anterior. Direita: saídas ao inserir o mesmo prompt e metadados como no caso do ControlNet 1.0 supersaturado acima.
######Resolução de problemas no ControlNet 1.1. Esquerda: a mesma imagem de base da figura anterior. Direita: saídas ao inserir o mesmo prompt e metadados como no caso do ControlNet 1.0 supersaturado acima.
A parte mais louca: não houve NENHUMA MUDANÇA na arquitetura do modelo.
O que mudou? A qualidade dos dados!
Acontece que os dados usados para treinar o ControlNet 1.0 tinham algumas falhas insidiosas, incluindo um grupo de pessoas em tons de cinza que, de alguma forma, foi duplicado milhares de vezes. O repositório do ControlNet 1.1 menciona explicitamente esse e outros problemas.
A lição:
Os dados reinam supremos. Dados de alta qualidade com desempenho de última geração.
Neste artigo do blog, mostrarei como limpar e selecionar dados de alta qualidade para que você possa treinar seu próprio modelo ControlNet de última geração.
Todo o código necessário para acompanhar e selecionar seu próprio conjunto de dados da legenda de imagem pode ser encontrado aqui.
Se você estiver ansioso, pode ir direto para os tópicos em destaque:
Configuração
As únicas bibliotecas de que precisaremos para limpar e selecionar esses dados são a pandas (para dados tabulares) e a FiftyOne (para dados de imagem não estruturados):
pip install pandas fiftyone
Além disso, você precisará da hashlib para funções acessórias e provavelmente vai querer o tqdm para acompanhar o progresso durante o download de imagens.
Você pode importar todos os módulos necessários da seguinte forma:
import hashlib
import pandas as pd
from tqdm.notebook import tqdm
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.brain as fob
from fiftyone import ViewField as F
Seleção do Conjunto de Dados
De acordo com o documento que introduziu o ControlNet, Adição de Controle Condicional para Modelos de Difusão de Texto para Imagem (CVPR 2023), os modelos originais do ControlNet foram treinados em "3 milhões de pares de legenda-imagem da Internet”.
Infelizmente, Lvmin et al. não revelam nada sobre os dados que eles usaram:
“Dada a atual situação complicada fora da comunidade de pesquisa, evitamos divulgar mais detalhes sobre os dados. No entanto, os pesquisadores podem dar uma olhada no projeto do conjunto de dados que todos conhecem.”— Lvmin Zhang.
Dito isso, as informações que eles revelam se alinham muito bem com Conjunto de dados do Google Conceptual Captions: um conjunto de dados "que consiste em cerca de 3,3 milhões de imagens anotadas com legendas". Independentemente de esse ser o conjunto de dados que a equipe do ControlNet usou para treinar seus modelos, o Conceptual Captions nos fornecerá um exemplo ilustrativo e, o conjunto de dados, quando devidamente limpo, deverá permitir o treinamento de modelos do ControlNet a partir do zero.
Download do Conjunto de Dados
O processo de download do conjunto de dados proposto pelo Google é muito complicado para o meu gosto: primeiro, você precisa fazer o download de um arquivo de variáveis separadas por tabulação (.tsv) que contém as legendas e os URLs onde as imagens correspondentes podem ser encontradas e, em seguida, você precisa fazer o download das imagens a partir de seus URLs. Para sua sorte, eu escrevi esse código para que você não precise fazer isso.
Faça o download do arquivo tsv clicando no botão "Download" na parte inferior da página do Conceptual Captions do Google ou clicando neste link.
Podemos carregar o arquivo tsv como um DataFrame da biblioteca pandas de forma semelhante a um csv, passando no sep=\t para especificar que o separador é uma tabulação.
df = pd.read_csv("Train_GCC-training.tsv", sep='\t')
Dê nomes descritivos às colunas do DataFrame:
df.columns =['caption', 'url']
Em seguida, faça o hash do URL de cada entrada para gerar um ID exclusivo:
def hash_url(url):
return hashlib.md5(url.encode()).hexdigest()[:12]
df['url_hash'] = df['url'].apply(hash_url)
O DataFrame se parece com isso:
caption url url_hash
0 sierra looked stunning in this top and this sk... http://78.media.tumblr.com/3b133294bdc7c7784b7... e7023a8dfcd2
1 young confused girl standing in front of a war... https://media.gettyimages.com/photos/young-con... 92679c323fc6
2 interior design of modern living room with fir... https://thumb1.shutterstock.com/display_pic_wi... 74c4fa5539f4
3 cybernetic scene isolated on white background . https://thumb1.shutterstock.com/display_pic_wi... f1ea388e05e1
4 gangsta rap artist attends sports team vs play... https://media.gettyimages.com/photos/jayz-atte... 9a6f8026f593
... ... ... ...
