
No mundo das finanças, prever os preços das ações sempre foi um desafio que cativa a imaginação de investidores, pesquisadores e cientistas de dados. A capacidade de antecipar movimentos futuros de preços poderia potencialmente levar a ganhos significativos, mas não é segredo que o mercado de ações é notoriamente imprevisível. Neste post, mergulhamos em um projeto de aprendizado de máquina voltado para a previsão de preços de ações usando dados históricos e os insights obtidos a partir do processo.
Objetivo do Projeto
O principal objetivo deste projeto era desenvolver um modelo preditivo que pudesse prever os preços das ações para uma data futura específica. Para isso, recorremos aos dados históricos de ações disponíveis no Yahoo Finance. Com esses dados, embarcamos em uma jornada de análise de dados, pré-processamento, seleção de modelo e avaliação.
Estratégia para Resolver o Problema
Nossa abordagem envolveu várias etapas-chave: obter dados de uma fonte confiável, identificar características pertinentes para treinamento, selecionar o modelo ótimo e ajustar seus parâmetros para alcançar a pontuação de acurácia mais alta. Essa estratégia foi elaborada para enfrentar efetivamente a intrincada tarefa de prever preços de ações.
Descrição dos Dados de Entrada
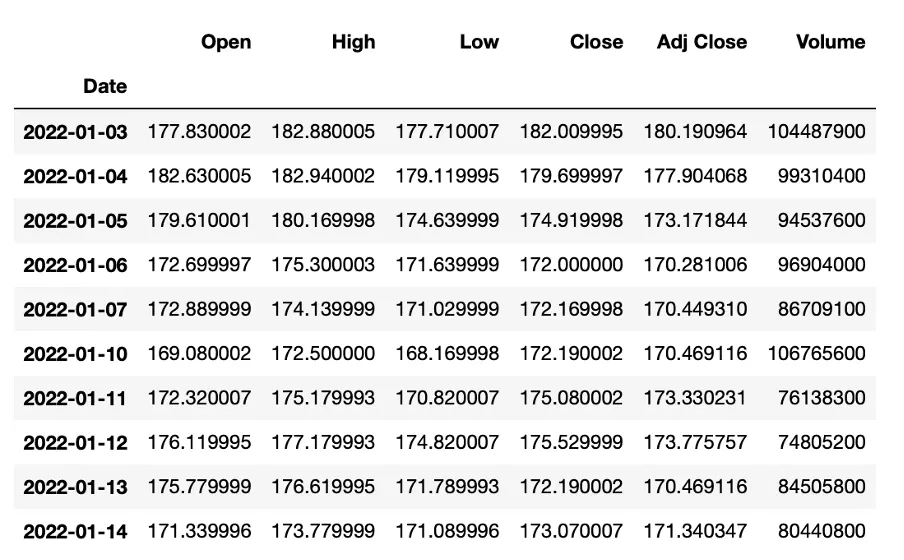
Como mencionado anteriormente, recorremos ao Yahoo Finance para obter dados históricos de ações, usando a API yfinance para baixar as informações relacionadas às ações. A definição de cada dado de entrada é apresentada na tabela abaixo.
https://miro.medium.com/v2/resize:fit:1100/format:webp/1*SMcquPM90L6X3oIuLIQFCw.png
{kind=link}
Pré-processamento de Dados
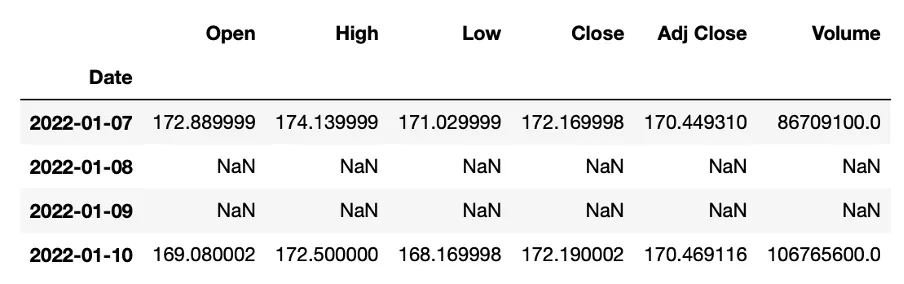
Os dados obtidos do Yahoo Finance já possuem um formato de série temporal, com datas atuando como índice. No entanto, o desafio surge da operação do mercado de ações apenas em dias úteis, levando a lacunas no conjunto de dados devido a fins de semana e feriados. Na tabela abaixo, podemos ver que a série temporal salta de 2022-01-07 para 2022-01-10, pulando o fim de semana.
