
O futuro da interoperabilidade entre blockchains será construído em torno de relacionamentos dinâmicos e ricos em dados entre aplicativos multi-chain. A Lagrange Labs está desenvolvendo a cola para ajudar a escalar de forma segura a interoperabilidade baseada em provas de conhecimento zero.

A Pilha de Big Data ZK:
A pilha de Big Data ZK da Lagrange Labs é uma construção de prova proprietária otimizada para gerar provas de armazenamento em lote em grande escala simultaneamente com computação distribuída dinâmica arbitrária. A pilha de Big Data ZK é extensível a qualquer estrutura de computação distribuída, desde o MapReduce até RDD até SQL distribuído.
Com a pilha de Big Data ZK da Lagrange Labs, uma prova pode ser gerada a partir de um único cabeçalho de bloco, provando tanto uma matriz de estados de slot de armazenamento histórico em profundidades arbitrárias quanto os resultados de uma computação distribuída executada nesses estados. Em resumo, cada prova combina tanto a verificação de provas de armazenamento quanto a computação distribuída verificável em uma única etapa.
Neste artigo, discutiremos o MapReduce ZK (ZKMR), o primeiro produto na pilha de Big Data ZK da Lagrange.
Compreendendo o MapReduce:
Em uma computação sequencial tradicional, um único processador executa um programa inteiro seguindo um caminho linear, em que cada instrução é executada na ordem em que aparece no código. Com o MapReduce e paradigmas de computação distribuída semelhantes, como RDD, a computação é dividida em várias tarefas pequenas que podem ser executadas em vários processadores em paralelo.
O MapReduce funciona dividindo um grande conjunto de dados em pedaços menores e distribuindo-os em um cluster de máquinas. Em termos gerais, essa computação segue três etapas distintas:
1.Mapear: Cada máquina realiza uma operação de mapeamento em seu pedaço de dados, transformando-o em um conjunto de pares chave-valor.
2.Embaralhar: Os pares chave-valor gerados pela operação de mapeamento são então embaralhados e classificados por chave.
3.Reduzir: Os resultados do embaralhamento são passados para uma operação de redução, que agrega os dados e produz a saída final.
A principal vantagem do MapReduce é sua escalabilidade. Como a computação é distribuída entre várias máquinas, ela pode lidar com conjuntos de dados em grande escala que seriam inviáveis de processar sequencialmente. Além disso, a natureza distribuída do MapReduce permite que a computação seja escalada horizontalmente em mais máquinas, em vez de verticalmente em termos de tempo de computação.
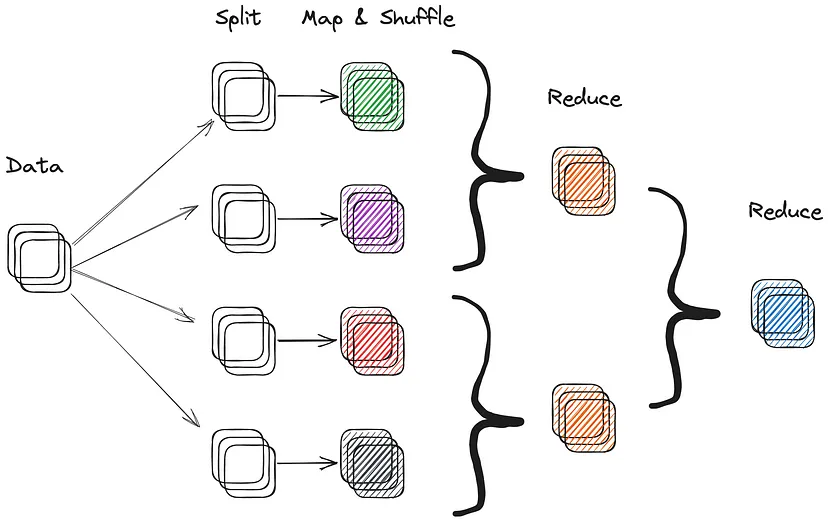 Uma execução tradicional do programa MapReduce
Uma execução tradicional do programa MapReduce
Paradigmas de computação distribuída como MapReduce ou RDD são comumente usados em arquiteturas da Web 2.0 para processamento e análise de conjuntos de dados grandes. A maioria das grandes empresas da Web 2.0, como Google, Amazon e Facebook, faz amplo uso da computação distribuída para processar dados de pesquisa em escala de petabytes e conjuntos de dados de usuários. Estruturas modernas para computação distribuída incluem Hive, Presto e Spark.
