
 ######Imagem generada pelo DALLE
######Imagem generada pelo DALLE
Este artigo irá guiá-lo através da criação de um modelo de IA (Inteligência Artificial) que pode jogar o popular jogo Dino do Chrome usando o PyTorch e a EfficientNet.
A OpenAI, a organização que desenvolveu o ChatGPT, na verdade começou construindo modelos de IA que podiam rodar jogos do Atari. Este projeto, conhecido como Atari AI, foi uma das primeiras demonstrações de aprendizado por reforço profundo e ajudou a preparar o caminho para muitos avanços subsequentes na IA. Portanto, construir um modelo de IA para jogar o jogo Dino do Chrome faz parte de uma longa tradição de uso de jogos para testar e desenvolver algoritmos de IA.
O jogo Dino do Chrome é um jogo simples, mas viciante, que conquistou os corações de milhões de jogadores em todo o mundo. O objetivo do jogo é controlar um dinossauro e ajudá-lo a correr o mais longe possível sem bater nos obstáculos. Com a ajuda da IA, podemos criar um modelo que pode aprender a jogar e superar nossas pontuações mais altas.
Este tutorial é para qualquer pessoa interessada em construir um modelo de IA que possa jogar. Mesmo se você for novo em IA ou aprendizado profundo, este tutorial será um ótimo ponto de partida.
Usando o PyTorch, um framework popular de aprendizado profundo, e a EfficientNet, uma arquitetura de rede neural de última geração, vamos treinar um modelo para analisar a tela do jogo e tomar decisões com base no que se vê. Vamos começar obtendo os dados necessários, depois processá-los e, finalmente, treinar o modelo. Ao final deste tutorial, você terá uma melhor compreensão do aprendizado profundo e de como treinar seu próprio modelo de IA.
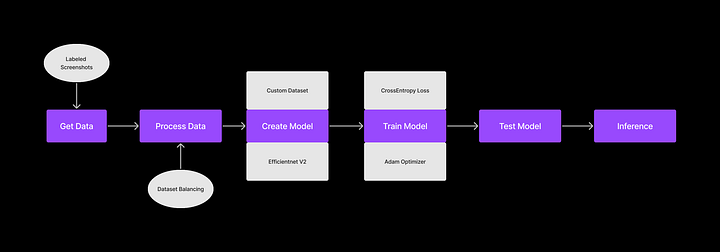
Existem seis etapas principais para configurar um modelo de IA:
- Obtendo os dados;
- Processando os dados;
- Criando o modelo;
- Treinando o Modelo;
- Testando o modelo;
- Inferindo do modelo;
- Instale o Anaconda: baixe e instale a distribuição do Anaconda no site oficial do seu sistema operacional aqui.
- Crie uma nova pasta do projeto. Vamos chamá-la de "dino". Abra o VS Code nesta pasta e abra o terminal.
- Crie um novo ambiente conda: abra o Anaconda Prompt ou seu terminal e crie um novo ambiente conda executando o seguinte comando:
conda create --name myenv python=3.10
Isso criará um novo ambiente chamado myenv com o Python 3.10 instalado.
- Ative o ambiente: uma vez criado o ambiente, ative-o usando o seguinte comando:
conda activate myenv
- Instale o PyTorch: instale a biblioteca PyTorch com suporte CUDA (para aceleração de GPU) usando o seguinte comando:
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch -c conda-forge
- Este comando instala o PyTorch, o TorchVision e o TorchAudio com o conjunto de ferramentas CUDA versão 11.1. Você pode alterar a versão do conjunto de ferramentas CUDA conforme sua necessidade.
- Teste a instalação: para verificar a instalação do PyTorch, execute o seguinte comando para iniciar um interpretador Python em seu ambiente conda:
python
- Em seguida, importe a biblioteca PyTorch e grave sua versão da seguinte forma:
import torch
print(torch.__version__)
Isso deve gravar o número da versão do PyTorch instalado em seu ambiente.
Etapa 1: Obtendo os dados
Obteremos nossos dados tirando fotos (snapshots) da tela do jogo enquanto um jogador humano está jogando. captures.py se encarrega disso.
import cv2
from PIL import ImageGrab
import numpy as np
import keyboard
import os
from datetime import datetime
current_key = ""
buffer = []
# verifique se a pasta chamada 'captures' existe. Se não existir, crie-a.
if not os.path.exists("captures"):
os.mkdir("captures")
def keyboardCallBack(key: keyboard.KeyboardEvent):
'''
Essa função é chamada quando ocorre um evento de teclado. Ela armazena a tecla pressionada em um buffer e a classifica.