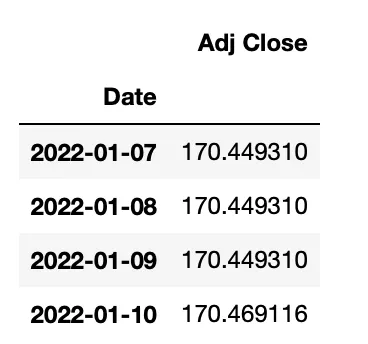
Para resolver isso, foi aplicado o método .asfreq(), convertendo os dados em uma frequência regular.
Adicionalmente, os pontos de dados ausentes foram tratados através do preenchimento progressivo.

Além disso, como parte do processo de preparação dos dados para garantir compatibilidade com a arquitetura do modelo, empreendemos a tarefa de remodelar os dados de entrada. Para isso, escalamos os dados pré-processados. Essa operação de escala é essencial para trazer as características de entrada dentro de uma faixa consistente e gerenciável, facilitando o treinamento efetivo do modelo preditivo.
Trecho de código para escala de dados
Utilizamos o MinMaxScaler para realizar a operação de escala. Para escalar os dados de treinamento, usamos o método fit_transform. Quanto aos dados de teste, aplicamos exclusivamente a transformação, evitando o processo de ajuste para prevenir qualquer vazamento de dados.

Seleção de Características e reconfiguração adicional de dados