Uma Introdução ao ZK MapReduce:
O ZK MapReduce (ZKMR) da Lagrange é uma extensão do MapReduce que utiliza provas recursivas para comprovar a correção da computação distribuída em grandes quantidades de dados de estado em cadeia. Isso é alcançado gerando provas de correção computacional para cada trabalhador dado durante as etapas de mapeamento (map) ou redução (reduce) de um trabalho de computação distribuída. Essas provas podem ser compostas recursivamente para construir uma única prova para a validade de todo o fluxo de trabalho computacional distribuído. Em outras palavras, as provas das computações menores podem ser combinadas para criar uma prova da computação inteira.
A capacidade de compor várias subprovas de computação de trabalhadores em uma única prova ZKMR permite que ela se dimensione de maneira mais eficiente para computações complexas em grandes conjuntos de dados.
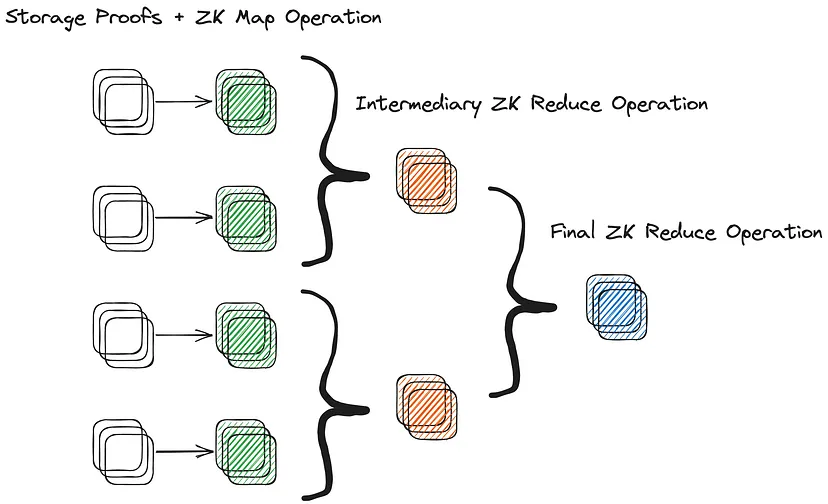 A verificação de um procedimento MapReduce arbitrário em Zero-Knowledge
A verificação de um procedimento MapReduce arbitrário em Zero-Knowledge
Uma das principais vantagens do ZKMR, em comparação com as máquinas virtuais à prova de conhecimento zero (ZKVMs), é a capacidade de executar computações dinâmicas sobre o estado de armazenamento de contratos presentes e históricos. Em vez de ter que provar a inclusão de armazenamento em uma série de blocos separadamente e depois provar uma série de computações sobre o conjunto de dados agregados, o ZKMR (e outros produtos Lagrange ZK Big Data) suportam a composição de ambos em uma única prova. Isso reduz significativamente o tempo de prova para gerar provas ZKMR, em comparação com designs alternativos.
##ZK MapReduce em Ação:
Para entender como provas recursivas podem ser compostas, vamos considerar um exemplo simples. Imagine que queremos calcular a média de liquidez de um par de ativos em uma DEX ao longo de um determinado período. Para cada bloco, devemos mostrar a correção de uma prova de inclusão na raiz do estado, provando quanto de liquidez está naquela DEX. Em seguida, devemos somar toda a liquidez em cada bloco na média e dividir pelo número de blocos.