### Arguments :
`key (KeyboardEvent)`
### Returns :
`None`
### Example :
`keyboardCallBack(key)`
'''
global current_key
if key.event_type == "down" and key.name not in buffer:
buffer.append(key.name)
if key.event_type == "up":
buffer.remove(key.name)
buffer.sort() # Arrange the keys pressed in an ascending order
current_key = " ".join(buffer)
keyboard.hook(callback=keyboardCallBack)
i = 0
while (not keyboard.is_pressed("esc")):
# Capture a imagem e salve-a na pasta "capturas" com hora e data, juntamente com a tecla pressionada
image = cv2.cvtColor(np.array(ImageGrab.grab(
bbox=(620, 220, 1280, 360))), cv2.COLOR_RGB2BGR)
# se a tecla pressionada incorporar a tecla pressionada no nome do arquivo
if len(buffer) != 0:
cv2.imwrite("captures/" + str(datetime.now()).replace("-", "_").replace(":",
"_").replace(" ", "_")+" " + current_key + ".png", image)
# se nenhuma tecla for pressionada, insira 'n' no nome do arquivo
else:
cv2.imwrite("captures/" + str(datetime.now()).replace("-",
"_").replace(":", "_").replace(" ", "_") + " n" + ".png", image)
i = i+1
Este código registra capturas de tela (screenshots) e as salva como arquivos PNG em um diretório especificado. As capturas de tela são feitas usando as bibliotecas Python PIL (Python Imaging Library) e OpenCV, e são capturadas usando o módulo ImageGrab. As coordenadas da região para registrar as capturas de tela são especificadas usando o argumento bbox (caixa delimitadora) no ImageGrab.grab. Você pode querer mexer com os valores bbox com base em sua escala de exibição.
O programa também captura eventos de teclado usando a biblioteca de teclados. Quando uma tecla é pressionada, o nome da tecla é anexado a um buffer. Quando a tecla é liberada, o nome da tecla é removido do buffer. O estado atual do buffer é salvo como uma string na variável current_key.
O programa salva cada captura de tela com um nome de arquivo que contém o valor atual de i (um número inteiro que é incrementado a cada iteração do loop) e o estado atual do buffer (conforme salvo em current_key). Se nenhuma tecla for pressionada quando a captura de tela for feita, o nome do arquivo incluirá “n” em vez de um nome de tecla.
Esse código pode ser usado como ponto de partida para criar um conjunto de dados de imagem para projetos de aprendizado de máquina, como reconhecimento de objetos ou classificação de imagens. Ao capturar imagens e rotulá-las com as teclas correspondentes pressionadas, pode ser criado um conjunto de dados que pode ser usado para treinar um modelo de aprendizado de máquina para reconhecer as imagens e prever as teclas correspondentes a serem pressionadas.
Acesse https://chromedino.com/ e comece a jogar enquanto o script captura as imagens e as salva na pasta “captures”.
Execute este arquivo Python e comece a jogar. Jogue por pelo menos 20 corridas diferentes para obter um bom conjunto de dados.
A imagem capturada deve se parecer com isto:

É assim que a pasta “captures” deve ficar assim que todas as imagens forem capturadas. Você sempre pode reexecutar o script e adicionar mais dados de treinamento.
Etapa 2: Processando os dados
Em seguida, precisamos de um script para processar as imagens capturadas e transformá-las em um conjunto de dados que nosso modelo possa entender. Crie um novo arquivo process.py.
import pandas as pd
import matplotlib.pyplot as plt
import os
import csv
labels = []
dir = 'captures' # diretório para obter as imagens capturadas de
# obtenha os rótulos de cada imagem no diretório
for f in os.listdir(dir):
key = f.rsplit('.', 1)[0].rsplit(" ", 1)[1]
if key == "n":
labels.append({'file_name': f, 'class': 0})
elif key == "space":
labels.append({'file_name': f, 'class': 1})
field_names = ['file_name', 'class']
# grave os rótulos em um arquivo csv
with open('labels_dino.csv', 'w') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=field_names)
writer.writeheader()
writer.writerows(labels)
Neste trecho de código, geramos rótulos para imagens capturadas em um diretório e os gravamos em um arquivo CSV.