3318327 the teams line up for a photo after kick - off https://i0.wp.com/i.dailymail.co.uk/i/pix/2015... 6aec77a477f9
3318328 stickers given to delegates at the convention . http://cdn.radioiowa.com/wp-content/uploads/20... 7d42aea90652
3318329 this is my very favourite design that i recent... https://i.pinimg.com/736x/96/f0/77/96f07728efe... f6dd151121c0
3318330 man driving a car through the mountains https://www.quickenloans.com/blog/wp-content/u... ee4244df5c55
3318331 a longtail boat with a flag goes by spectacula... http://l7.alamy.com/zooms/338c4740f7b2480dbb72... 7625946297b7
Usaremos esses IDs para especificar os locais de download (filepaths) das imagens, de modo que possamos associar legendas às imagens correspondentes.
Se quisermos fazer o download das imagens em lotes, podemos fazer isso da seguinte forma:
def download_batch(df, batch_size=10000, start_index=0):
batch = df.iloc[start_index:start_index+batch_size]
for j in tqdm(range(batch_size)):
url, uh = batch.iloc[j][['url', 'url_hash']]
!curl -s --connect-timeout 3 --max-time 3 "{url}" -o images/{uh}.jpg
Aqui, baixamos um lote de imagens com um tamanho de lote (batch_size) a partir de um índice inicial (start_index) diretamente na pasta images, com o nome de arquivo especificado pelo hash do url que geramos acima. Usamos o curl para executar a operação de download e definimos limites para o tempo gasto na tentativa de baixar cada imagem, pois alguns dos links não são mais válidos.
Para fazer download de um total específico de imagens (num_images), execute o seguinte:
def download_images(df, batch_size=10000, num_images = 100000):
for i in range(num_images//batch_size):
download_batch(df, batch_size=batch_size, start_index=i*batch_size)
Carregamento e Visualização dos Dados
Depois de fazer o download das imagens em uma pasta images, podemos carregar as imagens e suas legendas como um Dataset no FiftyOne:
dataset = fo.Dataset(name="gcc", persistent=True)
dataset.add_sample_field("caption", fo.StringField)
samples = []
for i in tqdm(range(num_images)):
caption, uh = df.iloc[i]['caption'], df.iloc[i]['url_hash']
filepath = f"images/{uh}.jpg"
sample = fo.Sample(
filepath=filepath,
caption=caption
)
samples.append(sample)
dataset.add_samples(samples)
O código cria um Dataset chamado "gcc", que é persistido no banco de dados subjacente e, em seguida, itera sobre as primeiras linhas num_images do DataFrame pandas, criando uma amostra (Sample) com o caminho do arquivo e a legenda apropriados.
Para este passo a passo, fiz o download das primeiras 310.000 imagens, aproximadamente.
O primeiro passo que devemos dar ao inspecionar um novo conjunto de dados de visualização computacional é visualizá-lo! Podemos fazer isso iniciando o aplicativo FiftyOne:
session = fo.launch_app(dataset)
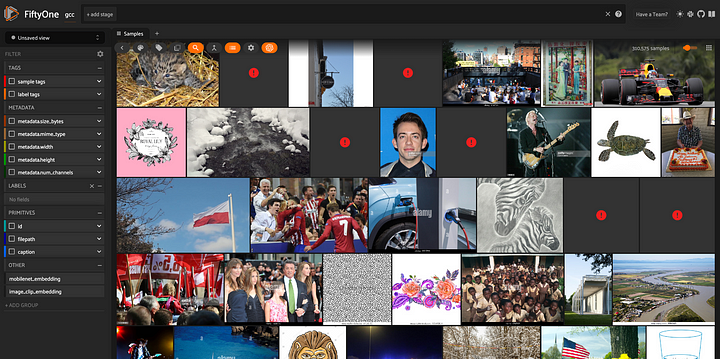
Todas as mais de 310.000 imagens extraídas do conjunto de dados do Conceptual Captions do Google, visualizadas no aplicativo FiftyOne.