Sequencialmente, essa computação ficaria assim:
# Execução Sequencial
func calculate_avg_eth_price_per_block(var mpt_paths, var liquidity_per_block){
var sum = 0;
for(int i=0; i<len(liquidity_per_block); i++){
verify_inclusion(liquidity_per_block[i], mpt_path[i])
sum += liquidity_per_block[i]
}
var avg_liquidity = sum / num_blocks
// retornar a liquidez média
return avg_liquidity
}
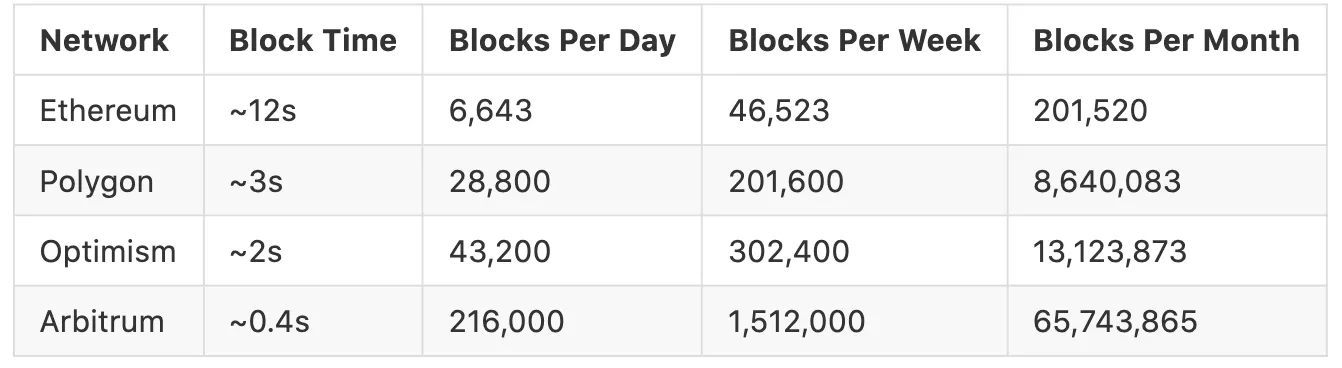
Embora essa computação possa intuitivamente parecer direta, o desempenho degrada rapidamente à medida que a quantidade de estado que precisa ser incluída aumenta. Considere a tabela abaixo, mostrando o número de blocos por cadeia em intervalos de tempo específicos. No limite, calcular a média de liquidez em uma única DEX na Arbitrum ao longo de 1 mês exigiria dados de mais de 65 milhões de blocos rollup.
Em contraste com o ZKMR, podemos dividir o conjunto de dados em pedaços menores e distribuí-los entre vários processadores. Cada máquina executará uma operação de mapeamento que calcula a prova Merkle-Patricia Trie (MPT) e soma a liquidez para o seu conjunto de dados. A operação de mapeamento gera então um par chave-valor em que a chave é uma string constante (por exemplo, average_liquidity) e o valor é uma tupla contendo a soma e a contagem.
A saída da operação de mapeamento será um conjunto de pares chave-valor que podem ser embaralhados e ordenados por chave e, em seguida, passados para uma operação de redução. A operação de redução receberá um par chave-valor em que a chave é average_liquidity e o valor é uma lista de tuplas contendo a soma e a contagem da liquidez de cada operação de mapeamento. A operação de redução, então, agregará os dados somando as somas e contagens individuais e, em seguida, dividindo a soma final pela contagem final para obter a média geral de liquidez.
# Map step
func map(liquidity_data_chunk,mpt_path_chunk){
var sum = 0
for(int i=0; i<len(liquidity_data_chunk); i++){
verify_inclusion(liquidity_data_chunk[i], mpt_path_chunk[i])
sum += liquidity_data_chunk[i]
}
return ("average_liquidity", (sum, len(liquidity_data_chunk)))
}
# Reduce step
func reduce(liquidity_data_chunk){
var sum = 0
var count = 0
for(int i=0; i<len(liquidity_data_chunk); i++){
sum += value[0]
count += value[1]
}
return ("average_liquidity", sum/count)
}
De maneira geral, podemos generalizar o processo de definição e consumo de uma prova ZKMR para um desenvolvedor em três etapas:
1.Definição de Dataframe e Computações: Uma prova ZKMR é executada em relação a um dataframe, que é um intervalo de blocos e slots de memória específicos dentro desses blocos. No exemplo acima, o dataframe seria um intervalo de blocos nos quais a liquidez é calculada e o slot de memória correspondente à liquidez do ativo em uma DEX.