Primeiro, definimos um diretório dir que contém as imagens capturadas. Em seguida, iteramos cada arquivo no diretório usando o método os.listdir().
Extraímos o rótulo da classe do nome de arquivo para cada arquivo usando manipulação de string. Se o nome do arquivo terminar com “n”, atribuímos o rótulo 0. Caso contrário, se terminar com “espaço”, atribuímos o rótulo 1.
Em seguida, armazenamos os rótulos em uma lista de dicionários com cada dicionário contendo o nome do arquivo e o rótulo de classe para uma única imagem.
Por fim, usamos o módulo csv para gravar os rótulos em um arquivo CSV chamado labels_dino.csv. Definimos os nomes dos campos para o arquivo CSV e usamos o método DictWriter para gravar os rótulos no arquivo. Primeiro, escrevemos a linha de cabeçalho com os nomes dos campos e, em seguida, usamos o método writerows para gravar os rótulos de cada imagem no diretório para o arquivo CSV.
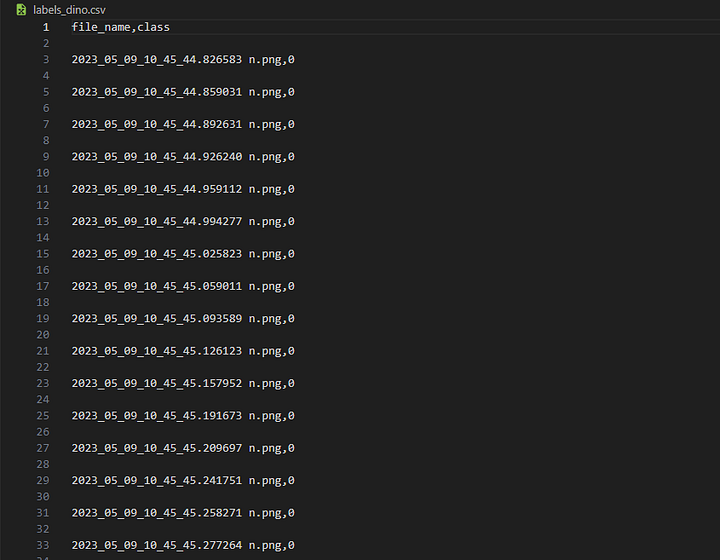
É assim que o arquivo CSV labels_dino deve ficar:
Etapa 3: Criando o Modelo
Ahhh…. a parte divertida da IA... fazer o modelo. Mas espere, precisamos dar alguns passos antes de criar o modelo.
Etapa 3.1. Criando um DinoDataset personalizado
Para criar nosso modelo, primeiro precisamos criar um conjunto de dados Pytorch personalizado. Nós vamos chamar isso de DinoDataset. Comece criando um novo bloco de notas train.ipynb.
Vamos importar todas as dependências:
from torch.utils.data import Dataset, DataLoader
import cv2
from PIL import Image
import pandas as pd
import torch
import os
from torchvision.transforms import CenterCrop, Resize, Compose, ToTensor, Normalize
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
import torchvision.models
import torch.optim as optim
from tqdm import tqdm
import gc
import numpy as np
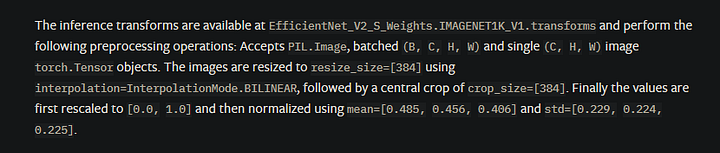
Agora, vamos criar um pipeline (nos permite ter uma visão de todas as fases de um processo) de transformação de imagem necessário para o EfficientNet v2:
transformer = Compose([
Resize((480,480)),
CenterCrop(480),
Normalize(mean =[0.485, 0.456, 0.406], std =[0.229, 0.224, 0.225] )
])
Os valores necessários são fornecidos na documentação do PyTorch da EfficientNet v2.
Agora, vamos criar o nosso DinoDataset:
class DinoDataset(Dataset):
def __init__(self, dataframe, root_dir, transform = None):
"""
Args:
csv_file (string): Caminho para o arquivo csv com anotações.
root_dir (string): Diretório com todas as imagens.
transform (callable, optional): Transformação opcional a ser aplicada em uma exemplo.
