

Helium, a rede do povo. Foto de Nima Mot, no Unsplash.
Por Thomas de Marchin e Milana Filatenkova
Thomas é cientista de dados sênior na Pharmalex. Ele é apaixonado pela incrível possibilidade que a tecnologia blockchain oferece para tornar o mundo um lugar melhor. Você pode entrar em contato com ele pelo Linkedin ou pelo Twitter.
Milana é cientista de dados na Pharmalex. Ela é apaixonada pelo poder das ferramentas analíticas para descobrir a verdade sobre o mundo ao nosso redor e orientar a tomada de decisões. Você pode entrar em contato com ela pelo Linkedin.
Uma versão HTML deste artigo, com figuras e tabelas em alta resolução, está disponível aqui. O código usado para gerar este artigo está disponível no meu Github.
1. Introdução
O que é a Blockchain: uma blockchain é uma lista crescente de registros, chamados de blocos, que são vinculados usando criptografia. Ela é usada para registrar transações, rastrear ativos e construir confiança entre as partes participantes. Conhecida principalmente pela aplicação do Bitcoin e das criptomoedas, a Blockchain agora é usada em quase todos os domínios, incluindo cadeia de suprimentos, saúde, logística, gerenciamento de identidade… Algumas blockchains são públicas e podem ser acessadas por todo mundo, enquanto outras são privadas. Existem centenas de blockchains com especificações e aplicações próprias: Bitcoin, Ethereum, Tezos…
O que é a Helium: a Helium é uma infraestrutura sem fio (wireless) descentralizada. É uma blockchain que alavanca uma rede global descentralizada de Hotspots (pontos de acesso). Um hotspot é uma espécie de modem com uma antena, para fornecer conectividade de longo alcance (pode chegar 200 vezes mais longe que o Wi-Fi convencional!) entre dispositivos sem fio da “Internet das Coisas” (IoT, ou Internet of Things). Esses dispositivos podem ser sensores de ambiente para monitorar a qualidade do ar ou para fins agrícolas, sensores de localização para rastrear frotas de bicicletas… Explore o ecossistema da Helium aqui. As pessoas são incentivadas a instalar hotspots e se tornar parte da rede ganhando tokens da Helium, que podem ser comprados e vendidos como qualquer outra criptomoeda. Para saber mais sobre a Helium, leia este excelente artigo.
O que é R: a linguagem R é amplamente usada entre estatísticos e mineradores de dados para o desenvolvimento de softwares de análise de dados.
Este é o terceiro artigo de uma série de artigos sobre interação com blockchains usando R. A Parte I focou em alguns conceitos fundamentais relacionados à blockchain, incluindo como ler os dados da blockchain. A Parte II focou em como rastrear as transações de dados de NFTs e visualizá-las. Se você ainda não leu esses artigos, recomendo fortemente que o faça para se familiarizar com as ferramentas e a terminologia que usamos neste terceiro artigo: Parte I e Parte II.
A Helium é um projeto incrível. Ao contrário dos projetos tradicionais relacionados às blockchains, não se trata apenas de finanças, mas tem aplicações no mundo real. É destinado a ajudar a resolver problemas fora do mundo das criptomoedas, o que é incrível! Antigamente, implantar uma infraestrutura de comunicação só era possível para grandes empresas. Graças à blockchain, isso agora está acessível a vários grupos de indivíduos.
Embora exista muito conteúdo disponível sobre o aspecto de cobertura da Helium e como posicionar corretamente sua antena para maximizar seus lucros, pouca coisa está disponível sobre o uso real da rede pelos dispositivos conectados e é isso que gostaríamos de abordar aqui. Neste artigo, nós tentamos examinar um snapshot atual da blockchain da Helium respondendo às seguintes perguntas:
- Qual é o tamanho da rede da Helium?
- Onde os hotspots estão localizados?
- Eles são utilizados ativamente, ou seja, são usados para transferir dados com os dispositivos conectados?
Vamos analisar todos os dados históricos desde o primeiro bloco da blockchain até o mais recente. Vamos gerar algumas estatísticas e dar ênfase à visualização. Eu acredito que não há nada melhor do que um bom gráfico para transmitir uma mensagem.
Para buscar os dados, existem várias possibilidades:
- Configure um ETL (Extract, Transform, Load, ou Extrair, Transformar, Carregar): Esta é a maneira mais flexível de buscar dados, pois você pode escolher como gerenciar o banco de dados. No entanto, isso pode ser complicado, pois para isso, você precisaria (1) configurar um servidor, (2) ter muito espaço em seus discos rígidos (vários TBs para um banco de dados carregado e em execução) e (3) ter seus discos rígidos rápidos o suficiente para poder acompanhar a blockchain (os blocos são constantemente adicionados a uma velocidade rápida). Sobre esse assunto, consulte isso, isso e isso.
- Use a API: Fácil, mas você está limitado no número de linhas que pode baixar. Dado o tamanho da blockchain, isso representará apenas alguns dias. Veja neste link.
- Baixe dados do projeto Dewi ETL: Graças ao Dewi, há um servidor ETL dedicado sendo executado. Uma interface (metabase) também está disponível para navegar e manipular os dados. É possível extrair os dados da interface, mas ela é limitada a 10⁶ linhas. Alternativamente, a equipe disponibilizou extratos CSV em incrementos de 10k/50k blocos, e é isso que vamos usar aqui! Os dados estão disponíveis aqui.
Quando você trabalha com um grande conjunto de dados, as coisas podem ficar muito lentas. Aqui estão dois truques para acelerá-las um pouco:
- Trabalhe com pacotes/funções adaptados para lidar com grandes conjuntos de dados. Para ler os dados, usamos aqui o fread do pacote data.table, que é muito mais rápido que read.table e se encarrega de descompactar os arquivos automaticamente. Para operações de gerenciamento de dados, o data.table também é muito mais rápido do que o tidyverse, mas eu acho que o código escrito com este último é muito mais fácil de ler. É por isso que uso uma abordagem organizada, a menos que seja complicado e, nessa situação, mudamos para data.table.
- Tente manter apenas os dados necessários para economizar memória. Descarte todos os dados que você não usará, como colunas com atributos sem importância, bem como exclua objetos pesados e desnecessários.
2. Hotspots
Dados
O código abaixo tem como objetivo ler os dados da cadeia sobre os hotspots e realizar algum gerenciamento de dados. Usamos o pacote H3 para converter o índice H3 da Uber em latitude/longitude. H3 é um sistema de indexação geoespacial que utiliza uma grade hexagonal hierárquica. O H3 suporta dezesseis resoluções, e cada resolução mais alta tem células com um sétimo da área da resolução mais baixa. A Helium utiliza a resolução 8. Para se ter uma ideia, com esta resolução, a Terra é coberta por 691.776.122 hexágonos (veja aqui).
