

Resumo
Este artigo fornece uma visão geral da motivação, princípios de design e implementação detalhada da alexandria_bytes. Os códigos da alexandria_bytes foram abertos para a stdlib alexandria da comunidade StarkNet.
A equipe da zkLink usa a linguagem de programação Solidity para contratos inteligentes no ecossistema EVM (Ethereum Virtual Machine ou máquina virtual Ethereum), onde armazenamos estados de transações de múltiplas cadeias usando bytes, e usa funções hash para verificar a consistência dos estados de cadeia cruzada (cross-chain).
A alexandria_bytes é uma solução de código proposta pela equipe da zkLink para expandir as fronteiras comerciais, permitir a compatibilidade entre o ecossistema EVM e o ecossistema Starknet e tratar os desafios de computação de hash.
1. Contexto
1.1 Bytes no Solidity
Os bytes são um aspecto significativo do Solidity, incluindo arrays de tamanho fixo bytesN e arrays de tamanho dinâmico bytes. No Solidity, os bytes suportam diversas operações como comparação, operações bit a bit e acesso ao índice, tornando-os altamente versáteis. Além disso, os bytes servem como entradas para funções hash como keccak256 e sha256, permitindo designs complexos para economizar espaço de armazenamento e permitir verificações de segurança.
1.2 Cairo
Em 2020, a Starkware introduziu Cairo, uma linguagem de programação Turing-completa, marcando um passo significativo no suporte à computação verificável usando STARKs. Em 2023, a Starkware lançou o Cairo 1.0, um grande avanço nas capacidades do Cairo. No entanto, o Cairo, sendo uma linguagem relativamente nova, não suporta totalmente o tipo bytes. Essa limitação impede os desenvolvedores do ecossistema EVM de migrar aplicações maduras para Starknet e restringe a criatividade dos desenvolvedores nativos do Cairo.
1.3 Modelo de Memória do Cairo
O suporte inadequado a estruturas de dados complexas, como bytes, no Cairo pode ser atribuído a dois motivos:
- O histórico de desenvolvimento relativamente curto do Cairo, uma vez que não atingiu todo o seu potencial, apesar das contribuições ativas da comunidade.
- O modelo de memória do Cairo.
Tanto no Cairo quanto no Cairo 1.0, o modelo de memória da linguagem Cairo permanece inalterado. O Cairo suporta uma memória não determinística somente leitura, onde o valor de cada célula de memória é escolhido pelo provador, mas não pode ser alterado durante a execução de um programa Cairo. Em outras palavras, uma vez inicializado, o valor da memória do Cairo não pode ser alterado até ser desalocado. Isso significa que os tipos de dados que requerem atualizações após a inicialização, como dicionários e bytes, têm implementações mais complexas no Cairo, incorrendo em maior sobrecarga de tempo e espaço.
1.4 bytes_array
bytes_array é uma solução de fluxo de bytes fornecida na corelib Cairo 1.0. As motivações por trás de alexandria_bytes e bytes_array são diferentes:
- bytes_array: usa bytes31 para armazenamento de dados, com o objetivo de solucionar problemas de armazenamento com fluxos de bytes no Cairo.
- alexandria_bytes: usa
u128para armazenamento de dados e tem como objetivo resolver desafios de computação de hash para estruturas de dados complexas e fluxos de bytes.
2. Projeto Detalhado de alexandria_bytes
2.1 Visão Geral do Projeto
alexandria_bytes é uma implementação escrita em Cairo 1 pela equipe zkLink, semelhante ao Solidity bytes. É notável por sua implementação integrada das funções de hash Keccak e Sha256, oferecendo conveniência para ajudar os desenvolvedores a migrar contratos EVM escritos em Solidity para Cairo1, conectando assim os ecossistemas EVM ao ecossistema Starknet. A alexandria_bytes é uma implementação do Solidity Bytes no Cairo 1, possuindo os seguintes recursos principais:
- Usa armazenamento big-endian.
- Fornece uma interface rica e fácil de usar, suportando operações como atualização, acesso indexado, acesso a intervalos indexados e concatenação.
- Suporta hashes Keccak256 e Sha256.
- Utiliza espaço para trocar por tempo, economizando custos de gás na cadeia.
Ao longo do restante deste artigo, nos referiremos a alexandria_bytes como “bytes” por questões de brevidade.
2.2 Design de Estrutura de Dados
A estrutura de dados para alexandria_bytes é definida da seguinte forma:
const BYTES_PER_ELEMENT: usize = 16;
#[derive(Drop, Clone, PartialEq, Serde)]
struct Bytes {
size: usize,
data: Array<u128>
}
A partir do código, pode-se observar que bytes é um array dinâmico de u128, composto por duas variáveis de membro: size, indicando o número de bytes no objeto Bytes, e data, contendo os dados reais dos Bytes.