"""
self.key_frame = dataframe
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.key_frame)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.to_list()
img_name = os.path.join(self.root_dir, self.key_frame.iloc[idx,0])
image = Image.open(img_name)
image = ToTensor()(image)
label = torch.tensor(self.key_frame.iloc[idx, 1])
if self.transform:
image = self.transform(image)
return image, label
Esta é a definição de uma classe de conjunto de dados personalizado DinoDataset, que herda da classe Dataset PyTorch. Ela requer três argumentos:
dataframe: um dataframe do Pandas contendo os nomes de arquivo e rótulos para cada imagem no conjunto de dados.root_dir:o diretório raiz onde as imagens são armazenadas.transform: uma transformação opcional que pode ser aplicada às imagens.
O método __len__ retorna o comprimento do conjunto de dados, que é o número de imagens.
O método __getitem__ é responsável por carregar as imagens e seus rótulos correspondentes. Ele recebe um índice idx como entrada e retorna a imagem e seu rótulo. A imagem é carregada usando PIL.Image.open, convertida em um tensor PyTorch usando ToTensor, e o rótulo é lido do dataframe usando iloc. Se uma transformação for especificada, ela será aplicada à imagem antes de ser retornada.
Etapa 3.2. Criando DataLoaders de treinamento e teste
key_frame = pd.read_csv("labels.csv") #Importação do arquivo csv com os rótulos dos quadros-chave
train,test = train_test_split(key_frame, test_size = 0.2) #divisão dos dados em conjuntos de treinamento e teste
train = pd.DataFrame(train)
test = pd.DataFrame(test)
batch_size = 4
trainset = DinoDataset(root_dir = "captures", dataframe = train, transform = transformer)
trainloader = torch.utils.data.DataLoader(trainset, batch_size = batch_size)
testset = DinoDataset(root_dir = "captures", dataframe = test, transform = transformer)
testloader = torch.utils.data.DataLoader(testset, batch_size = batch_size)
Neste código, a função train_test_split do scikit-learn é usada para dividir o conjunto de dados em conjuntos de treinamento e teste com um tamanho de teste de 0,2 (20%). As divisões resultantes são armazenadas nas variáveis train e test como DataFrames do Pandas.
Em seguida, um tamanho de lote de 4 é definido e a classe DinoDataset é usada para criar os objetos DataLoader do PyTorch para os conjuntos de treinamento e teste. O argumento root_dir é definido como "captures", que é o diretório que contém as imagens capturadas, e o argumento transform é definido transformer, que é o pipeline de pré-processamento de dados definido anteriormente. Os objetos DataLoader resultantes são trainloader e testloader, que podem ser usados para alimentar os dados da rede neural durante o treinamento e o teste, respectivamente.
Você pode usar valores mais altos de batch_size se tiver acesso a uma GPU de ponta. Por enquanto, vamos usar um tamanho de lote menor.
Vamos verificar as imagens em um dos lotes no dataloader.
dataiter = iter(trainloader)
images, labels = next(dataiter)
for i in range(len(images)):
ax = plt.subplot(2, 4, i + 1)
image = (images[i].permute(1,2,0)*255.0).cpu()
ax.set_title(labels[i].item(), fontsize=20) # Setting the title of the subplot
ax.set_xticklabels([]) # Removendo os rótulos do eixo x
ax.set_yticklabels([]) # Removendo os rótulos do eixo y
plt.imshow(image) # Plotagem de imagem
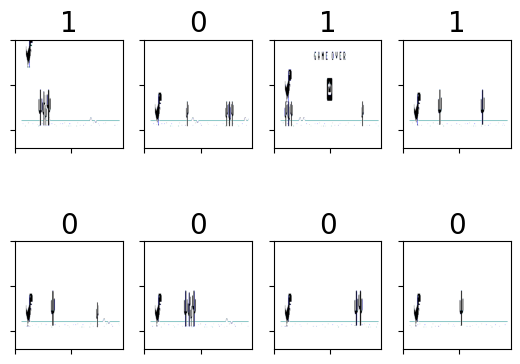
O número em cima de cada imagem mostra a tecla que foi pressionada quando a imagem foi tirada. 1 é para “espaço” e 0 é para nenhuma tecla pressionada.