# Carregue alguns pacotes úteis
library(knitr)
library(tidyverse)
library(data.table)
library(ggplot2)
library(gganimate)
library(hexbin)
library(h3)
library(lubridate)
library(sp)
library(rworldmap)
# Execute essas duas linhas antes de carregar a biblioteca (rayshader)
# para enviar a saída para o RStudio Viewer em vez da janela X11 externa
options(rgl.useNULL = TRUE,
rgl.printRglwidget = TRUE)
library(rgl)
library(rayshader)
### Recuperar informações sobre os hotspots
dataHotspots <- fread(file = "data/gateway_inventory_01266692.csv.gz", select = c("address", "owner", "first_timestamp", "location_hex")) %>%
rename(hotspot = address,
firstDate = first_timestamp) %>%
filter(location_hex != "", # remova hotspots sem localização
firstDate != as.POSIXct("1970-01-01 00:00:00", tz = "UTC")) %>% # alguns hotspots parecem ter sido instalados em 1970,e isso é obviamente um erro no banco de dados
mutate(data.frame(h3_to_geo(location_hex)),
hotspot = factor(hotspot),
firstDate = round_date(firstDate, "day"), # resolução até o dia é suficiente
owner = factor(owner)) %>% # obtenha os centros dos índices H3 fornecidos
select(-location_hex)
saveRDS(dataHotspots, "data/dataHotspots.rds")
dataHotspots <- readRDS("data/dataHotspots.rds")
É assim que o conjunto de dados do hotspot se parece. Temos o endereço do hotspot, o endereço do proprietário (um proprietário é uma carteira da Helium à qual podem ser vinculados vários hotspots), a data em que o hotspot foi visto pela primeira vez na rede e sua localização no globo.
glimpse(dataHotspots)
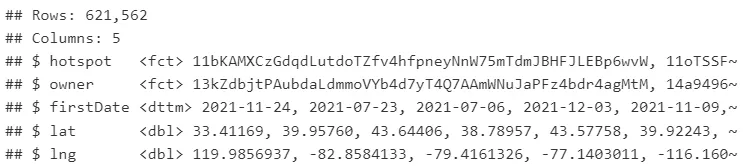
A Tabela 1 mostra algumas estatísticas descritivas sobre o conjunto de dados do hotspot.
dataHotspots %>%
summarise( `Date range` = paste(min(firstDate), max(firstDate), sep = " - "),
`Duration` = round(max(firstDate) - min(firstDate)),
`Total number of hotspots` = length(levels(hotspot)),
`Total number of owners` = length(levels(owner))) %>%
t() %>%
kable(caption = "Estatísticas descritivas sobre o conteúdo do conjunto de dados do hotspot.")

Estatísticas e visualização
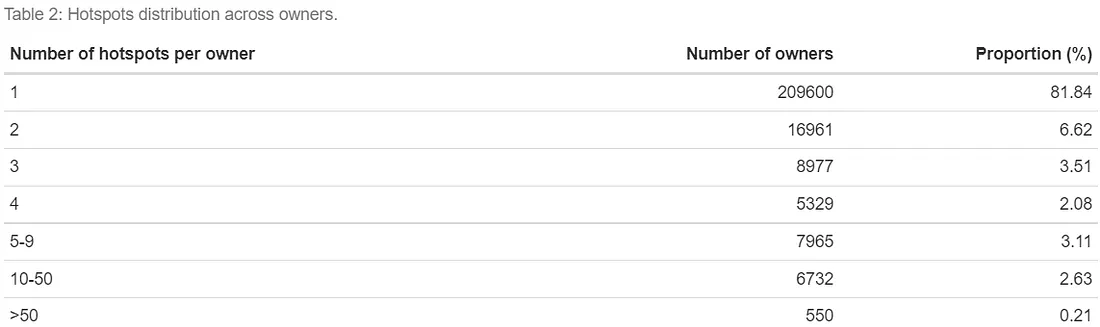
A primeira estatística que calculamos tem como objetivo caracterizar quantos hotspots as pessoas podem ter. Como existem muitos proprietários, não é possível mostrar todas as combinações. Traçar um histograma da distribuição também não é uma opção, pois ele é extremamente distorcido (há um proprietário com cerca de 2000 hotspots!). Portanto, optamos aqui por agrupar o número de hotspots em categorias (Tabela 2). Vemos que a maioria dos proprietários (cerca de 80%) possui apenas um único hotspot, mas alguns possuem centenas de hotspots.
dataHotspots %>%
group_by(owner) %>%
summarise(n = n()) %>%
mutate(`Number of hotspots per owner` = cut(n,
breaks = c(1, 2, 3, 4, 5, 9, 50, Inf),
labels = c("1", "2", "3", "4", "5-9", "10-50", ">50"),
include.lowest = TRUE)) %>%
group_by(`Number of hotspots per owner`) %>%
summarise(`Number of owners` = n()) %>%
mutate(`Proportion (%)` = round(`Number of owners`/sum(`Number of owners`)*100,2)) %>%
kable(caption = "Distribuição de hotspots entre os proprietários.")
Existem mais de 500 mil hotspots no mundo, o que é considerável. Esses hotspots não apareceram em um dia. Na Figura 1, visualizamos o crescimento da rede em termos de quantos hotspots foram adicionados à rede ao longo do tempo, usando um gráfico cumulativo. Vemos três fases: (1) um aumento linear lento, (2) um aumento exponencial em meados de 2021 seguido por (3) um aumento linear rápido. Na minha opinião, a fase exponencial poderia ter continuado mais, mas ficou saturada devido ao suprimento limitado de hotspots que aconteceu devido à escassez mundial de chips após a pandemia do Covid. Para você ter uma ideia, houve um atraso de 6 meses entre o pedido do meu hotspot e a entrega.
