
Ou: como capturar todos os raros se o ERC721R não está sendo usado!
TLDR: Aqui está um link para o repositório do ERC721R .
Introdução: Abençoado e Sortudo
Mphers foi o primeiro resultado do [mfers] (https://opensea.io/collection/mfers) e, porque ele é também um resultado do Phunks, eu fiquei muito interessado em obtê-lo.
Especificamente, eu queria um alien. Eles parecem os mais legais e só tem 8 numa coleção de 6,969. E eu consegui um!

Embora possa não ter ficado claro no Tweet, o que eu quis dizer foi que eu tive sorte de ter descoberto como garantir 100% que eu conseguiria obter um alien sem necessidade de sorte adicional.
Leia como eu consegui isso, como você pode fazer isso também e, se você for um dev, como você pode evitar que isso aconteça!
Como cunhar raros NFTs sem precisar de sorte
A chave para cunhar um NFT raro é conhecer antecipadamente o id de todo token raro.
Por exemplo, uma vez que eu sabia que o meu token era #4002, tudo que eu precisei fazer foi dar um refresh na página de cunhagem até que eu vi que o #3992 havia sido cunhado e então imediatamente cunhei 10 mphers.
Como eu sabia que o #4002 era um alien? Vamos refazer meus passos.
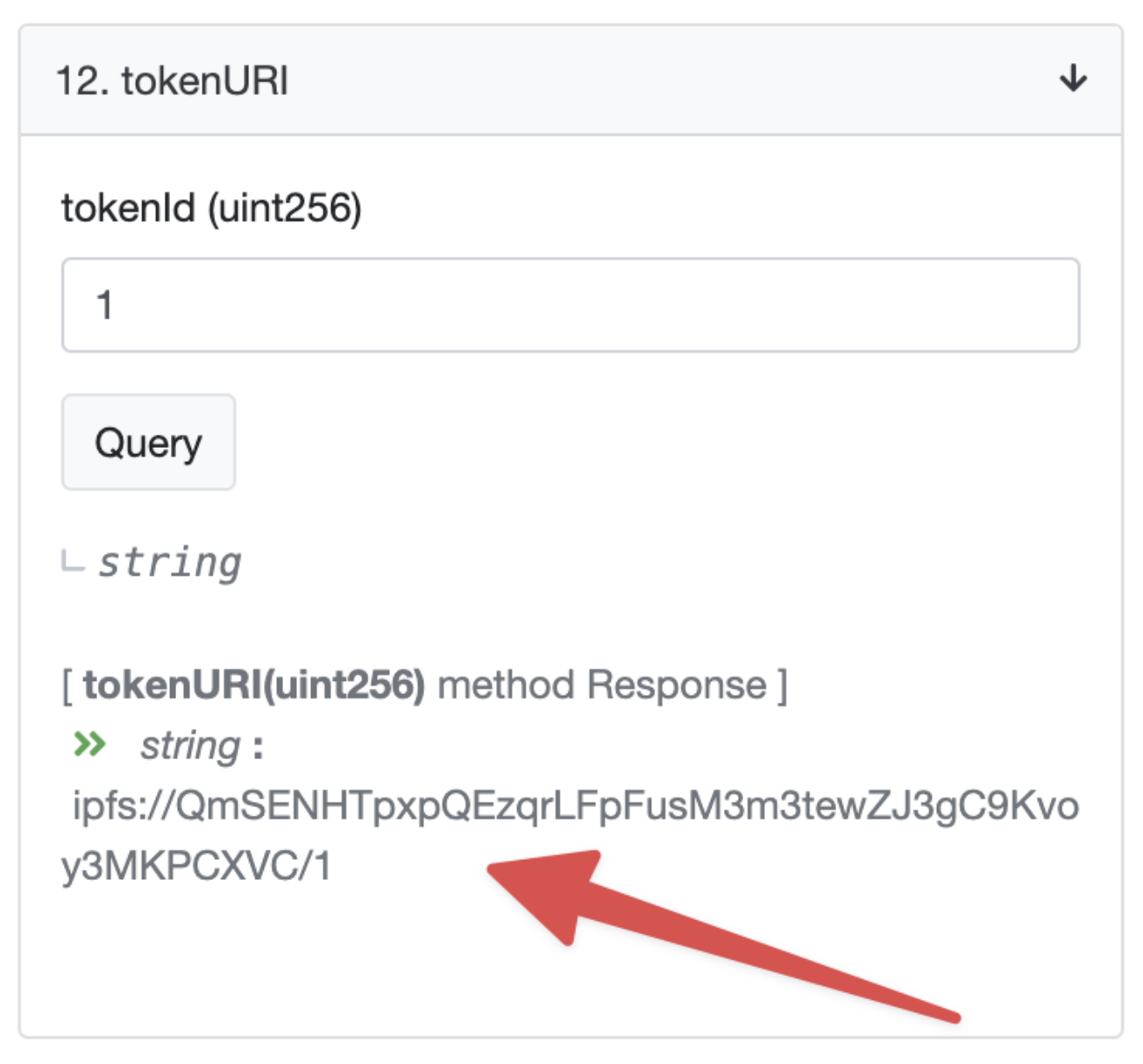
Primeiramente, vá ao página do Etherscan para o contrato mpher e procure o tokenURI de um token que já foi cunhado, token #1:
The template for mpher metadata
Como você pode ver, mphers, como muitos contratos, constrói metadados URIs combinando o id do token com o hash IPFS.