Remoção das Amostras Corrompidas
Quando examinamos os dados, podemos ver imediatamente que algumas das imagens não são válidas. Isso pode ser devido a links que não estão mais funcionando, interrupções durante o download ou algum outro problema completamente diferente.
Felizmente, podemos filtrar facilmente essas imagens inválidas. No FiftyOne, o método compute_metadata() computa metadados específicos do tipo de mídia para cada amostra. Para amostras baseadas em imagens, isso inclui a largura, a altura e o tamanho da imagem em bytes.
Quando o arquivo de mídia não existir ou estiver corrompido, os metadados serão considerados nulos. Assim, podemos filtrar as imagens corrompidas executando compute_metadata() e associando com as amostras em que os metadados existem:
dataset.compute_metadata()
## view containing only valid images
view = dataset.exists("metadata")
session = fo.launch_app(view)
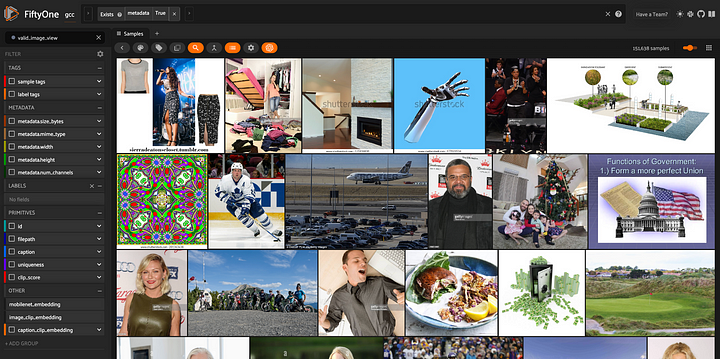
DatasetView contendo apenas as imagens não corrompidas e seus metadados.
Filtro pela Proporção de Tela
Um próximo passo que podemos querer dar é filtrar as amostras com proporções de tela incomuns. Se o nosso objetivo for controlar os resultados de um modelo de difusão, provavelmente só trabalharemos com imagens dentro de um determinado intervalo de proporções de tela razoáveis.
Podemos fazer isso usando o ViewField da FiftyOne, que nos permite aplicar expressões arbitrárias aos atributos de nossas amostras e, em seguida, filtrar com base nelas. Por exemplo, se quisermos descartar todas as imagens que são mais de duas vezes maiores em uma dimensão do que na outra, podemos fazer isso com o seguinte código:
from fiftyone import ViewField as F
long_filter = F("metadata.width") > 2*F("metadata.height")
tall_filter = F("metadata.height") > 2*F("metadata.width")
aspect_ratio_filter = (~long_filter) & (~tall_filter)
view = valid_image_view.match(aspect_ratio_filter)
Por uma questão de clareza, esta é a aparência das amostras descartadas:
bad_aspect_view = valid_image_view.match(~aspect_ratio_filter)
session = fo.launch_app(bad_aspect_view)
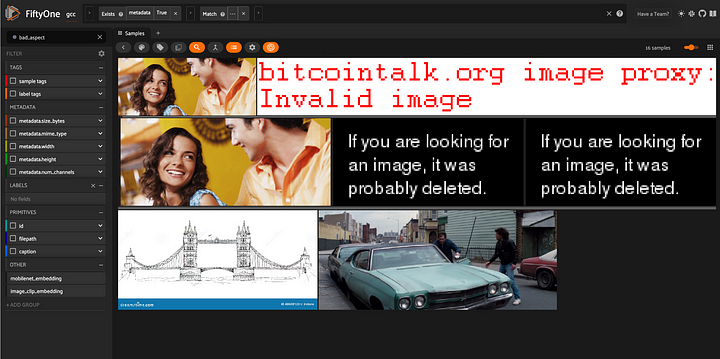 ######Visualização de imagens com proporções atípicas, que removemos dos dados de treinamento.