2.Comprovação de Armazenamento Agrupado e Computação Distribuída: Uma prova ZKMR verifica os resultados das computações realizadas em uma entrada de dataframe específica. Cada dataframe é definido em relação a um cabeçalho de bloco específico. Como parte da verificação da computação, cada prova deve comprovar tanto a existência dos dados de estado subjacentes quanto o resultado da computação dinâmica executada sobre ele. No exemplo acima, isso seria uma operação de média.
3.Verificação da Prova: Uma prova ZKMR pode ser enviada e verificada em qualquer cadeia compatível com EVM (com suporte para mais máquinas virtuais em breve).
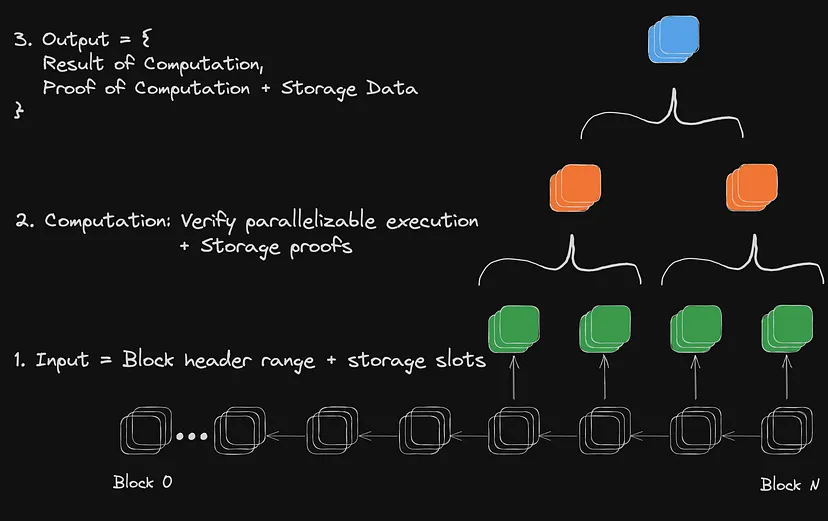 A geração de uma prova ZKMR usando um dataframe de blocos sequenciais
A geração de uma prova ZKMR usando um dataframe de blocos sequenciais
Provas Agnósticas à Camada de Transporte:
Uma das características poderosas das provas ZKMR (e outras provas de ZK Big Data) é sua capacidade de serem agnósticas à camada de transporte. Uma vez que as provas são geradas com base em uma entrada inicial de cabeçalho de bloco, qualquer camada de transporte existente pode optar por gerar e transmiti-las. Isso inclui protocolos de mensagens, oráculos, pontes, observadores/trabalhos cron e até mesmo mecanismos de usuário não confiáveis ou incentivados. A flexibilidade das provas ZKMR permite aumentar drasticamente a expressividade de como o estado está sendo usado entre cadeias, sem precisar competir com infraestruturas de transporte existentes e altamente eficientes.