A vantagem dessa abordagem é que ela te dá a procedência da coleção inteira em cada URI e, embora cada URI pode ser alterado, fazer isso afeta todos e é público.
Em contrapartida, imagine se o token URI não contém nenhum hash de origem, por exemplo https://mphers.art/api?tokenId=1. Como colecionador você nunca poderá ter certeza de que os devs não estivessem silenciosamente alterando os metadados do #1 na hora em que eles quisessem.
Contudo, se você tem um API, você pode dizer “if #4002 não foi cunhado, não mostre nenhuma informação sobre isso” e você não pode fazer isso se você vai pelo caminho do IPFS.
Uma vez que os metadados foram revelados (que no caso do mpfers foi instantaneamente), você pode procurar os metadados de qualquer token, tendo ele sido cunhado ou não.
Apenas substitua o rastro “1” no URI acima pelo id que você queira.
Esses arquivos de metadados nos dão todos os atributos do mpher com o id específico. Por exemplo, no caso do meu alien:
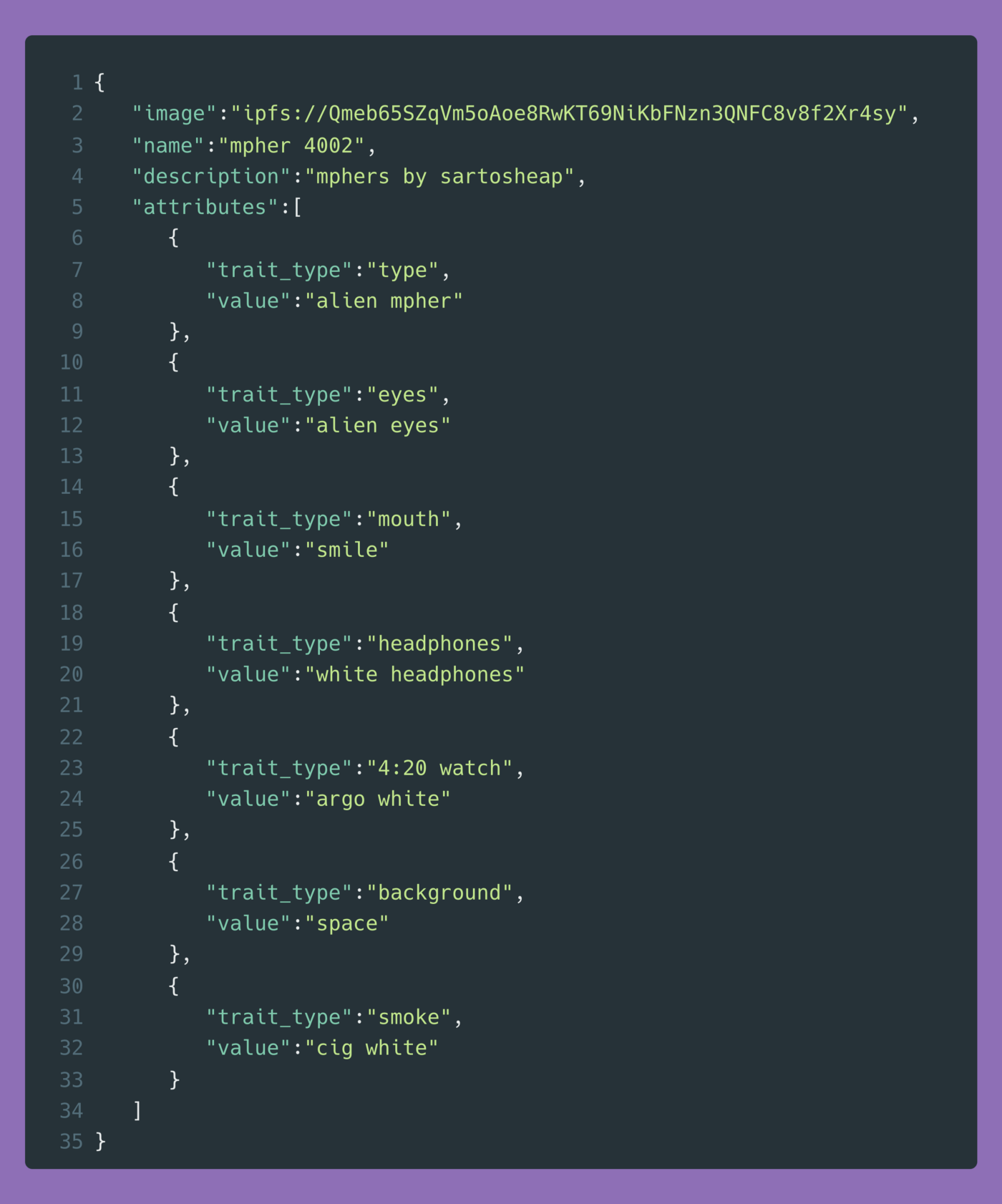
Mpher #4002
Para encontrar os aliens, nós só precisamos pesquisar todos os arquivos de metadados pelo string “alien mpher.”
Depois, faça download dos 6,969 arquivos de metadados. Aqui estou usando o gateway IFPS do OpenSea, mas você pode tentar o ipfs.io ou qualquer outra coisa se funcionar melhor.

Este snippet (pequena região de código fonte reutilizável) usa o curl para fazer o download dos arquivos, 10 de cada vez. Fazer o download de milhares de arquivos rapidamente pode ser maçante, já que você pode acabar em duplicatas ou erros. Mas, se você gastar um tempo com isso, poderá conseguir tudo (e para nossos propósitos dupes não são problemas).