nHotspotsPerDate <- dataHotspots %>%
group_by(firstDate) %>%
summarise(count = n())
ggplot(nHotspotsPerDate, aes(x = firstDate, y = cumsum(count))) +
geom_line() +
labs(title = "Crescimento da infraestrutura de rede",
y = "Número total de pontos de acesso (cumulativo)",
x = "Data") +
scale_y_continuous(labels = function(x) format(x, scientific = FALSE),
breaks = seq(0, 5*10^5, length = 6))
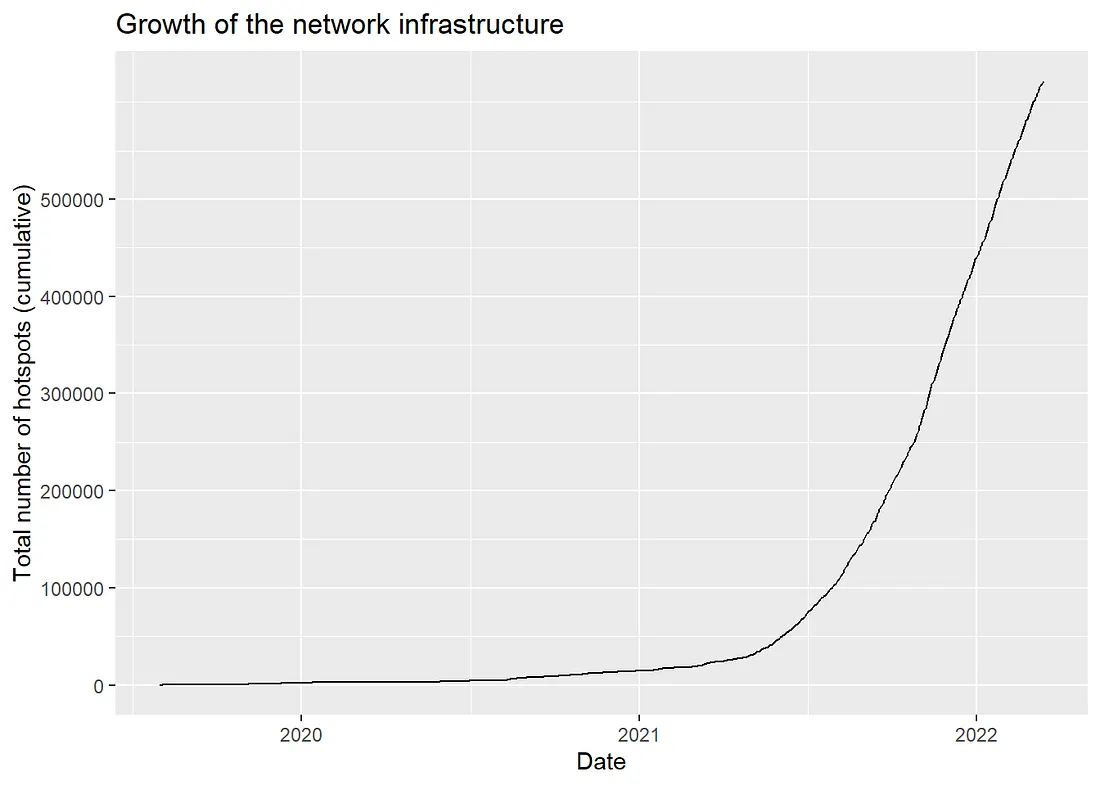
Figura 1: Gráfico cumulativo do crescimento da infraestrutura de rede em termos de número de hotspots adicionados à rede.
Como temos as informações geográficas dos hotspots da Helium, podemos visualizar onde eles estão localizados. Começamos criando um mapa-múndi vazio no qual sobrepomos os dados dos hotspots. Plotar todos os hotspots individuais em um mapa seria demais (existem mais de 500 mil hotspots) - os dados seriam mais fáceis de interpretar quando resumidos. Aqui, escolhemos agrupar os hotspots em hexágonos usando uma função encontrada na web (veja a função aqui), para em seguida plotá-los usando a função geom_hex do ggplot2 (Figura 2).
Podemos ver que a maioria dos hotspots está localizada na América do Norte, Europa e Ásia, principalmente em grandes cidades. Praticamente não há hotspots na África, na Rússia e existem bem poucos na América do Sul. Surpreendentemente, vemos alguns hotspots no meio do oceano. Pode ser um problema de dados ou simplesmente fraude: as pessoas encontraram maneiras de aumentar suas recompensas falsificando a localização de seus hotspots, infelizmente.
# crie um mapa-múndi vazio
world <- map_data("world")
map <- ggplot() +
geom_map(
data = world, map = world,
aes(long, lat, map_id = region)
) +
scale_y_continuous(breaks=NULL) +
scale_x_continuous(breaks=NULL) +
theme(panel.background = element_rect(fill='white', colour='white'))
# agrupe os hotspots em hexágonos
makeHexData <- function(df, nbins, xbnds, ybnds) {
h <- hexbin(df$lng, df$lat, nbins, xbnds = xbnds, ybnds = ybnds, IDs = TRUE)
data.frame(hcell2xy(h),
count = tapply(df$hotspot, h@cID, FUN = function(z) length(z)), # calcule o número de linhas como o número de transações
cid = h@cell)
}
# encontre os limites para os dados completos
xbndsHotspot <- range(dataHotspots$lng)
ybndsHotspot <- range(dataHotspots$lat)
nHotspotsHexbin <- dataHotspots %>%
group_modify(~ makeHexData(.x, nbins = 500,
xbnds = xbndsHotspot,
ybnds = ybndsHotspot))
map +
geom_hex(aes(x = x, y = y, fill = count),
stat = "identity",
data = nHotspotsHexbin) +
scale_fill_distiller(palette = "Spectral", trans = "log10") +
labs(title = "Localização de hotspots no mundo",
fill = "Número de hotspots") +
theme(legend.position = "bottom")
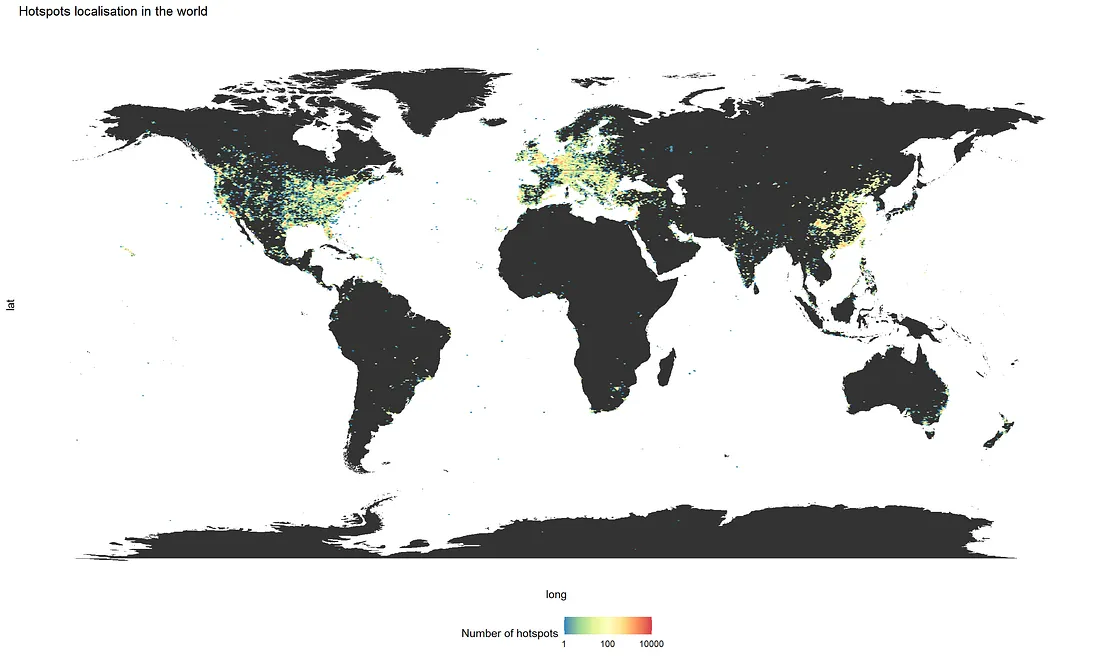
Figura 2: Localização dos hotspots no mundo. Uma figura de alta resolução está disponível aqui.