O design da estrutura de dados dos bytes apresenta três características principais:
- Utiliza armazenamento big-endian.
- Usa u128 para armazenar dados, com cada elemento de dados capaz de armazenar 16 bytes.
- Preenche automaticamente com zeros. Quando os dados não estão alinhados corretamente, operações como
appendpreencherão automaticamente a lacuna com zeros, garantindo o alinhamento.
Por exemplo, considere uma string de 28 bytes Hello bytes, hello Starknet! codificada em bytes hexadecimais big-endian como 0x48656c6c6f2062797465732c2068656c6c6f20537461726b6e657421. Em bytes, seu formato de armazenamento apareceria conforme mostrado abaixo:
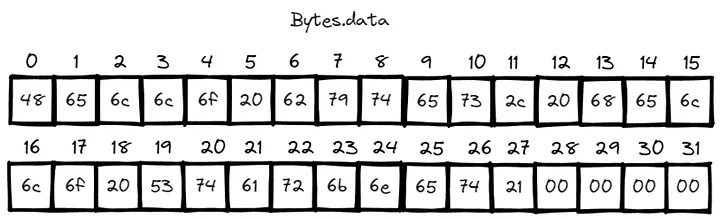
A seguir, discutiremos essas três características de design de bytes e as razões por trás delas.
2.3 Armazenamento Big-Endian
Na computação, a ordem dos bytes refere-se à ordem em que os bytes individuais de um valor de dados de bytes são múltiplos armazenados na memória. Define como a memória do computador ou da máquina armazena dados de bytes múltiplos. Existem duas ordenações de bytes para tipos de dados multi-byte em computadores: little-endian e big-endian.
- Big-endian: o byte superior dos dados é armazenado no endereço de memória mais baixo, enquanto o byte inferior é armazenado no endereço mais alto, semelhante à ordem dos caracteres em uma string.
- Little-endian: o byte inferior é armazenado no endereço de memória mais baixo e o byte superior é armazenado no endereço mais alto, invertendo a ordem dos caracteres.
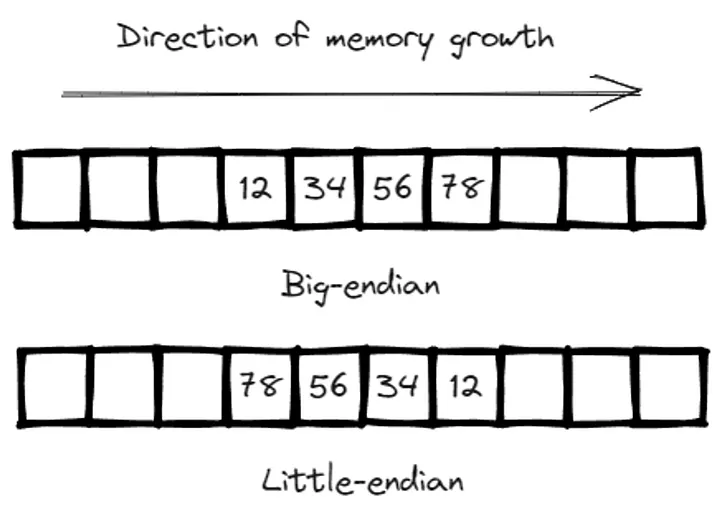
A escolha entre big-endian e little-endian afeta principalmente os cálculos subsequentes da função hash. A corelib do Cairo inclui a função keccak_syscall, que espera entrada no formato little-endian. No entanto, para nos alinharmos melhor com a intuição humana, optamos pelo armazenamento big-endian para bytes.
2.4 Usando u128 para armazenamento de dados
Primeiro, vamos entender os tipos de dados do Cairo. No Cairo, existe apenas um tipo fundamental, felt252, que pode armazenar 252 bits de dados. Outros tipos como u128, bool e ContractAddress são wrappers construídos sobre felt252.
let x: u8 = 1;
Por exemplo, se declararmos uma variável x com valor 1 e um tipo u8, na maioria das linguagens de programação, x ocuparia 1 byte na memória. Porém, no Cairo, x ainda ocupa 252 bits, que é o tamanho de um felt252 na memória.
Diante disso, surge uma questão natural: por que não usar felt252 para armazenar dados em bytes de modo que cada elemento em data possa armazenar 31 bytes, potencialmente economizando espaço de armazenamento? A razão está no cálculo de funções hash, onde a função keccak_syscall espera entrada na forma de Array<u64>.
Suponha que temos um fluxo de bytes de comprimento n. Se o armazenarmos usando Array<u128>, então, ao calcular o hash Keccak desse fluxo de bytes, precisaremos apenas percorrer o fluxo de bytes uma vez, dividindo cada elemento data pela metade. Fazendo isso aproximadamente n/16 vezes, podemos converter o fluxo de bytes em um Array<u64> para o cálculo do hash, resultando em uma complexidade de tempo de O(n/16).