Agora que você tem os arquivos em um diretório, apenas grep pelos aliens:
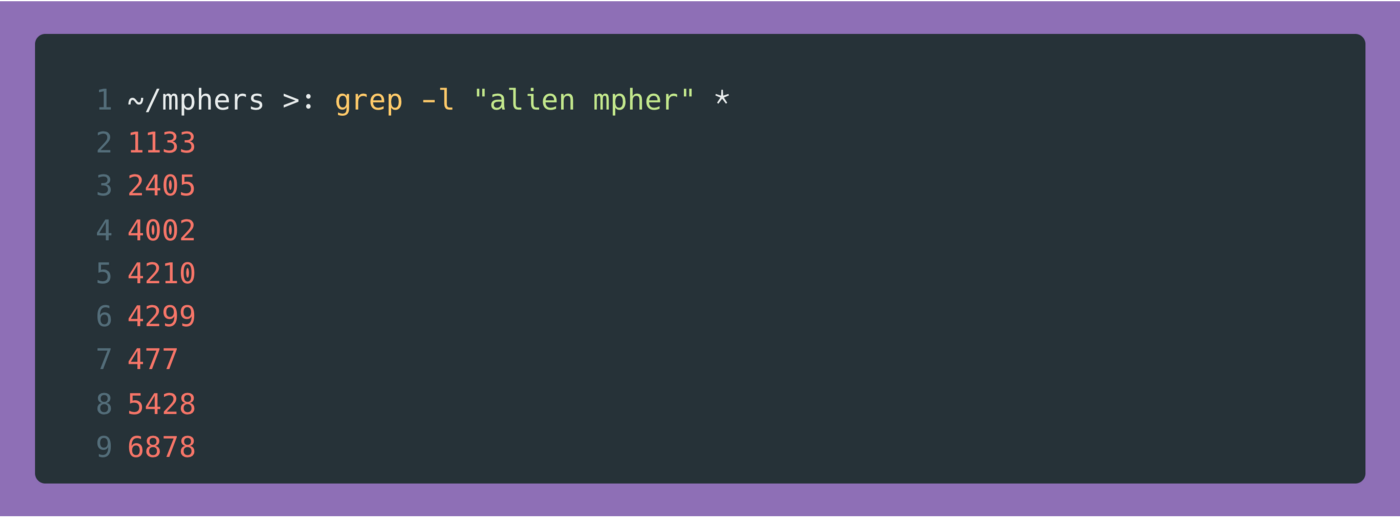
Os números que aparecem são os nomes dos arquivos que contêm “alien mpher” e consequentemente os ids dos próprios aliens.
O processo todo leva menos do que 10 minutos. E você pode usar essa técnica com muitos NFTs que estejam sendo cunhados nesse momento.
Na prática, não é totalmente simples cunhar manualmente num exato momento para conseguir um alien, especialmente quando os tokens estão sendo cunhados rapidamente. Se você realmente quer “ser fera” com essa abordagem, você deve criar um bot para fazer um poll totalSupply() cada segundo e automaticamente enviar a transação de cunhagem no exato momento.
E se você deseja “ser o máximo” você pode procurar o token que você precisa ver no mempool antes que ele seja cunhado e conseguir sua cunhagem no mesmo bloco!
Contudo, em minha experiência, a “grande” abordagem é suficiente para conseguir 99% do tempo—embora, curiosamente, não 100% do tempo.
“Estou sendo enganado nesse tempo todo?”
É uma pergunta que você deve estar se fazendo se você estiver aprendendo sobre isso só agora.
A ideia de que você tinha zero chance de cunhar qualquer coisa que alguém que esteja usando essa técnica também queira é lamentável.
Mas, você não teve nenhuma chance? De certo modo, você teve a mesma chance que todos os outros!