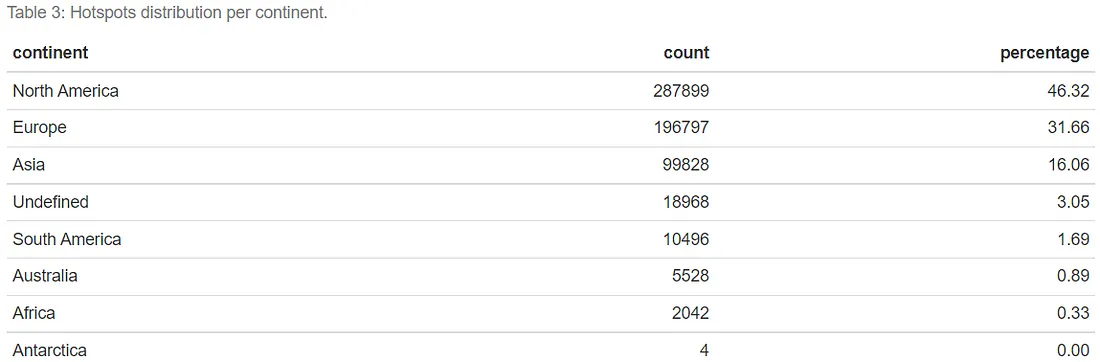
Além da visualização, é sempre útil fornecer alguns números. Abaixo, resumimos a proporção de hotspots por continente. Para isso, usamos o pacote rworldmap com uma função personalizada daqui, que mapeia um par de longitude/latitude no nome do continente/país a que pertence. A Tabela 3 mostra que quase metade dos hotspots está localizada na América do Norte, seguida pela Europa com 30% e depois a Ásia com 16%. Observe o grupo Indefinido (Undefined), que provavelmente se refere a hotspots localizados no meio do oceano ou ao longo da fronteira do continente. Observe também os quatro hotspots na... Antártica.
# O único argumento da função abaixo, - "points", é um data.frame no qual:
# - a coluna 1 contém a longitude de um hotspot em graus
# - a coluna 2 contém a latitude de um hotspot em graus
coords2continent = function(points)
{
countriesSP <- getMap(resolution='low')
# "SpatialPoints" converte pontos em um objeto SpatialPoints
pointsSP = SpatialPoints(points, proj4string=CRS(proj4string(countriesSP)))
# use 'over' para obter índices do objeto Polygons contendo cada ponto
indices = over(pointsSP, countriesSP)
return(data.frame(continent = indices$REGION, country = indices$ADMIN))
}
dataHotspots <- dataHotspots %>%
mutate(coords2continent(data.frame(.$lng, .$lat)),
continent = replace_na(as.character(continent), "Undefined"),
continent = factor(continent))
dataHotspots %>%
group_by(continent) %>%
summarise(count = n()) %>%
mutate(percentage = round(count/sum(count)*100,2)) %>%
arrange(desc(count)) %>%
kable(caption = "Distribuição dos hotspots por continente.")
3. Uso da rede
Dados
Agora que entendemos como os hotspots existentes estão distribuídos no planeta e entre os proprietários, seria interessante saber se eles estão sendo usados ativamente pelos dispositivos conectados e com que frequência. Para responder a esta pergunta, vamos baixar todo o histórico de transferência de dados. Este é um enorme conjunto de dados (3 GB).
Na Helium, você paga apenas pelos dados que usa. Cada pacote enviado ou recebido através de uma conexão com a rede consome 24 bytes, o que equivale a 1 Crédito de Dados (DC) = $0.00001. Para ter uma ideia de quanto a rede é utilizada, podemos avaliá-la a partir de duas perspectivas: (1) verificar o volume de dados trocados e (2) verificar com que frequência os hotspots estão envolvidos em transferência de dados com dispositivos conectados.
### Recupere o conjunto de dados compactados transferidos (transações)
listFilesTransactions <- list.files("data/packets", pattern=".csv.gz", recursive = T)
# especificamos as colunas que queremos manter diretamente na chamada "fread" para economizar memória
dataTransactions <- lapply(1:length(listFilesTransactions),function(i){
data <- fread(file = paste0("data/packets/",listFilesTransactions[i]), select = c("block", "transaction_hash", "time", "gateway", "num_dcs"))
return(data)
})
dataTransactions <- dplyr::bind_rows(dataTransactions) %>%
mutate(bytes = 24 * num_dcs, # Cada pacote enviado ou recebido consome 24 bytes e custa 1 Crédito de Dados (DC) = $0.00001.
date = as.POSIXct(time, origin = "1970-01-01"),
date = round_date(date, "day"), # reduzir a precisão da data para facilitar a plotagem
gateway = factor(gateway)) %>%
select(-time, -num_dcs, -transaction_hash) %>%
rename(hotspot = gateway)
# combine o hotspot ao conjunto de dados da transação para incluir a localização do hotspot
# inner_join mantém todas as linhas disponíveis em X e Y
dataTransactionsWithLocation <- inner_join(dataTransactions, dataHotspots) %>%
mutate(hotspot = factor(hotspot, levels = levels(dataHotspots$hotspot))) %>% # isso é para evitar a queda de níveis para hotspots não envolvidos em nenhuma transação
select(-owner, -firstDate)
# remova esses dois grandes conjuntos de dados para economizar memória
rm("dataHotspots")
rm("dataTransactions")
saveRDS(dataTransactionsWithLocation, "data/dataTransactionsWithLocation.rds")
dataTransactionsWithLocation <- readRDS("data/dataTransactionsWithLocation.rds")
É assim que o conjunto de dados da transação se parece. Para cada transação, temos o número do bloco, o endereço do hotspot, a quantidade de bytes transferidos, a data e a localização do hotspot.
glimpse(dataTransactionsWithLocation)

A Tabela 4 mostra algumas estatísticas descritivas sobre o conjunto de dados de transações, assim como o volume de dados trocados até o momento. Evidentemente, a quantidade de dados trocados entre hotspots e dispositivos conectados é pequena, sendo aproximadamente a mesma quantidade de dados criada pelo meu smartphone nos últimos anos. Essa métrica não parece ser um bom indicador de uso da Helium. De fato, a intenção da rede não é transferir grandes volumes de dados, mas sim transferir dados por longas distâncias e a preços baixos. Abaixo, podemos analisar a segunda métrica, que é mais apropriada para quantificar o uso da Helium.