Se, em vez disso, usássemos Array<felt252), com cada elemento em data armazenando 31 bytes, ao calcular o hash Keccak do fluxo de bytes, precisaríamos dividir cada elemento data não apenas cerca de n/16 * 4 vezes (porque cada elemento precisaria ser dividido aproximadamente 4 vezes), mas também realiza uma operação de concatenação entre o final de um elemento e o início do próximo. Isso resulta em uma complexidade de tempo de aproximadamente O(5n/16).
Embora ambas as abordagens de design tenham teoricamente uma complexidade de tempo de O(n), o desempenho e o consumo de gás na prática podem diferir por um fator de 4 a 5. Embora a computação seja muito barata na Starknet, ainda existem limitações quanto ao número de etapas permitidas por transação, mesmo com o limite atual de 3 milhões de passos por transação, conforme descrito na documentação da Starknet. Portanto, em nosso projeto, escolhemos uma abordagem de espaço por tempo para fornecer bytes com mais espaço de compatibilidade.
2.5 Preenchimento Zero
O preenchimento zero é um design de otimização a nível do código. Qualquer operação de acréscimo preenche automaticamente as lacunas com zeros quando os dados não estão alinhados corretamente (a inicialização manual exigiria preenchimento manual de zeros). No exemplo de código abaixo, inicializamos uma string “Hello bytes, hello Starknet!” de duas maneiras:
// Manual
let bytes1: Bytes = BytesTrait::new(
28,
array![
48656c6c6f2062797465732c2068656c,
6c6f20537461726b6e65742100000000
])
// Automático
let mut bytes2: Bytes = BytesTrait::new_empty();
bytes2.append_u128(48656c6c6f2062797465732c2068656c);
bytes2.append_u128_packed(6c6f20537461726b6e657421, 12);
Esse design pode parecer confuso inicialmente, mas acreditamos que, depois de se familiarizar com a API de bytes, você esquecerá esse problema.
Por que é que adotamos esse design? Isso ocorre porque o modo big endian dos bytes é essencialmente simulado usando um u128 para armazenar a soma de 16 bytes. Portanto, quando não alinhado corretamente, devido à ausência de bytes de ordem superior, o número real armazenado seria deslocado para a direita por padrão, conforme mostrado no diagrama abaixo:
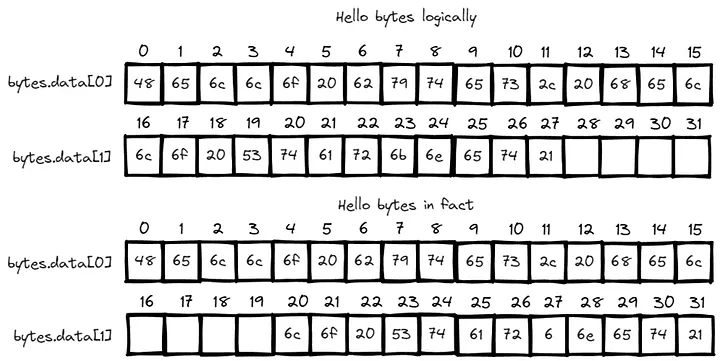
Consequentemente, sem preenchimento de zeros, qualquer operação em bytes, como acesso indexado ou atualizações, exigiria lógica de código adicional para lidar com o não alinhamento do último elemento. Isso não apenas complica o código, mas também aumenta o tempo de execução durante a computação. Com a estratégia de preenchimento automático de zeros, conseguimos um código mais conciso.
Conclusão
Em comparação com bytes_array e bytes31 no corelib do Cairo, alexandria_bytes é uma biblioteca projetada para enfrentar desafios de computação hash para estruturas de dados complexas e fluxos de bytes no Cairo, em vez de focar no armazenamento. Embora alexandria_bytes ofereça um conjunto mais extenso de interfaces de leitura e gravação, você deve escolhê-lo com base no seu caso de uso específico.
A zkLink tem trabalhado para preencher a lacuna entre os diferentes ecossistemas e continuará a contribuir para os ecossistemas EVM e Starknet no futuro.
Sobre a zkLink
zkLink é um middleware de negociação multicadeia unificado, protegido com tecnologia de conhecimento zero, revolucionando os futuros produtos de negociação DeFi, NFT e RWA.
Ao conectar várias blockchains de camada 1 (L1) e redes de camada 2 (L2), o middleware ZK-Rollup unificado e multifuncional da zkLink permite que desenvolvedores e comerciantes aproveitem ativos agregados e liquidez de diferentes cadeias e ofereçam uma experiência de negociação multi-cadeia perfeita, contribuindo para um DeFi mais acessível e eficiente. ecossistema para todos.
Site: zk.link|Documentos|Blog|Twitter|Discord
Este artigo foi escrito por zkCarter, zkLink Labs, e traduzido por Isabela Curado Nehme. Seu original pode ser lido aqui.