######Visualização de imagens com proporções atípicas, que removemos dos dados de treinamento.
Se quiser, você pode usar um filtro de proporção de tela mais ou menos rigoroso!
Filtro por Resolução
De forma semelhante, talvez queiramos remover as imagens de baixa resolução. Queremos gerar imagens impressionantes e realistas, portanto, não faz sentido incluir imagens de baixa resolução nos dados de treinamento.
Esse filtro é semelhante ao filtro de proporção de tela. Se selecionarmos 300 pixels como a menor largura e altura permitidas, o filtro terá o seguinte formato:
hires_filter = (F("metadata.width") > 300) & (F("metadata.height") > 300)
view = good_aspect_view.match(hires_filter)
Mais uma vez, você pode escolher os limites que desejar. Para maior clareza, aqui está uma visualização representativa das imagens descartadas:
lowres_view = good_aspect_view.match(~hires_filter)
session = fo.launch_app(lowres_view)
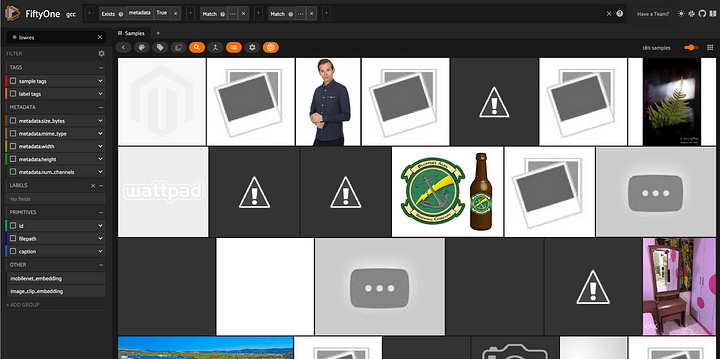
Visualização de imagens pequenas e imagens com baixa resolução, que são removidas dos dados de treinamento.
Garantia da Paleta de Cores
Observando as imagens de baixa resolução, também podemos nos lembrar de que algumas das imagens em nosso conjunto de dados estão em escala de cinza. Provavelmente queremos gerar imagens que sejam o mais vibrantes possível, portanto, devemos descartar as imagens em preto e branco.
No FiftyOne, um dos atributos registrados nos metadados da imagem é o número de canais: as imagens coloridas têm três canais (RGB), enquanto as imagens em escala de cinza têm apenas um canal. Remover imagens em escala de cinza é tão simples quanto fazer a correspondência de imagens com três canais!
## imagens coloridas para serem mantidas
view = view.match(F("metadata.num_channels") == 3)
## imagens cinza para serem descartadas
gray_view = view.match(F("metadata.num_channels") == 1)
session = fo.launch_app(gray_view)
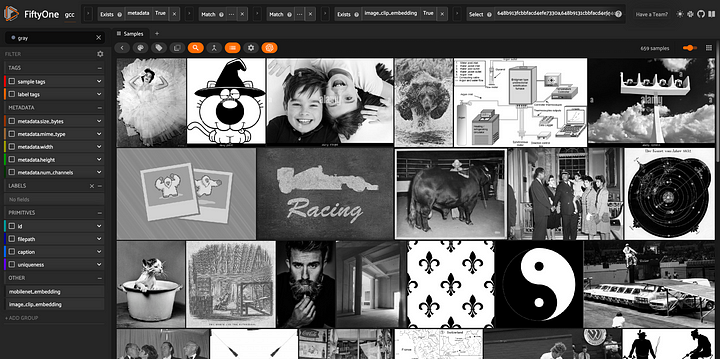
Visualização do conjunto de dados que consiste em imagens em escala de cinza, que são posteriormente removidas dos dados de treinamento.
Deduplicação do Conjunto de Dados
Nossa próxima tarefa em busca da limpeza de dados é remover imagens duplicadas. Quando uma imagem é duplicada de forma exata ou aproximada em um conjunto de dados de treinamento, o modelo resultante pode ser influenciado por esse pequeno conjunto de amostras super-representadas, sem mencionar os custos adicionais de treinamento.