Outro fato interessante - a primeira transação ocorreu em 15/05/2020, enquanto o primeiro hotspot apareceu na rede em 31/07/2019. Isso significa que houve cerca de 14 meses de atraso entre o aparecimento do primeiro hotspot e a realização da primeira transação. Há dois motivos: (1) meu palpite inicial - isso ocorreu porque um número crítico de hotspots era necessário para convencer os fabricantes de dispositivos conectados a trabalhar com a rede e (2) a transferência de dados era gratuita no início e as transações com DCs só foram ativadas em Abril de 2020 (mais sobre isso aqui).
dataTransactionsWithLocation %>%
summarise( `Date range` = paste(min(date), max(date), sep = " - "),
`Duration` = round(max(date) - min(date)),
`Block range` = paste(min(block), max(block), sep = " - "),
`Number of transactions` = n(),
`Total number of hotspots` = length(levels(hotspot)),
`Number of hotspots involved in at least one transaction` =
length(unique(hotspot)),
`Total data volume exchanged so far` =
paste(round(sum(dataTransactionsWithLocation$bytes) / 1e+12,3), "TB")) %>% # some e converta byte em terabytes
t() %>%
kable(caption = "Estatísticas resumidas sobre o conteúdo do conjunto de dados da transação.")

Estatísticas e visualização
Para determinar com que frequência os hotspots estiveram envolvidos na transferência de dados com dispositivos conectados, também podemos analisar o número total de transações. Esta é uma outra métrica de uso da Helium. Cada transferência de dados entre um hotspot e um dispositivo conectado corresponde a uma transação na blockchain e uma linha em nosso conjunto de dados.
Para resumir a evolução desta métrica, calculamos a soma acumulada do número de transações por data e depois estratificamos por continente. Globalmente, a figura 3 é muito semelhante à figura 1 acima: um aumento linear lento seguido por um aumento exponencial, que é finalmente seguido por um aumento linear rápido. A única diferença é a falha em novembro de 2021, devido a uma grande interrupção da blockchain (aqui). Surpreendentemente, vemos que apesar de ter cerca de 15% dos hotspots, a Ásia não parece ser tão ativa em termos de transferência de dados em comparação com a América do Norte e a Europa.
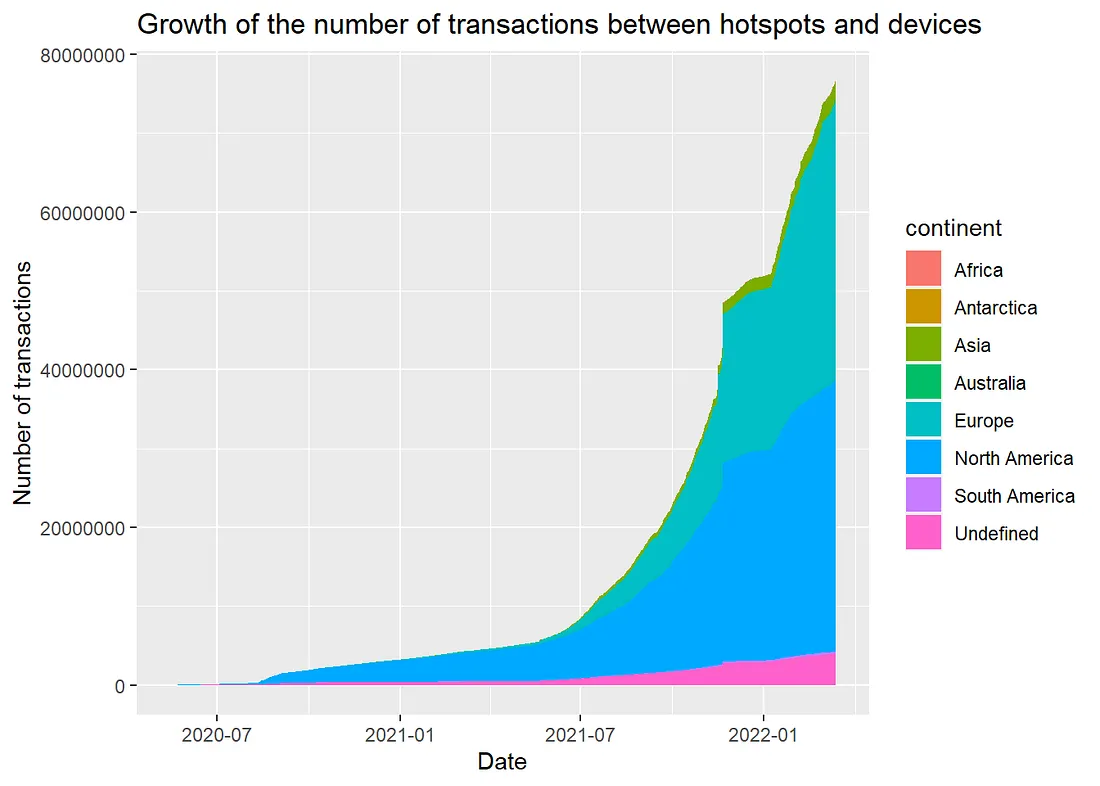
Figura 3: Crescimento do número de transações entre hotspots e dispositivos, estratificado por continente.