Me pegue como exemplo: Eu mesmo percebi isso usando informação pública e botei para funcionar usando ferramentas open-source. Qualquer pessoa pode fazer isso, e em geral, se você não investigar como funciona um contrato antes de cunhar, você vai se deparar com muitas questões piores do que essa.
A cunhagem mpher foi 100% honesta.
Ainda assim, embora fosse um jogo justo, “snipe the alien” pode não ter sido um jogo que todos quisessem jogar.
Em vez disso, as pessoas poderiam ter se divertido mais jogando o jogo “mint lottery” onde tokens eram distribuídos aleatoriamente e era impossível ganhar uma vantagem sobre alguém que estivesse apenas clicando no botão “mint”.
Como poderíamos fazer isso?
Cunhagem Aleatória Justa
Para Chapéus Punks da Moda, meu objetivo foi criar uma experiência de cunhagem aleatória sem sacrificar a imparcialidade. Na minha visão, uma cunhagem previsível é muito melhor do que uma parcial. Acima de tudo, os participantes devem ser mantidos em pé de igualdade.
Infelizmente, a maneira mais comum de criar uma experiência aleatória—a chamada “revelação” pós-cunhagem—é profundamente injusta. Funciona assim:
- Os metadados do token são inacessíveis durante a cunhagem. Em vez disso, o tokenURI() aponta para o mesmo arquivo em branco JSON para todos os ids.
- Uma vez que todos os tokens são cunhados, o proprietário do contrato atualiza o hash do IPFS para os metadados reais.
- Não tem nenhuma forma de verificar como o proprietário do contrato escolheu quais os ids do token obtiveram quais metadados. E os resultados parecem ser aleatórios.