Etapa 3.3. Criando o modelo
device = "cuda" if torch.cuda.is_available() else "cpu"
model = torchvision.models.efficientnet_v2_s()
model.classifier = torch.nn.Linear(in_features = 1280, out_features = 2)
model = model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.009)
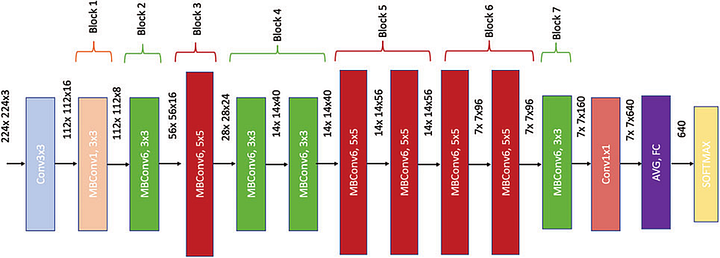
Esse código inicializa um modelo EfficientNetV2-S usando o módulo torchvision do PyTorch e define o número de classes de saída como 2. Em seguida, ele verifica se uma GPU habilitada para CUDA está disponível e define o dispositivo como “cuda” ou “cpu” de acordo. A função de perda usada para treinamento é a função de Perda de Entropia Cruzada (Cross-Entropy Loss) e o otimizador usado é o método de Gradiente Descendente Estocástico, ou Stochastic Gradient Descent (SGD) com uma taxa de aprendizado de 0,01 e momento de 0,009.
A EfficientNetV2-S é uma variante da arquitetura EfficientNet projetada para dispositivos móveis e integrados com recursos computacionais limitados. O tamanho de saída da última camada totalmente conectada no modelo é 1280, que é então alimentado em uma camada linear com dois neurônios de saída representando a tarefa de classificação binária.
Etapa 4: Treinando o modelo
A escolha do otimizador e dos hiperparâmetros como taxa de aprendizado e momento podem ter um impacto significativo no desempenho do modelo durante o treinamento e devem ser ajustados com cuidado para obter os melhores resultados.
epochs = 15 # número de passagens de treinamento nos mini lotes
loss_container = [] # contêiner para armazenar os valores de perda após cada época
for epoch in range(epochs): # repetir o conjunto de dados várias vezes
running_loss = 0.0
for data in tqdm(trainloader, position=0, leave=True):
# obter as entradas; os dados são uma lista de [inputs, labels]
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
# zerar os gradientes dos parâmetros
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
loss_container.append(running_loss)
print(f'[{epoch + 1}] | loss: {running_loss / len(trainloader):.3f}')
running_loss = 0.0
print('Finished Training')
# traçar a curva de perda
plt.plot(np.linspace(1, epochs, epochs).astype(int), loss_container)
# limpar a memória da gpu
gc.collect()
torch.cuda.empty_cache()
Este é o loop de treinamento para o modelo. O loop for itera em um número fixo de épocas (15 neste caso), durante as quais o modelo é treinado no conjunto de dados.
O loop interno for usa um objeto DataLoader para carregar o conjunto de dados em lotes. A cada iteração, as entradas e rótulos são carregados e enviados ao dispositivo (GPU, se disponível). O gradiente do otimizador é zerado e o avanço é executado nas entradas. A saída do modelo é então comparada com os rótulos usando o critério de Perda de Entropia Cruzada (Cross-Entropy Loss). A perda é retropropagada por meio do modelo e o método de etapa do otimizador é chamado para atualizar os pesos do modelo.
A perda é acumulada ao longo da época para obter a perda total. No final da época, o modelo é avaliado no conjunto de testes para verificar seu desempenho em dados não vistos.
Observe que tqdm é usado para exibir uma barra de progresso para cada lote de dados no loop de treinamento.
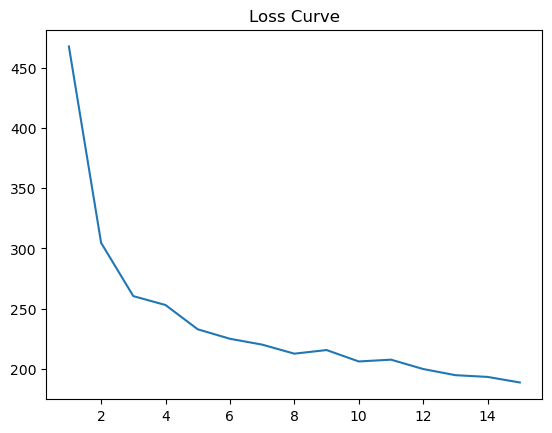
É assim que a curva de perdas se parece. Podemos continuar executando o loop de treinamento por mais épocas.