Podemos encontrar duplicatas aproximadas em nosso conjunto de dados usando um modelo para gerar embeddings para nossas imagens (usaremos um modelo CLIP como ilustração):
## Carregar o modelo CLIP do modelo Zoo da FiftyOne
model = foz.load_zoo_model("clip-vit-base32-torch")
## Computar embeddings e armazená-los no embeddings_field
view.compute_embeddings(
model,
embeddings_field = "image_clip_embedding"
)
Em seguida, criamos um índice de semelhança com base nesses embeddings:
results = fob.compute_similarity(view, embeddings="image_clip_embedding")
Por fim, podemos definir um limite numérico a partir do qual consideraremos as imagens como aproximadamente duplicadas (aqui escolhemos 0,3) e manteremos apenas um representante de cada grupo de duplicatas aproximadas:
results.find_duplicates(thresh=0.3)
# visualizar as duplicata, emparelhá-las
dup_view = results.duplicates_view()
session = fo.launch_app(dup_view, auto = False)
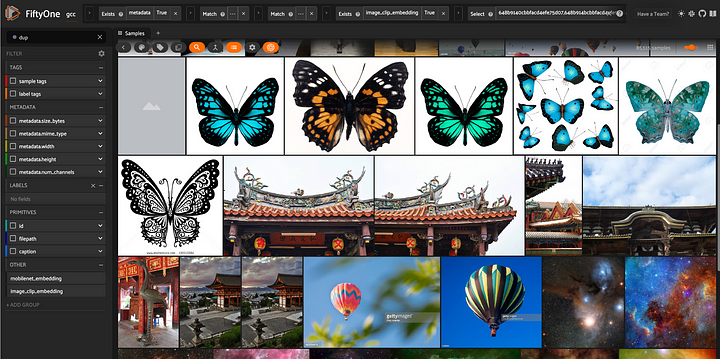
Visualização das duplicatas exatas e aproximadas em nosso conjunto de dados. Para deduplicar os dados, pegamos uma imagem representativa de cada grupo de quase duplicatas, bem como todas as imagens altamente exclusivas.
Validação do Alinhamento da Imagem-Legenda
Ok, agora você está com sorte, pois deixamos a etapa mais legal para o final!
O conjunto de dados Conceptual Captions do Google consiste em pares de legendas de imagens da Internet. Mais precisamente, "as descrições brutas são coletadas do atributo Alt-text HTML associado a imagens da Web". Isso é ótimo como uma passagem inicial, mas é provável que haja algumas legendas de baixa qualidade.
Talvez não possamos garantir que todas as nossas legendas descrevam perfeitamente suas imagens, mas certamente podemos filtrar alguns pares de legendas de imagens mal alinhadas!
Faremos isso com o CLIPScore, que é uma "métrica de avaliação sem referência para legendas de imagens". Em outras palavras, você só precisa da imagem e da legenda. O CLIPScore é fácil de implementar. Primeiro, usamos o método de distância de cosseno de Scipy para definir uma função de similaridade de cosseno:
from scipy.spatial.distance import cosine as cosine_distance
def cosine(vector1, vector2):
return 1. - cosine_distance(vector1, vector2)
Em seguida, definimos uma função que recebe um Sample e calcula o CLIPScore entre o embedding de imagem e o embedding de legenda, armazenada nas amostras:
def compute_clip_score(sample):
image_embedding = sample["image_clip_embedding"]
caption_embedding = sample["caption_clip_embedding"]
return max(100.*cosine(image_embedding, caption_embedding), 0.)
Essencialmente, essa expressão apenas limita a pontuação a zero. O fator de escala 100 é o mesmo usado pelo PyTorch.
Em seguida, podemos calcular o CLIPScore - nossa medida de alinhamento entre imagens e legendas - adicionando os campos ao nosso conjunto de dados e iterando sobre nossas amostras:
dataset.add_sample_field("caption_clip_embedding", fo.VectorField)
dataset.add_sample_field("clip_score", fo.FloatField)
for sample in view.iter_samples(autosave=True, progress=True):
sample["caption_clip_embedding"] = model.embed_prompt(sample["caption"])
sample["clip_score"] = compute_clip_score(sample)
view.save()
Se quisermos ver as amostras "least aligned" (menos alinhadas), podemos classificar por "clip_score".
