
Uma rápida revisão de tabelas de hash distribuídas e por que elas são uma ideia muito legal!
 ######Foto de Pavan Trikutam no Unsplash
######Foto de Pavan Trikutam no Unsplash
É muito fácil começar a considerar certa ferramenta, algoritmo, ideia ou tecnologia depois de se familiarizar intimamente com ela, usá-la com frequência ou conhecê-la há muito tempo. É igualmente fácil começar a acreditar que, porque você entende bem algo, deve ser simples ou chato. Mas de vez em quando, lembro-me da grandiosidade de uma ferramenta ou algoritmo que perdeu seu brilho para mim ao longo do caminho…
Recentemente, tive o privilégio de participar de uma das melhores explicações de um desses algoritmos (tabelas de hash distribuídas pela Kademlia) que eu já ouvi falar (a explicação de Oli Evans envolveu algumas interpretações práticas e muitos exemplos intuitivos e muito legais), e isso me lembrou de como os sistemas descentralizados 'mágicos' podem ser.
Isso também me inspirou a revisitar alguns dos meus posts antigos, para ter certeza de ter capturado a essência do(s) algoritmo(s). Descobri que havia encoberto muitos detalhes interessantes, então neste artigo — que talvez seja a sequência de um artigo anterior sobre como adicionar dados ao IPFS — gostaria de explorar o que há de tão legal no IPFS DHT.
Tabelas de hash distribuídas
O IPFS e outros sistemas de conteúdo descentralizados usam algo chamado tabela de hash distribuída (DHT) para dar suporte ao roteamento e descoberta de conteúdo e pares na rede. Então, quando você ouve alguém dizer algo como: “consultar a rede”, “perguntar à rede” ou “obter da rede”, o que eles realmente estão dizendo é “consultar a tabela de hash distribuída”. Isso permite que os pares na rede encontrem conteúdo ou pares sem qualquer coordenação centralizada. Já escrevemos sobre tabelas de hash distribuídas no IPFS antes e até escrevemos um pouco sobre o(s) algoritmo(s) DHT subjacente(s) que o IPFS usa.
Como uma rápida atualização, vá para o artigo da Wikipedia para Tabelas de Hash Distribuídas - ele fornece uma ótima visão geral de alguns conceitos principais e também destaca muitos dos benefícios de usar uma DHT. Também nesse artigo, você encontrará esta figura:
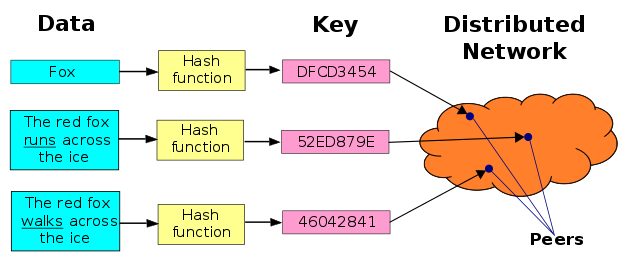
que descreve uma estrutura de dados descentralizada relativamente simples que fornece funcionalidade semelhante a uma tabela de hash básica (busca de chaves rápidas/ par de valores), onde “chaves são identificadores exclusivos que mapeiam para valores específicos, que por sua vez podem ser qualquer coisa, desde endereços, até documentos, a dados arbitrários”. Você também descobrirá que projetos como BitTorrent, IPFS e outros dependem de DHTs para fornecer acesso logicamente centralizado ao conteúdo distribuído fisicamente pela Internet.
Recapitulação rápida: IPFS e projetos semelhantes usam uma DHT (centralizado logicamente) para compartilhar informações sobre quem tem qual conteúdo e de onde ele pode ser recuperado na rede. Conceitualmente bem simples. Mas como exatamente essa estrutura de dados é distribuída entre os pares pode variar muito entre as implementações, então vamos nos aprofundar um pouco mais nesse aspecto do sistema.
DHTs Kademlia
Atualmente, o IPFS usa uma variante de uma DHT Kademlia (confira o whitepaper se quiser se aprofundar nos detalhes) para seu roteamento, etc (em particular, Kademlia com extensões Coral DSHT e S/Kademlia). Para que estejamos todos na mesma página, leia esta ótima visão geral e explicação das DHTs Kademlia. É um pouco mais técnico do que pretendo aqui, mas fornece muito do conhecimento subjacente necessário para apreciar o(s) algoritmo(s). Então vá em frente, leia esse e depois volte aqui para um resumo final.