Aqui, a pessoa que define os metadados tem uma vantagem tremendamente injusta sobre as pessoas que estão cunhando porque eles próprios determinam quem obtém o quê! Ao contrário da cunhagem mpher, aqui está uma situação em que você realmente não tem chance nenhuma de competir.
Mas, e se for um time de devs conhecido, confiável e doxxed com um longo histórico. As revelações são ok, nesse caso?
Não! Ninguém pode ser confiável com esse tipo de poder. Mesmo que alguém não esteja conscientemente tentando trapacear, ele traz vieses inconscientes para a mesa assim como todos os outros. Além disso, eles podem simplesmente cometer um erro e não perceber isso até ser tarde demais.
Você não pode confiar em si mesmo também. Imagine, você faz uma revelação, você se sente muito bem por ter feito corretamente (nada é 100%!) e de alguma forma você acaba com o NFT mais raro. Isso não seria um pouco estranho? Tem certeza de que você merece isso? Pessoalmente, como um desenvolvedor de NFT, eu não gostaria de estar nessa situação.
A conclusão é essa: revelações são ruins*
A NÃO SER QUE:* elas sejam feitas trustlessly (sem confiabilidade), o que quer dizer que qualquer pessoa pode verificar a honestidade deles sem ter que confiar nos devs (o que você nunca deve fazer).
Para obter uma revelação trustless, você precisa de uma maneira de provar que a revelação foi honesta—normalmente fazendo com que a revelação aconteça on-chain e que seja alimentada por uma aleatoriedade que esteja comprovadamente fora do controle de qualquer pessoa (por exemplo, por meio do Chainlink).
Tubby Cats fez um grande trabalho numa revelação como essa e eu recomendo que você verifique o contrato deles e comece a fazer reflexões. A revelação deles também foi interessante no que diz respeito a ser progressiva—você não precisou ter que esperar até o fim para saber o que você obteve.
A desvantagem da trustlessness (falta de confiabilidade) em geral, é que ela é extremamente difícil de dar certo—@DefiLlama disse isso em suas reflexões iniciais:
Ao escrever o contrato eu o fiz com o mínimo de confiança possível, removendo o máximo possível de confiança no time.
A razão para isso foi que eu acredito que seja importante para cada participante saber as regras do jogo e saber que elas não serão mudadas no meio do jogo (todos devem ter informação completa para tomar decisões, se os métodos são mudados no meio, isso cria grupos de pessoas com informação privilegiada), ao passo que a minimização da confiança seja importante porque essa é toda a razão de ser dos smart contracts (e isso torna impossível hackear mesmo que o time esteja comprometido). Entretanto, isso foi um grande erro, já que reduziu consideravelmente nossa flexibilidade e as ações que poderíamos executar para corrigir coisas que viessem a acontecer.
E @DefiLlama é um desenvolvedor de primeira linha. Se maximizar trustlessness (falta de confiabilidade) deu tanta dor de cabeça para ele, imagine o que faria com você!
Consequentemente, minha recomendação é que se use uma solução pior que ainda seja suficiente em 99% dos casos e que seja mais fácil de implementar: assinaturas aleatórias de token.
Entre em ERC721R: Uma implementação completamente compatível do ERC721 que seleciona ids de token pseudo-aleatoriamente
ERC721R implementa o inverso de uma revelação: ao invés de cunhar os ids do token deterministicamente e assinar metadados aleatoriamente, nós cunhamos os ids do token aleatoriamente e assinamos metadados deterministicamente.
Isso nos permite revelar todos os metadados antes de cunhar enquanto ainda minimiza oportunidades de snipe.
Para usá-lo, copie o contrato no diretório do seu projeto (desculpe-me, nenhum pacote NPM ainda), import (importe-o) e use esse código:

Como o ERC721R funciona?
Primeiramente, uma isenção de responsabilidade: ao contrário de uma revelação trustless, ERC721R não é realmente aleatória. Nesse sentido, ele cria o mesmo “jogo” que vimos na situação do mpher em que cunhadores podem usar informação disponível publicamente para competir para fazer exploit da cunhagem. Entretanto, no caso do ERC721R, o jogo é significativamente mais difícil.