## 100 amostras menos alinhadas
least_aligned_view = view.sort_by("clip_score")[:100]
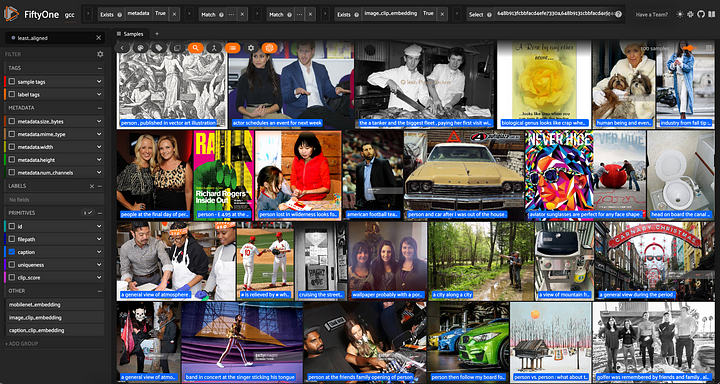
DatasetView exibindo amostras com o menor alinhamento entre imagem e legenda. As legendas são exibidas nas imagens.
Para ver as amostras mais alinhadas, podemos fazer o mesmo, mas passando em reverse=True:
## 100 amostras mais alinhadas
most_aligned_view = view.sort_by("clip_score", reverse=True)[:100]
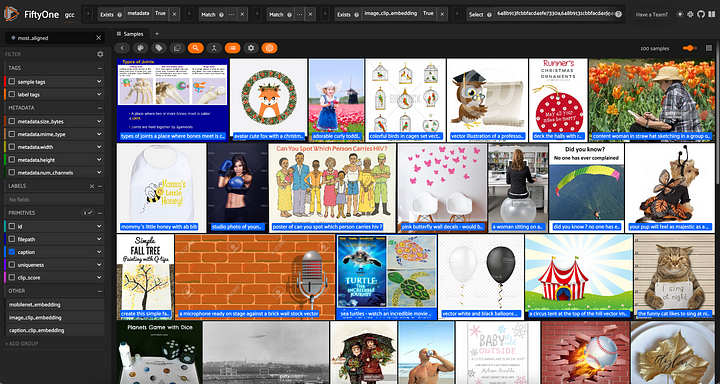
DatasetView exibindo amostras com o maior alinhamento entre imagem e legenda. As legendas são exibidas nas imagens.
Em seguida, podemos definir um limite de CLIPScore, dependendo do alinhamento que exigimos dos pares imagem-legenda. Para o meu gosto, um limite de 21,8 pareceu bom o suficiente:
view = view.match(F("clip_score") > 21.8)
gcc_clean = view.clone(name = "gcc_clean", persistent=True)
A segunda linha clona a exibição em um novo Dataset persistente chamado "gcc_clean".