Uma decisão crucial neste projeto foi selecionar as características mais relevantes para a modelagem. Através de experimentações, descobriu-se que usar apenas o preço de fechamento ajustado como característica produzia os melhores resultados de previsão. Essa escolha foi motivada pelo fato de que outras características estão relacionadas ao preço e permanecem desconhecidas antes da data futura em questão.
Observe que no gráfico abaixo, a variável 'Volume' foi excluída devido à sua magnitude, que poderia distorcer a visualização dos valores das outras variáveis.
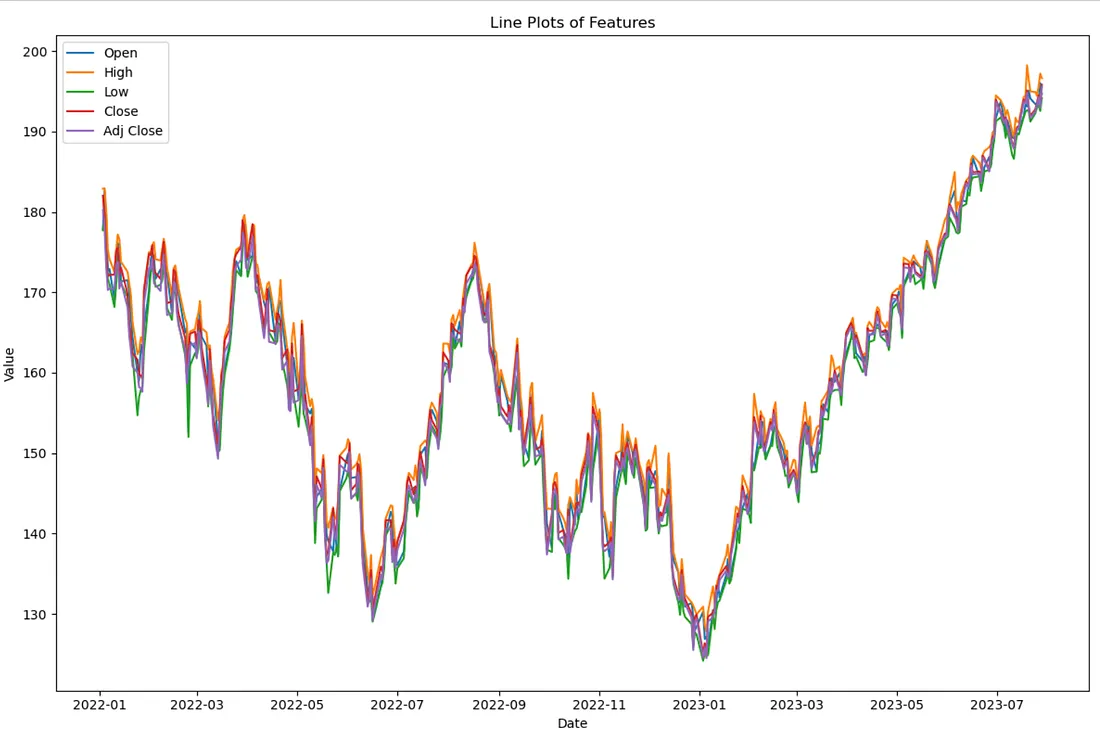
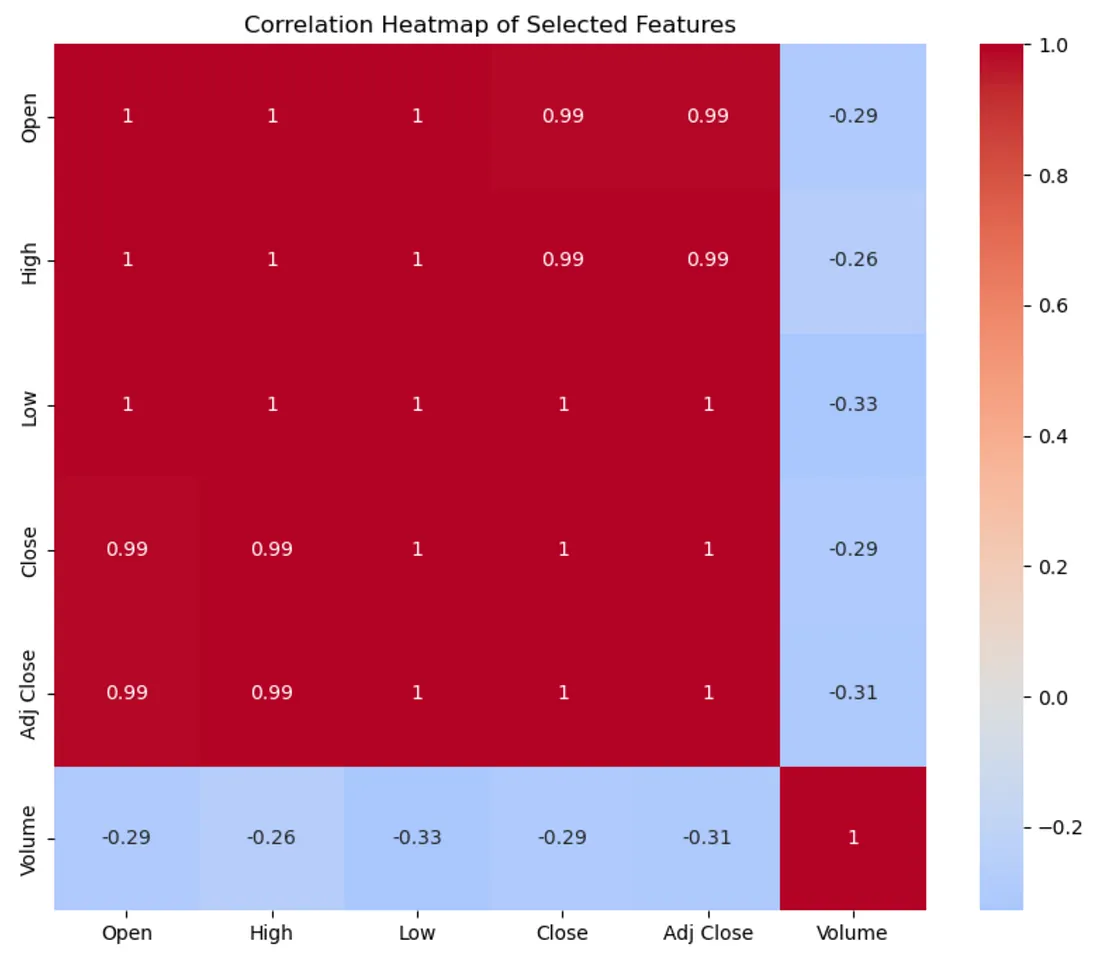
Uma visualização adicional confirmou que as outras características estão altamente correlacionadas com a variável alvo 'Adj Close'. Em relação à característica 'Volume', decidimos excluí-la do nosso modelo de aprendizado de máquina devido à sua fraca correlação de -0,3 com outras variáveis. Além disso, essas características estão sendo excluídas porque um grande número delas só se torna conhecido uma vez que a variável alvo é determinada. Essa indisponibilidade inerente as torna ineficazes para fazer inferências preditivas.