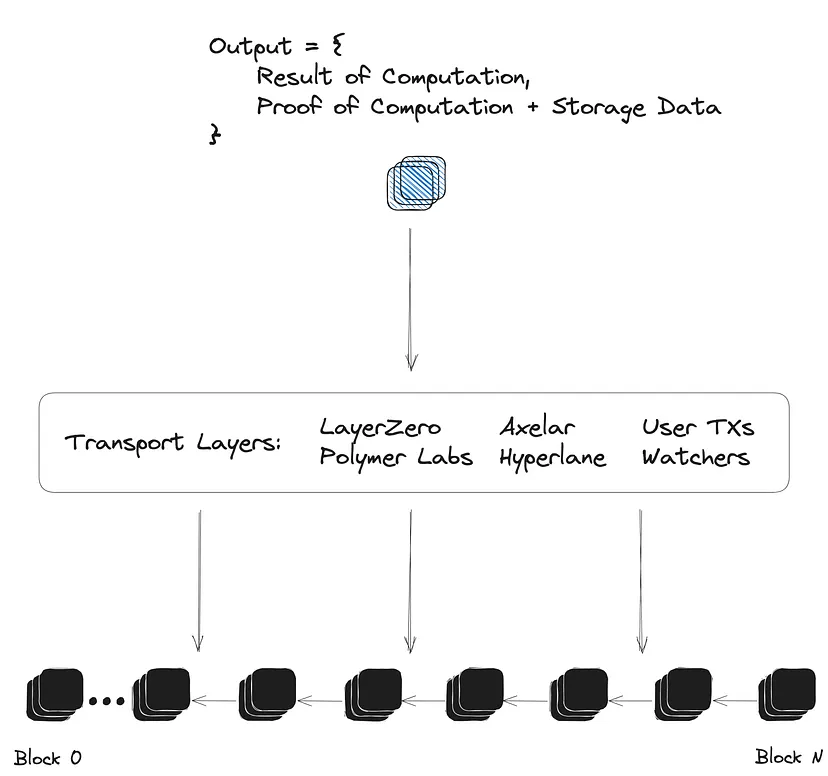 Relé agnóstico da camada de transporte e verificação de uma prova de ZKMR
Relé agnóstico da camada de transporte e verificação de uma prova de ZKMR
O SDK da Lagrange fornece uma interface fácil para integrar provas de ZK Big Data em qualquer protocolo de mensagens ou ponte intercadeias existente. Com uma simples chamada de função, um protocolo pode facilmente solicitar uma prova para o resultado de cálculos arbitrários em um dataframe específico contido em um determinado cabeçalho de bloco.
Ao integrar com um protocolo existente, o ZKMR não foi projetado para fazer afirmações sobre a validade dos cabeçalhos de bloco usados como entrada para as provas. O protocolo de transporte pode provar ou afirmar a validade de um cabeçalho de bloco, como normalmente faria ao passar uma mensagem, mas agora pode incluir também uma computação dinâmica sobre um dataframe de estados históricos.
Vale ressaltar que as provas ZKMR também suportam a combinação de provas de várias cadeias em uma única computação final.
Melhorias de Eficiência do ZKMR:
Embora a abordagem ZKMR possa parecer mais complexa do que a computação sequencial tradicional, seu desempenho escala horizontalmente em relação ao número de processos/máquinas paralelas, em vez de verticalmente em relação ao tempo.
A complexidade de tempo para provar um procedimento ZK MapReduce é O(log(n)) quando executado com paralelização máxima, em oposição à execução sequencial, que tem uma duração de execução de O(n).
Como exemplo, considere a média de liquidez ao longo de 1 dia de dados de blocos Ethereum. A execução sequencial exigiria um loop com 6.643 etapas. A abordagem distribuída com provas recursivas, em vez disso, exigiria uma única operação de mapeamento com até 6.643 threads paralelas, seguida por 12 etapas de redução recursiva. Isso representa uma redução de ~523x na complexidade de tempo de execução.
Conforme continuamos a fragmentar o armazenamento de estado em soluções de escalabilidade, como cadeias de aplicativos, camadas de rollup de aplicativos L3 e alt-L1s, a quantidade de dados on-chain sendo criados está crescendo e se fragmentando exponencialmente. A pergunta pode em breve se tornar: quantos dados serão necessários processar para calcular uma média móvel de 1 semana em uma DEX implantada em 100 diferentes rollups de aplicativos?
Em resumo, o ZKMR é um paradigma poderoso para processar conjuntos de dados em larga escala em um contexto de conhecimento zero em ambientes de computação distribuída. Embora a computação sequencial seja altamente eficiente e expressiva para o desenvolvimento de aplicativos de propósito geral, ela não é otimizada para análise e processamento de grandes conjuntos de dados. A eficiência da computação distribuída a tornou o padrão para grande parte do processamento de big data que predominou no Web2. Em um contexto de conhecimento zero, a escalabilidade e a tolerância a falhas tornam-na a espinha dorsal ideal para lidar com aplicativos de big data confiáveis, como análises complexas de preços, volatilidade e liquidez on-chain.
Contate-nos:
Deseja saber mais sobre a Lagrange?
Visite nosso site em https://lagrange.dev e siga-nos no Twitter em @lagrangedev para se manter atualizado.
Esse artigo é uma tradução feita por @bananlabs. Você pode encontrar o artigo original aqui