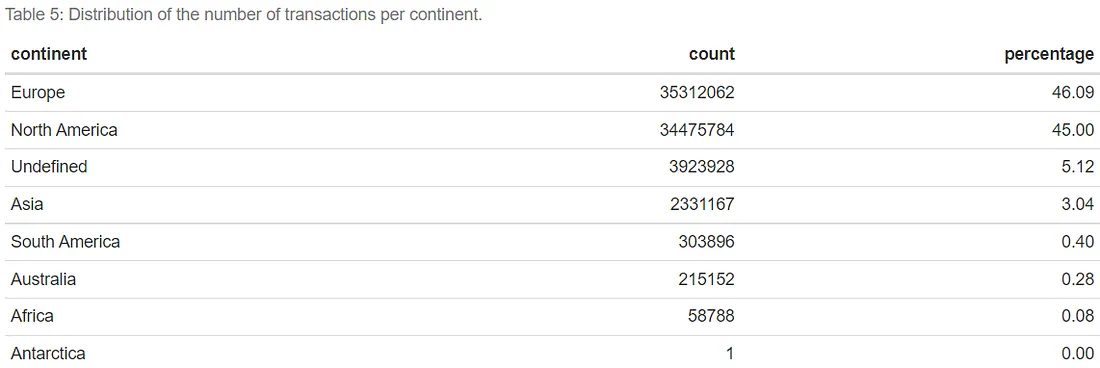
Isso é confirmado pela distribuição do número total de transações por continente. Vemos que a Ásia representa apenas 3% do total.
dataTransactionsWithLocation %>%
group_by(continent) %>%
summarise(count = n()) %>%
mutate(percentage = round(count/sum(count)*100,2)) %>%
arrange(desc(count)) %>%
kable(caption = "Tabela 3: Distribuição do número de transações por continente.")
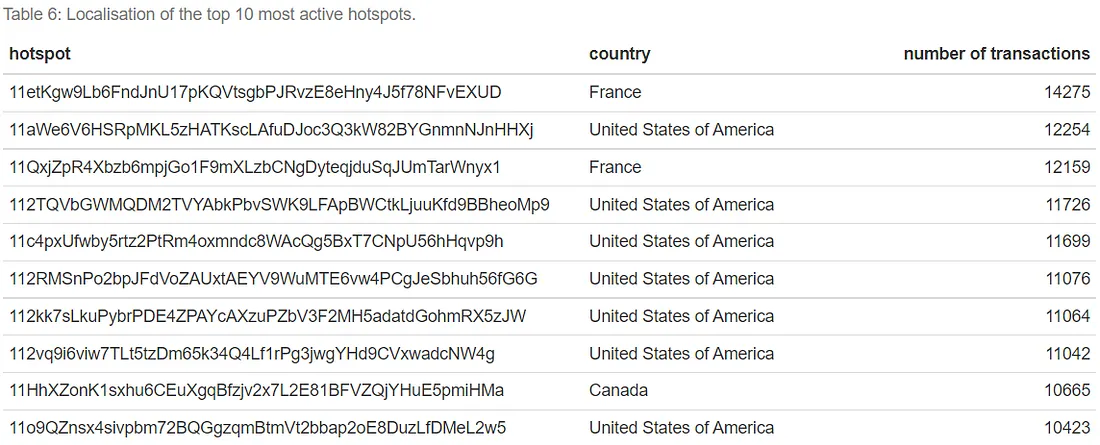
Também podemos ver onde estão localizados os 10 principais hotspots mais ativos. Observe que usaremos a sintaxe data.table em vez de dplyr. Como mencionado acima, a sintaxe dplyr é preferida por sua legibilidade. Neste caso, leva apenas 2 segundos para data.table enquanto que o dplyr é muito mais lento. Vemos que os hotspots mais ativos estão localizados na França, EUA e Canadá.
summaryTransactionPerHotspot <- dataTransactionsWithLocation[, .(`number of transactions` = .N),
by = c("hotspot", "country")] %>%
# sintaxe data.table para acelerar
arrange(desc(`number of transactions`))
summaryTransactionPerHotspot %>%
slice(1:10) %>%
kable(caption = "Localização dos 10 principais hotspots mais ativos.")
Podemos também calcular a proporção de hotspots envolvidos em transações e o número médio de transações por hotspot.
medianNumberOfTransactions <- median(summaryTransactionPerHotspot$`number of transactions`)
propWith0Transactions <- length(which(table(dataTransactionsWithLocation$hotspot) == 0)) /
length(levels(dataTransactionsWithLocation$hotspot)) * 100
A mediana do número de transações por hotspot (excluindo hotspots que não participaram de nenhuma transação) é 42, e 40,48% dos hotspots ainda não participaram de nenhuma transação até o momento. Não podemos realmente dizer que todos os hotspots estão sendo explorados... por enquanto! A rede ainda está começando e tem muita capacidade disponível.
Vamos visualizar novamente o número de transações no mapa-múndi. Nós agrupamos os dados usando a mesma função makeHexData e sobrepomos o mapa com o número de transações de dados. Desta vez, criamos uma animação longitudinal usando o pacote gganimate (Figura 4). Embora seja difícil fazer uma comparação direta com a figura 3, já que temos aqui uma dimensão adicional (a cor se refere ao número de transações), a mensagem é semelhante. Vemos que as transações ocorrem principalmente na América do Norte antes do meio de 2020, seguido por uma forte onda na Europa e Ásia. Quase nenhuma transação ocorreu na América do Sul e na África.