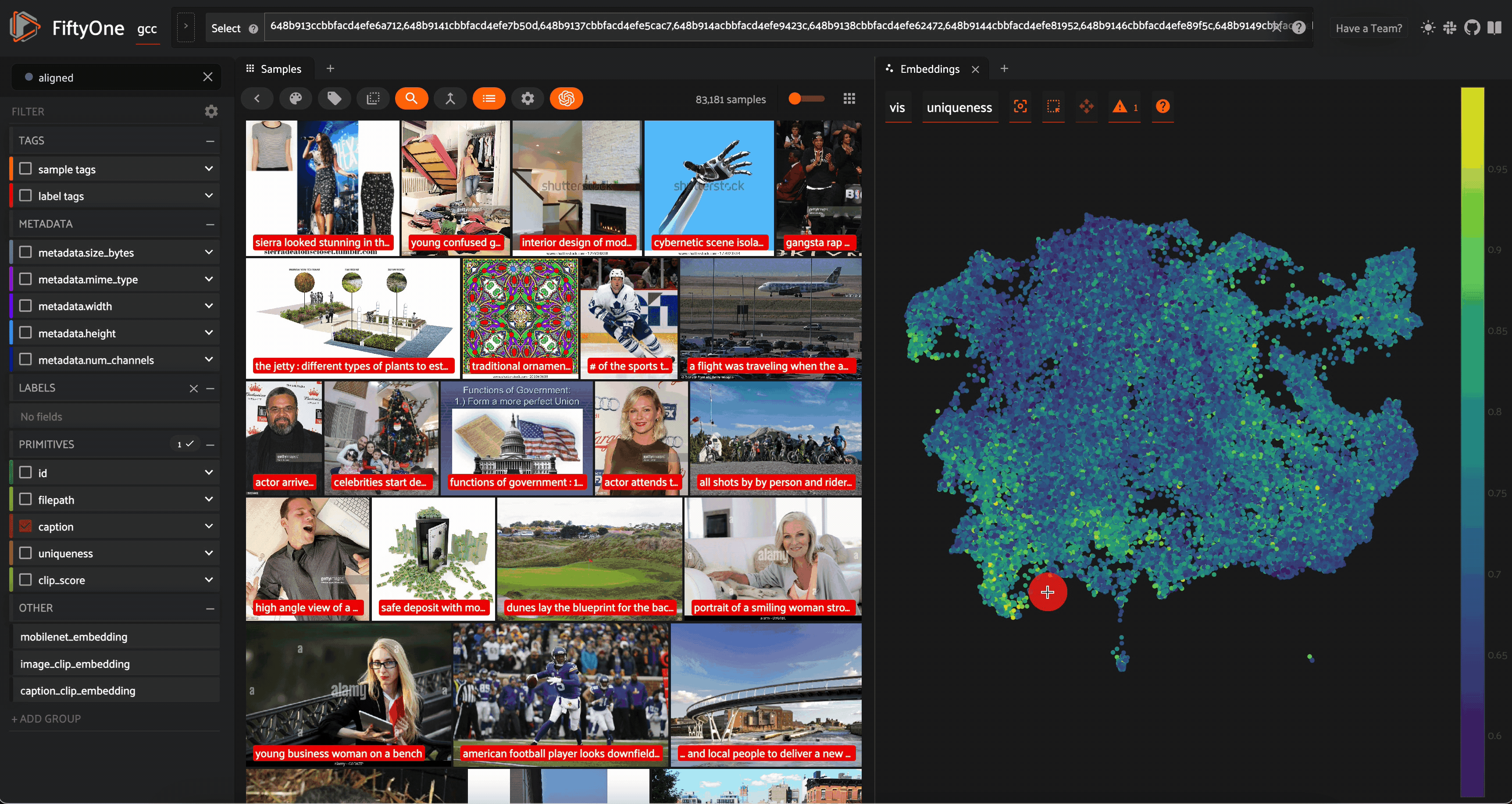
Visualização final exibindo amostras em uma seleção limpa e selecionada do Google Conceptual Captions Dataset.