Também podemos salvar nosso modelo usando o seguinte código:
PATH = 'efficientnet_s.pth'
torch.save(model.state_dict(), PATH)
Etapa 5: Testando o desempenho do modelo
Vamos carregar um novo modelo EfficientNet que usa os pesos que salvamos na última etapa.
saved_model = torchvision.models.efficientnet_v2_s()
saved_model.classifier = torch.nn.Linear(in_features = 1280, out_features = 2)
saved_model.load_state_dict(torch.load(PATH))
saved_model = saved_model.to(device)
saved_mode = saved_model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in tqdm(testloader):
images,labels = data
images = images.to(device)
labels = labels.to(device)
outputs = saved_model(images)
predicted = torch.softmax(outputs,dim = 1).argmax(dim = 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'\\n Precisão da rede nas imagens de teste: {100 * correto // total} %')
Esse código avalia o desempenho do modelo treinado no conjunto de testes.
As variáveis correct e total são inicializadas com 0 e, em seguida, um loop sobre o conjunto de testes é iniciado. O testloader é usado para carregar um lote de imagens e rótulos por vez.
Dentro do loop, as imagens e rótulos são movidos para o dispositivo especificado durante o treinamento (neste caso, "cuda"). O modelo salvo (treinado anteriormente) é usado para prever as imagens de entrada.
A função torch.softmax() é aplicada às saídas do modelo para convertê-las em probabilidades e, em seguida, a função argmax() é usada para determinar a classe prevista para cada imagem. O número de imagens classificadas corretamente é então calculado comparando os rótulos previstos e verdadeiros.
A variável total é incrementada pelo tamanho do lote atual e a variável correct é incrementada pelo número de imagens classificadas corretamente no lote.
Após a conclusão do loop, a acurácia percentual do modelo no conjunto de teste é impressa no console. A precisão para este modelo foi de 91%, o que é bom o suficiente para jogar. Os hiperparâmetros para o otimizador podem ser ajustados com mais experimentação. Ainda há espaço para melhorias. Em meu artigo futuro, vou me aprofundar no ajuste de hiperparâmetros usando a ferramenta de pesos e vieses.
Etapa 6: Inferindo/Jogar o jogo
Crie um novo arquivo dino.py. Execute este arquivo, vá para a tela do jogo Dino e observe seu modelo de IA jogar o jogo.
A primeira parte do código importa as bibliotecas e módulos necessários, incluindo o modelo EfficientNetV2-S do pacote torchvision, a biblioteca de teclado para simular pressionamentos de teclado, a biblioteca PIL para processamento de imagem, numpy para operações numéricas e tqdm para rastreamento de progresso.
O código então carrega o modelo EfficientNetV2-S pré-treinado, adiciona uma nova camada de classificador linear a ele e carrega os pesos treinados do novo modelo de um arquivo de ponto de verificação salvo. O modelo é então movido para a GPU para processamento mais rápido e definido para o modo de avaliação.
A variável transformer define uma série de etapas de pré-processamento de imagem que são aplicadas à imagem da tela capturada antes de ser alimentada no modelo. Essas etapas incluem redimensionar a imagem para um quadrado de tamanho 480x480, cortá-la no centro e normalizar os valores de pixel usando a média e o desvio padrão do conjunto de dados ImageNet.
A função generator é um loop simples que produz um valor vazio até que a tecla "esc" seja pressionada.
O loop for captura continuamente a imagem da tela dentro de uma caixa delimitadora especificada usando a função ImageGrab.grab(). A imagem capturada é então convertida em um tensor PyTorch e movida para a GPU. O transformer é aplicado ao tensor para pré-processar a imagem. Finalmente, a imagem pré-processada é inserida no modelo para obter as probabilidades de saída previstas. A função torch.max() é utilizada para obter o rótulo da classe com maior probabilidade e, se o rótulo previsto corresponder à ação de "pular", a função keyboard.press_and_release() é chamada para simular um pressionamento da barra de espaço, fazendo com que o personagem do jogo salte.
O loop continua até que a tecla “esc” seja pressionada e o processo seja rastreado usando o módulo tqdm. Seu modelo deve ser capaz de jogar o jogo Dino agora. Pelo menos até os pássaros chegarem.
Espero que você tenha se divertido fazendo este projeto e aprendido um pouco sobre o fluxo de trabalho geral de IA para visão computacional. Para atualizações sobre novos artigos e tutoriais, siga-me no Twitter e Linkedin.
Quer se conectar?
Artigo escrito por Akshay Ballal. Traduzido por Marcelo Panegali.