## agrupe os hotspots em hexágonos
# encontre os limites para os dados completos
xbndsPacket <- range(dataTransactionsWithLocation$lng)
ybndsPacket <- range(dataTransactionsWithLocation$lat)
nTransactionsPerDateHexbin <- dataTransactionsWithLocation %>%
mutate(date = as.Date(round_date(date, "week"))) %>% # vamos diminuir a resolução para facilitar a plotagem
group_by(date) %>%
group_modify(~ makeHexData(.x,
nbins = 500,
xbnds = xbndsPacket,
ybnds = ybndsPacket))
pNumberOfTransactionsAnimated <- map +
geom_hex(aes(x = x, y = y, fill = count),
stat = "identity",
data = nTransactionsPerDateHexbin) +
scale_fill_distiller(palette = "Spectral",
trans = "log10") +
labs(title = "Evolução do número de transações",
fill = "Número de transações") +
theme(legend.position = "bottom")
anim <- pNumberOfTransactionsAnimated +
transition_time(date) +
labs(title = "Date: {frame_time}",
subtitle = 'Frame {frame} of {nframes}')
animate(anim, nframes = length(unique(nTransactionsPerDateHexbin$date)))
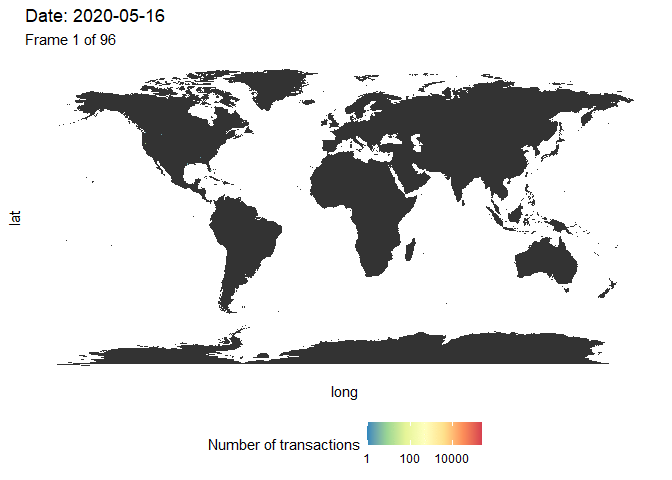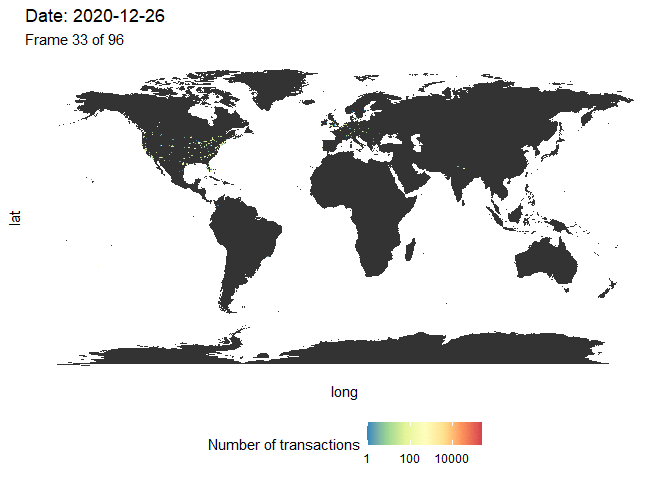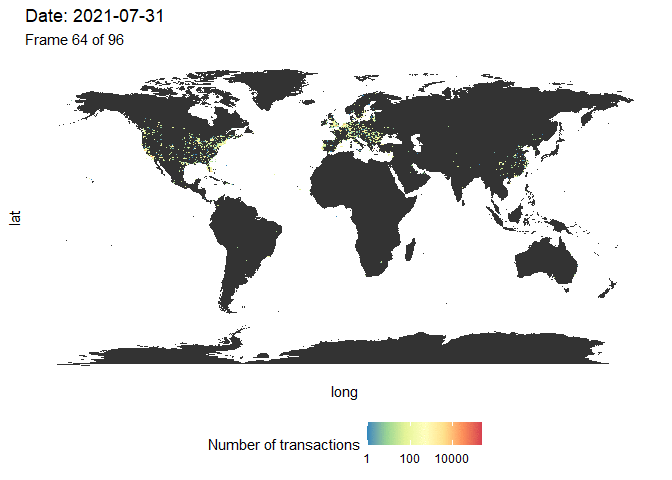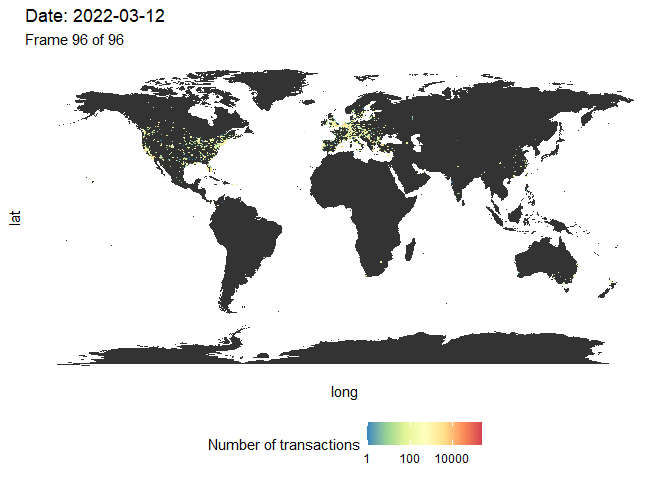
Figura 4: Evolução do número de transações no mundo. Uma figura de alta resolução está disponível aqui.
Para adicionar um pouco de perspectiva visual, também podemos transformar o gráfico em 3D usando o incrível pacote rayshader. Vamos nos concentrar em dois países: (1) os EUA, já que é o país com o maior número de hotspots e transações e (2) a Bélgica, que é o meu país de origem. Como desta vez pretendemos gerar um gráfico estático em vez de uma animação, reagrupamos os dados em hexágonos. Observe que é possível animar esse gráfico 3D, mas leva muito tempo de computação e ajustes finos (veja aqui).
A Figura 5 mostra o mapa dos EUA. Vemos que as transações estão distribuídas de forma homogênea pelo país, embora os picos de atividade (observe que a legenda é logarítmica!) estejam localizados em torno de grandes cidades (Nova York, Los Angeles, São Francisco, Miami).
# obtenha o mapa dos EUA
US <- map_data("usa")
mapUS <- ggplot() +
geom_map(
data = US, map = US,
aes(long, lat, map_id = region)
) +
scale_y_continuous(breaks=NULL) +
scale_x_continuous(breaks=NULL) +
theme(panel.background = element_rect(fill='white', colour='white'))
# filtre para manter apenas as transações dos EUA
dataTransactionsWithLocationUS <- dataTransactionsWithLocation %>%
filter(country == "United States of America") %>%
filter(lng > -140) # existem alguns hotspots longe do continente
# encontre os limites para os dados completos
xbndsPacketUS <- range(dataTransactionsWithLocationUS$lng)
ybndsPacketUS <- range(dataTransactionsWithLocationUS$lat)
# agrupe dentro de hexágonos
nTransactionsUS <- dataTransactionsWithLocationUS %>%
group_modify(~ makeHexData(.x,
nbins = 250,
xbnds = xbndsPacketUS,
ybnds = ybndsPacketUS))
# gere o gráfico
pNumberOfTransactionsUS <- mapUS +
geom_hex(aes(x = x, y = y, fill = count),
stat = "identity",
data = nTransactionsUS) +
scale_fill_distiller(palette = "Spectral", trans = "log10") +
labs(title = "Distribuição das transações nos EUA",
fill = "Número de transações") +
theme(legend.position = "bottom")
# adicione o 3D
plot_gg(pNumberOfTransactionsUS,
multicore = TRUE,
width = 8,
height= 8,
zoom = 0.7,
theta = 0,
phi = 70,
raytrace = TRUE)
rgl::rglwidget(width = 800, # isto é para imprimir o widget no documento html
height = 600)
rgl::rgl.close()
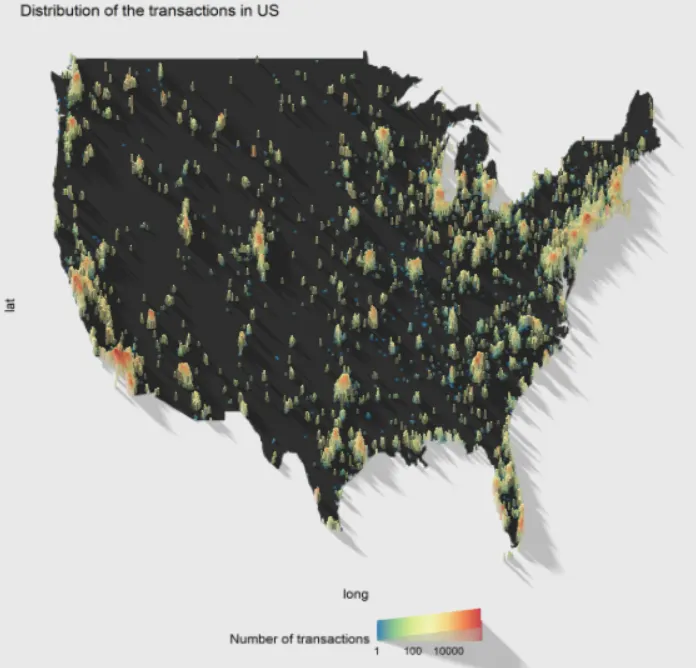
Figura 5: Distribuição das transações nos EUA. A visualização pode ser manipulada com o mouse. A figura interativa em alta resolução está disponível aqui.