A fim de jogar ERC721R, você precisaria ser capaz de predizer o valor de um hash com esses inputs:
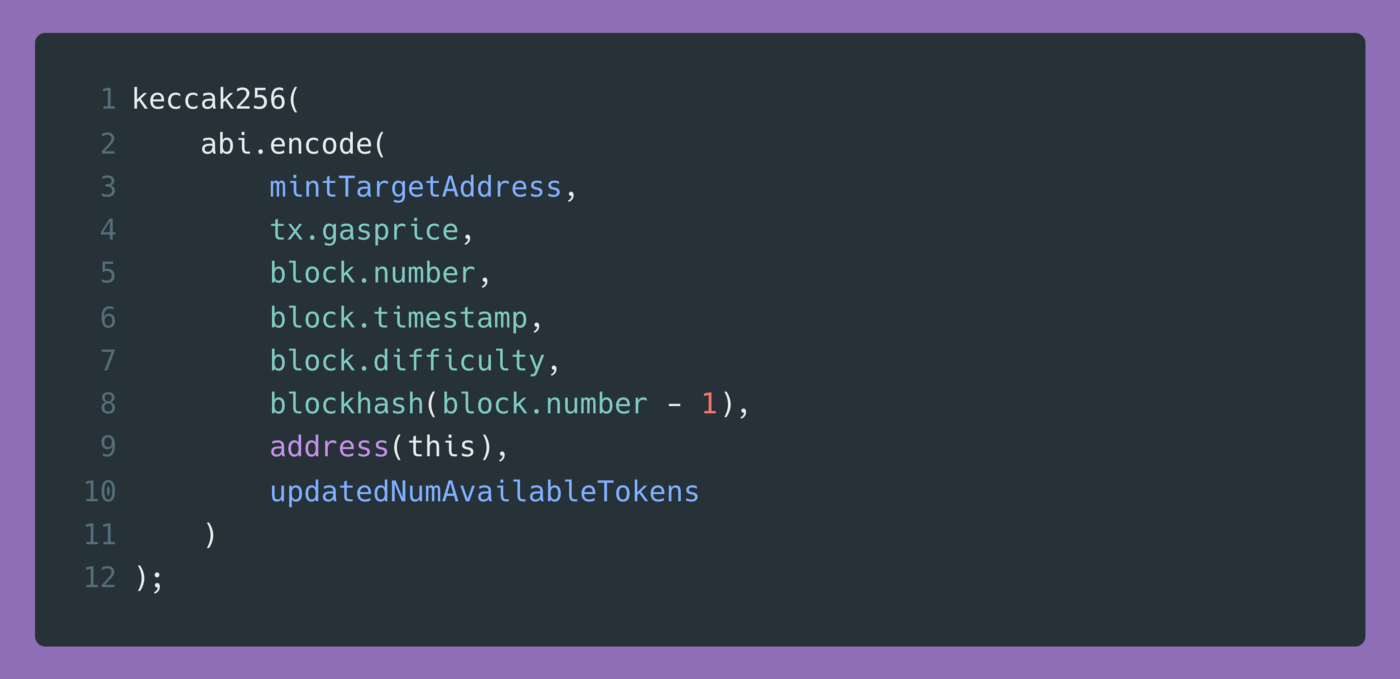
Para uma pessoa comum, isso é impossível porque requer conhecer o timestamp do bloco da sua cunhagem e você não tem acesso à essa informação.
Um minerador que tem controle sobre o momento em que os blocos são minerados (e consequentemente pode influenciar o timestamp) teoricamente pode fazer isso, mas mesmo assim eles têm que definir o timestamp para um valor no futuro e tudo o que eles estejam fazendo depende do hash do bloco anterior que expira em aproximadamente 10 segundos quando o próximo bloco é minerado.
Acredito que essa pseudo-aleatoriedade é “boa o suficiente”, mas se tiver muito dinheiro em jogo, ele será jogado com 100% de certeza, então tenha cuidado! Naturalmente o sistema que ele está substituindo—cunhagem previsível—será também jogado.