Criando Sequências de Treinamento
Para aprimorar a capacidade do nosso modelo de aprender padrões a partir dos dados de série temporal, utilizamos uma técnica conhecida como criação de sequências. Essa abordagem envolveu a organização dos dados em sequências de um comprimento especificado, com cada sequência representando um conjunto de etapas de tempo passadas. Ao fazer isso, buscamos fornecer ao modelo contexto e história, permitindo-lhe capturar dependências temporais e fazer previsões informadas.
O trecho de código abaixo demonstra como implementamos esse processo de criação de sequência e, em seguida, transformamos os dados em arrays numpy, preparando-os para treinamento:

Seleção e Avaliação do Modelo
Nossa jornada nos levou a explorar dois poderosos tipos de redes neurais recorrentes (Recurrent Neural Networks, ou RNNs): Long Short Term Memory (LSTM, ou Memória Longa de Curto Prazo) e Gated Recurrent Unit (GRU, ou Unidade Recorrente Fechada). Essas RNNs são adequadas para dados sequenciais, como séries temporais.
Usamos uma busca em grade para encontrar os melhores hiperparâmetros para os modelos LSTM e GRU. O modelo LSTM emergiu como o vencedor claro, oferecendo acurácia de previsão superior. Para quantificar o desempenho do nosso modelo, utilizamos o Erro Percentual Absoluto Médio (MAPE, ou Mean Absolute Percentage Error), uma métrica que calcula a diferença percentual entre os valores previstos e reais.
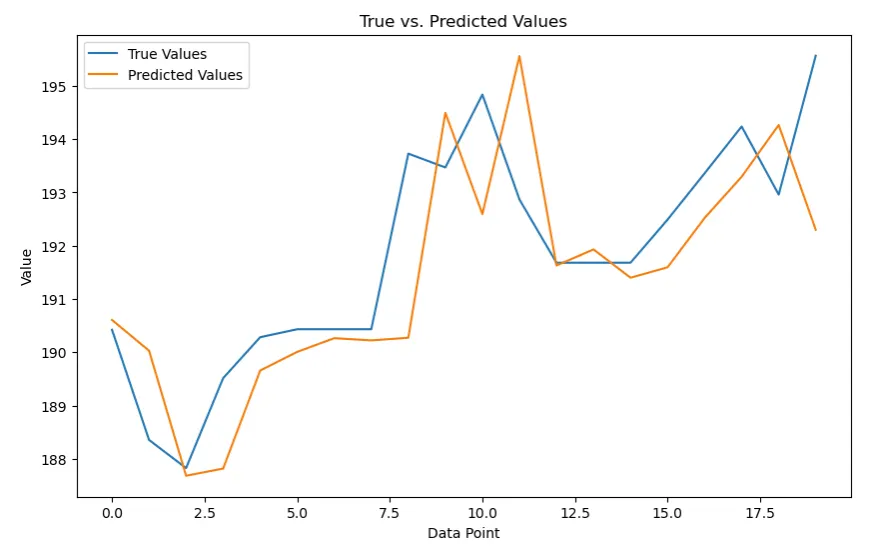
Visualizando o Desempenho do Modelo: Comparando Valores Previstos e Verdadeiros
Para avaliar a acurácia e eficácia do nosso modelo LSTM, usamos visualizações para justapor os valores previstos gerados pelo modelo com os verdadeiros valores de teste. Essa representação gráfica ofereceu um meio claro e intuitivo de entender quão bem as previsões do nosso modelo se alinhavam com os dados verdadeiros.