A Figura 6 mostra um mapa da Bélgica. Aqui, o padrão é diferente, pois vemos que as transações não estão distribuídas homogeneamente pelo país. A maioria das transações acontece na parte superior do país, o que é consistente com a parte inferior do país sendo escassamente povoada (Região das Ardenas).
# Obtenha o mapa da Bélgica
BE <- world %>%
filter(region == "Belgium")
mapBE <- ggplot() +
geom_map(
data = BE, map = BE,
aes(long, lat, map_id = region)
) +
scale_y_continuous(breaks=NULL) +
scale_x_continuous(breaks=NULL) +
theme(panel.background = element_rect(fill='white', colour='white'))
# filtre para manter apenas as transações da Bélgica
dataTransactionsWithLocationBE <- dataTransactionsWithLocation %>%
filter(country == "Belgium")
# encontre os limites para os dados completos
xbndsPacketBE <- range(dataTransactionsWithLocationBE$lng)
ybndsPacketBE <- range(dataTransactionsWithLocationBE$lat)
# agrupe dentro de hexágonos
nTransactionsBE <- dataTransactionsWithLocationBE %>%
group_modify(~ makeHexData(.x,
nbins = 250,
xbnds = xbndsPacketBE,
ybnds = ybndsPacketBE))
# gere o gráfico
pNumberOfTransactionsBE <- mapBE +
geom_hex(aes(x = x, y = y, fill = count),
stat = "identity",
data = nTransactionsBE) +
scale_fill_distiller(palette = "Spectral", trans = "log10") +
labs(title = "Distribuição das transações na Bélgica",
fill = "Número de transações") +
theme(legend.position = "bottom")
# adicione o 3D
plot_gg(pNumberOfTransactionsBE,
multicore = TRUE,
width = 8,
height= 8,
zoom = 0.7,
theta = 0,
phi = 80,
raytrace = TRUE)
rgl::rglwidget(width = 1024, # isto é para imprimir o widget no documento html
height = 768)
rgl::rgl.close()
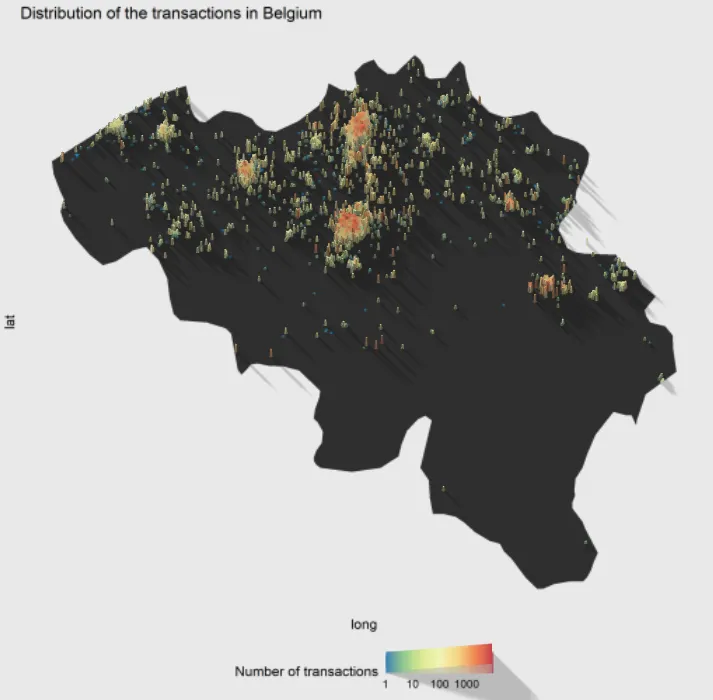
Figura 6: Distribuição das transações na Bélgica. A visualização pode ser manipulada com o mouse. A figura interativa em alta resolução está disponível aqui.
4. Conclusão
Espero que tenha gostado de ler este artigo e agora tenha uma melhor compreensão do que é a rede Helium e sua evolução ao longo dos últimos anos. Aqui, mostramos algumas técnicas de como resumir e visualizar o crescimento da rede em termos de infraestrutura (hotspots) e uso de dados (transações). Analisamos dados espaço-temporais e os plotamos usando pacotes dedicados da linguagem R.
Estamos ansiosos para receber seus comentários e ideias sobre tópicos de blockchain que merecem ser abordados em nosso próximo post. Se você deseja continuar aprendendo sobre análise de dados em cadeia usando a linguagem R, siga-me no Medium, Linkedin e/ou Twitter para ser alertado sobre o lançamento de novos artigos. Obrigado por ler e sinta-se à vontade para entrar em contato conosco se tiver perguntas ou comentários.
Uma versão HTML deste artigo com figuras e tabelas de alta resolução está disponível aqui. O código usado para gerá-lo está disponível no meu Github.
Gostaria de agradecer à equipe da Dewi e à comunidade da Helium do Discord (@ediewald, @bigdavekers, @jamiedubs, #data-analysis) por seu apoio e por fornecer os dados.
Fique atento para mais novidades!
Referências
https://datavizpyr.com/how-to-make-world-map-with-ggplot2-in-r/
Todas as figuras são dos autores, a menos que indicado de outra forma.
Artigo original publicado por Thomas de Marchin e Milana Filatenkova. Traduzido por Paulinho Giovannini.