A própria seleção do id do token acontece em uma implementação bastante inteligente da versão moderna do algoritmo shuffle Fisher–Yates que eu copiei do CryptoPhunksV2.
Para entendê-lo, primeiramente considere a solução ingênua: (a solução abaixo assume uma coleção de 10,000 itens)
- Crie uma array contendo os números 0–9999.
- Quando você quiser cunhar um token, selecione aleatoriamente um item da array e use este valor como o id do seu token.
- Remova este valor da array e reduza seu comprimento de 1, de forma que todo índice na array menor corresponda a um id de token disponível.
Isso funciona, mas custa muito gas porque mudar o comprimento da array e armazenar uma array enorme cheia de valores diferentes de zero é caro.
Como podemos evitar isso? E se ao invés disso começássemos com uma array contendo 10,000 zeros, o que é barato de criar. Agora vamos usar cada índice nessa array para representar um id.
Suponha que escolhemos o índice #6500 aleatoriamente—#6500 seria nosso id do token e indicaríamos o índice #6500 que já foi usado (por exemplo) substituindo o 0 no índice #6500 por um 1.
Mas o que aconteceria se nós escolhêssemos #6500 de novo? Nós verificaríamos um 1, indicando que #6500 foi usado, mas e daí? Não poderíamos “rolar de novo” já que isso tornaria o gas imprevisível e alto, especialmente para as cunhagens posteriores.
A genialidade do moderno Fisher-Yates é que ele nos dá mecanismos de seleção de um id de token disponível 100% do tempo, sem o custo de manter uma lista separada. Aqui está como isso funciona:
- Crie uma array contendo 10,000 zeros.
- Inicialize um uint
numAvailableTokenscom o valor de 10,000. - Pegue um número aleatório entre 0 e
numAvailableTokens — 1 - Suponha que você tenha escolhido #6500—olhe o índice #6500. Se o valor for 0, #6500 é o id do seu próximo token. Se o valor não for zero, o valor no índice #6500 é o id do seu próximo token (começando a ficar estranho!)
- Agora, olhe o último valor na array, que é o valor no índice