Arquitetura do Modelo — LSTM
O modelo LSTM escolhido para este projeto é adequado para dados sequenciais, como séries temporais. Redes LSTM contêm células de memória que podem reter informações ao longo de longas sequências, tornando-as aptas para capturar padrões nos movimentos de preços das ações.
Queríamos que nosso modelo LSTM funcionasse com a máxima acurácia possível. Assim, o testamos com diferentes configurações usando o GridSearch. Isso nos ajudou a encontrar a melhor maneira de configurar o modelo para prever preços de ações. Após encontrar essas melhores configurações, ajustamos o modelo de acordo. Em seguida, usamos esse modelo bem ajustado para ver o quão bem ele prevê os preços das ações usando as configurações escolhidas. Dessa forma, garantimos que nosso modelo tenha o melhor desempenho.
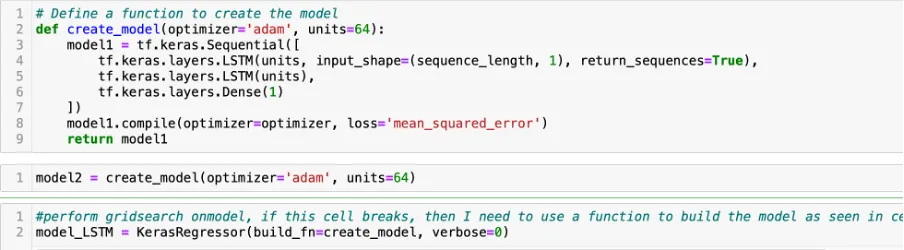
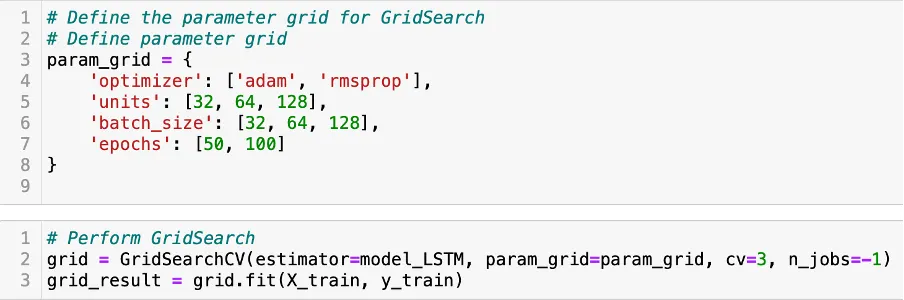

Implementamos então os parâmetros ótimos obtidos através da busca em grade no modelo LSTM final mostrado abaixo:
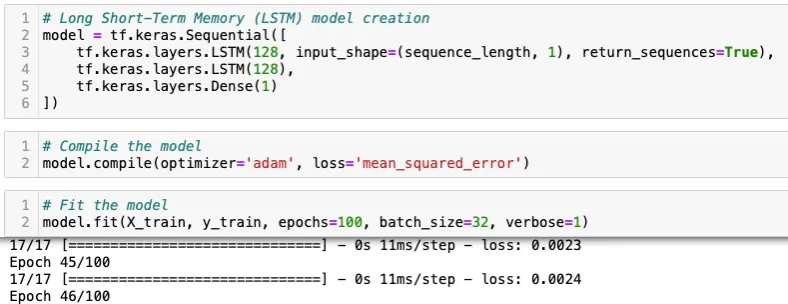
De forma semelhante, aplicamos o mesmo processo ao modelo GRU; no entanto, o modelo LSTM teve um desempenho ligeiramente melhor, resultando em uma pontuação MAPE mais baixa. Essa pequena vantagem de desempenho nos levou a selecionar o modelo LSTM como a escolha final para nosso projeto de previsão de preços de ações.