Ok, obrigado por voltar. Agora, um dos principais recursos da implementação do IPFS do Kad-DHT é que os identificadores de pares (Peer Ids) são mapeados diretamente para os identificadores de conteúdo (Content Ids, ou CIDs) e que os pares realmente armazenam informações sobre onde localizar fisicamente um determinado conteúdo. Isso é ótimo e tudo mais - quero dizer, precisamos saber onde buscar todas aquelas fotos de gatos - mas o que você pode não ‘entender intuitivamente’ do artigo acima (ou várias outras descrições de DHTs Kademlia), é quais pares armazenam quais bits da DHT. Em outras palavras, como decidimos quem armazena um determinado par de chave/valor?
Quem armazena o quê?
Para atribuir pares de valores-chave a pares específicos, a Kademlia conta com a noção de uma distância entre dois identificadores. Em particular, ele usa a distância “Ou exclusivo” (XOR), que é uma métrica geral útil que é barata de calcular (e divertida de dizer). Mas essa não é a parte legal. A parte legal é que, como os identificadores de chaves e de pares têm o mesmo formato e comprimento (o padrão atual no IPFS é um multi-hash baseado em SHA2–256), a 'distância' pode ser calculada entre eles exatamente da mesma maneira que a distância pode ser computada entre um determinado conjunto de pares ou entre um determinado conjunto de CIDs. Isso é legal porque significa que podemos usar esse fato para decidir onde armazenar pares de chave/valor… nós apenas os armazenamos na 'tabela de hash' do(s) par(es) que são XOR próximos à chave que está sendo armazenada. É claro!
Então, em teoria, se eu estou tentando encontrar a localização de um determinado arquivo com o CID QmHash, eu simplesmente preciso encontrar o Par_ com o Id que está mais próximo (na distância XOR) do QmHash. Na prática, talvez não consigamos encontrar o Par com o Peer _Id mais próximo de QmHash, mas será próximo. Conceitualmente, isso funciona primeiro consultando os Pares aos quais estou conectado diretamente para ver se eles têm QmHash, e se não, se eles conhecem algum Par com um Id mais próximo do que o QmHash deles. Continuarei realizando essa consulta à medida que percorro os Pares com IDs cada vez mais próximos de QmHash. Eventualmente, devo acabar em um Par que está relativamente próximo de QmHash, e que está armazenando a localização de conteúdo QmHash. Então, com essa informação em mãos, meu par irá buscar o conteúdo real por trás do QmHash. Feito.
Obviamente, há muito mais acontecendo nos bastidores para fazer essa mágica funcionar. Por exemplo, não é desejável armazenar um determinado par de chave/valor apenas uma vez na DHT, caso contrário, no segundo em que o par que armazena esse par de chave/valor ficar off-line, perderemos essa informação. Atualmente, o IPFS garante redundância suficiente 'colocando' um determinado par de chave/valor na DHT cerca de 20 vezes, espalhado por 20 pares diferentes, todos relativamente próximos da chave de hash fornecida. Novamente, a coisa legal sobre funções de hash, distâncias XOR e Kademlia em geral, é que não há correlação entre conteúdo, Peer Id e valores de hash, então, em geral, esses pares de chave/valor devem ser distribuídos uniformemente aleatoriamente em todos os pares ativos na rede… sem sobrecarregar nenhum par em particular. Como em todas as coisas, não é tão simples assim, já que Kademlia prefere pares de longa duração, mas você entendeu.
O que aprendemos?
Honestamente, não cobrimos nada que não tenha sido dito antes. Mas acho que às vezes a engenhosidade de algo como DHTs Kademlia se perde no labirinto de outros conceitos importantes sobre os quais alguém pode querer aprender quando está aprendendo sobre IPFS em geral. Quero dizer, nós direcionamos gráficos acíclicos, camada sobre camada de protocolos, algoritmos de hash, camadas de criptografia e PKI, e muito mais para enfrentar. Então, espero que você tenha conseguido encontrar algo interessante em como as DHTs (na maioria das vezes) funcionam. Reaprender coisas que você já conhece é uma boa prática, e sei que me beneficiei de fazê-lo recentemente no IPFS Camp. Então, no mínimo, espero que você se inspire – como eu – a revisitar alguns conceitos antigos e talvez redescobrir por que algo que você não valorizou era realmente algo muito legal.
Agradecimentos a Sander Pick
Este artigo foi escrito por Carson Farmer e traduzido por Marcelo Panegali. O original pode ser encontrado aqui.