Conclusão
Depois de nossa limpeza e curadoria de dados, transformamos um conjunto de dados inicial relativamente medíocre de mais de 310.000 amostras em um conjunto de dados de alta qualidade com 83.181 amostras. Os frutos de nosso trabalho são os seguintes:
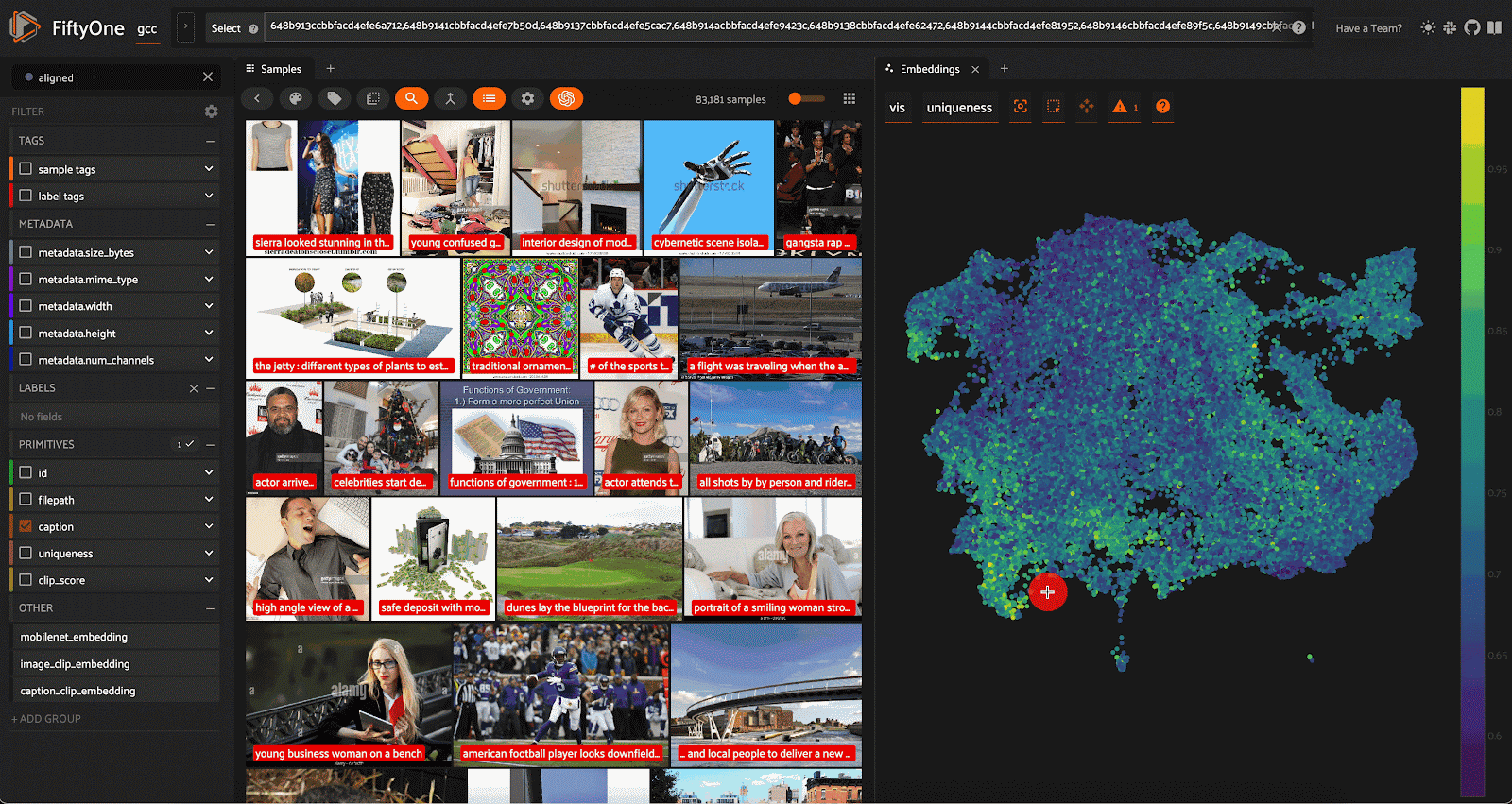
Visualização final exibindo amostras em uma seleção limpa e controlada do Google Conceptual Captions Dataset.
Certamente não criamos um conjunto de dados perfeito - um conjunto de dados perfeito não existe. O que fizemos foi resolver todos os problemas de qualidade de dados que afetavam o ControlNet 1.0, além de alguns outros, só para garantir.
Agora você está pronto para treinar seu próprio modelo ControlNet de última geração!
Nota: esse artigo foi adaptado de uma sessão rápida que apresentei na CVPR na semana passada!
O que vem por aí?
Se você gostou do artigo, talvez também ache interessantes os seguintes artigos:
- AI Telephone — A Battle of Multimodal Models
- CVPR 2023 and the State of Computer Vision
- How I Turned My Company’s Docs into a Searchable Database with OpenAI
Se você gosta da biblioteca de aprendizado automático de código aberto FiftyOne, mostre seu apoio dando ao projeto uma ⭐ no GitHub (3.800 estrelas e continua crescendo!).
Esse artigo foi escrito por Jacob Marks, Ph.D. e traduzido por Fátima Lima. O original pode ser lido aqui.