Métricas e Justificação
O sucesso do projeto depende da escolha das métricas de avaliação. O Erro Percentual Absoluto Médio foi selecionado como a métrica primária. O MAPE calcula a diferença percentual entre valores previstos e reais, fornecendo uma medida intuitiva da acurácia da previsão.
O MAPE é uma métrica de avaliação apropriada para um modelo de previsão de ações devido à sua adequação para modelos de regressão que lidam com valores de resultados contínuos, como preços de ações. O MAPE oferece várias vantagens que o tornam particularmente relevante neste contexto. A escolha desta métrica é justificada pela sua capacidade de fornecer uma medida clara, interpretável e invariante de escala da acurácia da previsão.
Segue o trecho de código para calcular o MAPE do Modelo LSTM. É importante mencionar que, antes de calcular o MAPE, uma etapa crucial envolveu reverter a transformação aplicada ao output previsto para restaurá-lo à sua magnitude de preço original. Como anteriormente padronizamos os dados de entrada para garantir compatibilidade com o modelo, é essencial lembrar da necessidade de reverter o processo de escala agora.
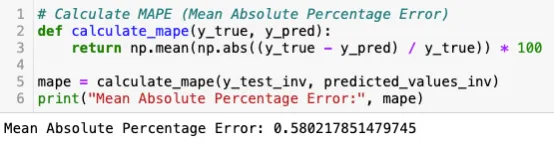
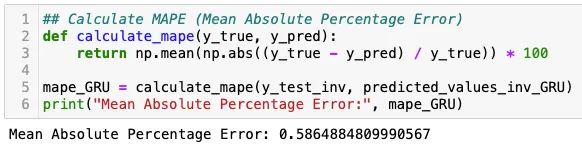
Da mesma forma, seguimos o mesmo procedimento para o modelo GRU. No entanto, os resultados não foram tão promissores quanto os alcançados com o modelo LSTM. O modelo LSTM obteve uma pontuação de 0,5800, enquanto o modelo GRU alcançou uma pontuação de 0,58648. Ambos os modelos tiveram desempenhos bastante semelhantes, com o modelo LSTM ligeiramente à frente por uma pequena margem.
Resultados e Principais Insights
A culminação do projeto reside na avaliação do desempenho do modelo. Através de rigorosos testes e avaliações, o modelo LSTM alcançou um MAPE de 0,58 — uma indicação promissora de suas capacidades preditivas.
Descobri um aspecto particularmente intrigante durante o projeto: o modelo preditivo demonstrou um desempenho melhorado quando considerava apenas a variável alvo, o preço de fechamento ajustado, ao invés de incorporar características adicionais como preços de abertura, máximos e mínimos. Essa observação me levou a considerar se o alto nível de correlação entre essas características e a variável alvo poderia estar contribuindo para esse fenômeno. É possível que a inclusão de características estreitamente relacionadas possa introduzir multicolinearidade ou ruído, impactando potencialmente a acurácia preditiva do modelo.
Conclusão
No mundo da previsão do mercado de ações, o sucesso é medido pela capacidade de aproveitar insights orientados por dados para tomar decisões informadas. Embora o modelo LSTM tenha demonstrado um desempenho notável, é crucial reconhecer as complexidades do mercado de ações. Fatores como indicadores econômicos, eventos geopolíticos e sentimentos do mercado são apenas algumas das variáveis que influenciam os preços das ações, contribuindo para sua imprevisibilidade inerente.
Melhorias Futuras
Ao concluir o projeto, o caminho a seguir torna-se claro. Melhorias poderiam envolver a integração de uma gama mais ampla de indicadores financeiros e econômicos no modelo. Esta abordagem holística poderia resultar em previsões mais robustas e precisas, fornecendo aos investidores maior confiança em suas tomadas de decisão.
Agradecimento
Agradecemos ao Yahoo Finance por fornecer acesso a dados históricos valiosos. Sua contribuição desempenhou um papel fundamental no sucesso do projeto.
Artigo original publicado por Miryam Chen. Traduzido por Paulinho Giovannini.