numAvailableTokens — 1. Se esse valor for 0, atualize o valor no índice #6500 para o último índice na array (#9999 se for o primeiro token). Se o último valor na array não for zero, atualize o índice #6500 para armazenar esse valor final diferente de zero. - Reduza
numAvailableTokensde 1. - Repita os itens de 3 a 6 para obter o próximo id de token disponível.
E aí você tem! A array continua do mesmo tamanho e ainda podemos escolher seguramente um id disponível. Aqui está o código Solidity:
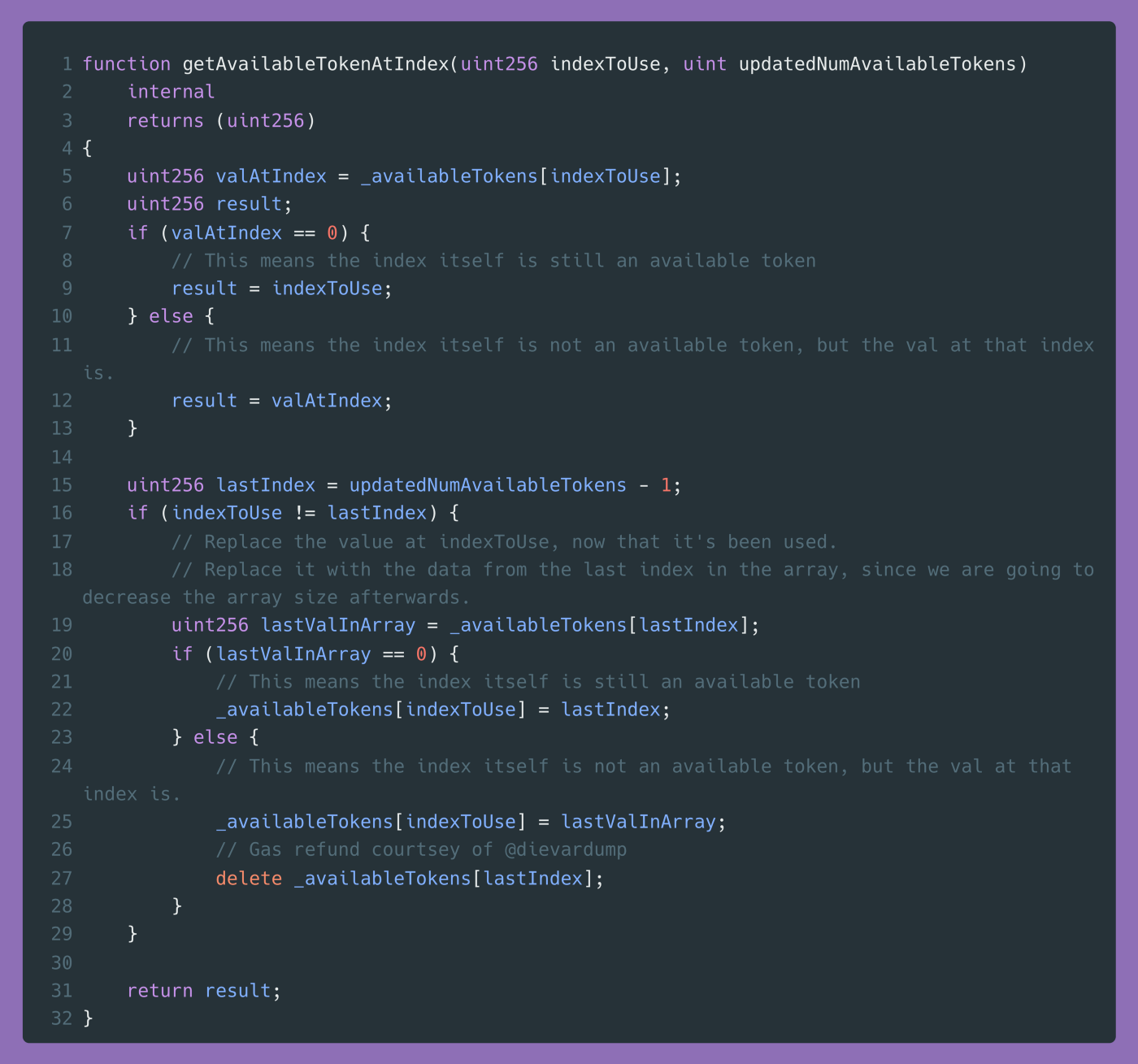
Infelizmente, esse algoritmo ainda usa significativamente mais gas do que a principal solução de cunhagem sequencial, ERC721A.
Isso fica mais pronunciado ao cunhar vários tokens numa transação—exemplo, uma cunhagem de 10 tokens custa aproximadamente 5x mais no ERC721R do que no ERC721A. Dito isso, o ERC721A foi otimizado muito mais do que ERC721R de forma que há espaço para implementação.
Conclusão
Aqui estão suas opções:
ERC721A: Cunhadores pagam menos gas mas têm que gastar tempo e energia planejando e executando uma estratégia de cunhagem competitiva ou se sentir confortável com os resultados piores de cunhagem.
ERC721R: Gas mais alto, mas a estratégia de cunhagem fácil de apenas clicar no botão é ideal em todos os casos, com exceção dos casos extremos. Se os mineradores jogarem o ERC721R é o pior dos dois mundos: gas mais alto e uma tonelada de trabalho para competir.
ERC721A + revelação padrão: Gas baixo, mas honestidade não verificável. Por favor, não faça isso!
ERC721A + revelação trustless: A melhor solução se feita corretamente, altamente desafiadora para os desenvolvedores, potencial para erros difíceis de serem corrigidos.
Eu esqueci alguma opção?! Deixe um comentário ou me dê um toque @dumbnamenumbers no Twitter.
Se você quer aprender mais, vá até o repositório do GitHub e verifique nosso código! As solicitações de pull são mais que bem-vindas—Tenho certeza de que ignorei muitas oportunidades de economia de gas.
Obrigado!
Este artigo foi escrito por middlemarch.eth e traduzido por Fátima Lima. Seu original pode ser lido aqui.