
Desbloqueando o poder do YouTube: Aproveite a inteligência coletiva dos vídeos do YouTube e ative conversas inteligentes com o conteúdo.

Introdução
Na era digital de hoje, o YouTube revolucionou a maneira como consumimos e compartilhamos conteúdo de vídeo. De documentários a vídeos de música cativantes, o YouTube oferece uma imensa biblioteca de vídeos que atendem a diversos interesses. Mas e se pudéssemos transformar esse vasto repositório de conteúdo visual em uma conversa interativa e inteligente? Imagine poder conversar com seus vídeos favoritos do YouTube, extrair informações valiosas e participar de discussões instigantes. Esse conceito agora é uma realidade graças aos notáveis avanços da inteligência artificial ( AI ) e à integração inovadora do modelo de linguagem do OpenAI.
Neste blog, orientarei você no processo de criação de um chatbot que transforma sua lista de reprodução do YouTube em uma base de conhecimento abrangente. Ao utilizar o LangChain, uma tecnologia de ponta de processamento de idiomas, podemos aproveitar a inteligência coletiva dos vídeos do YouTube e permitir conversas inteligentes com o conteúdo.
Por meio de uma abordagem passo a passo, cobriremoss principais etapas: como converter vídeos do YouTube em documentos de texto, gerar representações vetoriais do conteúdo e armazená-los em um poderoso banco de dados vetorial. Também nos aprofundaremos na implementação de pesquisas semânticas para recuperar informações relevantes e empregar um grande modelo de linguagem para gerar respostas em linguagem natural.
Para ajudá-lo nessa jornada, usaremos uma combinação de ferramentas poderosas, incluindo LangChain para gerenciamento de conversas, Streamlit para interface de usuário ( UI ) e ChromaDB para o banco de dados vetorial.
Antes de entrarmos no código, entederemos como podemos conseguir isso. Estas são as etapas que seguiremos:
Crie uma lista dos links de vídeo do YouTube que você deseja usar para sua base de conhecimento.
Converter esses vídeos do YouTube em documentos de texto individuais com a transcrição do vídeo.
Converter cada documento em uma representação vetorial usando um Modelo de Incorporação.
Armazenar os empreendimentos no Banco de Dados de Vetorial para recuperação.
Fornecer memória para a capacidade de inferir de conversas anteriores.
Fazer uma pesquisa semântica no Banco de Dados Vetorial para obter os fragmentos relevantes de informações para a resposta.
Usar um modelo de idioma grande para converter as informações relevantes em uma resposta sensata ao idioma natural.
Agora comecemos com o código. Você pode encontrar o código completo no repositório do YouTube vinculado no final desta postagem.
Em um novo diretório, abra o Código VS e, usando o terminal, crie um novo ambiente usando
pip install langchain youtube-transcript-api streamlit-chat chromadb tiktoken openai
Crie um arquivo .env para armazenar sua chave de API OpenAI. Você pode criar uma nova chave de API em https://platform.openai.com/account/api-keys. Adicione a chave ao arquivo .env.
OPENAI_API_KEY = < sua chave api vai aqui >
Em seguida, crie um novo arquivo Python. Vamos chamá-lo youtube_gpt.py. Importe todas as dependências e carregue o ambiente:
from youtube_transcript_api import YouTubeTranscriptApi
# Dependências LangChain
from langchain import ConversationChain, PromptTemplate
from langchain.embeddings import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.document_loaders import TextLoader, DirectoryLoader
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
# Dependências StreamLit
import streamlit as st
from streamlit_chat import message
# Dependências de Ambiente
from dotenv import load_dotenv
import os
load_dotenv()
OPENAI_API_KEY = os.environ.get('OPENAI_API_KEY')
Convertendo os vídeos do YouTube em documentos de texto
Como a primeira etapa do nosso pipeline, precisamos converter uma lista dos seus vídeos favoritos em uma coleção de documentos de texto. Usaremos a biblioteca youtube-transcript-api para isso, que fornece uma transcrição com carimbo de data e hora de todo o vídeo com o video-id como entrada. Você pode obter o ID do vídeo da última sequência de caracteres no link do vídeo do YouTube. Por exemplo, https://www.youtube.com/watch?v=GKaVb3jc2No, o vídeo-id é GKaVb3jc2No
video_links = ["https://www.youtube.com/watch?v=9lVj_DZm36c", "https://www.youtube.com/watch?v=ZUN3AFNiEgc", "https://www.youtube.com/watch?v=8KtDLu4a-EM"]
if os.path.exists('transcripts'):
print('Directory already exists')
else:
os.mkdir('transcripts')
for video_link in video_links:
video_id = video_link.split('=')[1]
dir = os.path.join('transcripts',video_id )
print(video_id)
transcript = YouTubeTranscriptApi.get_transcript(video_id)
with open(dir+'.txt', 'w') as f:
for line in transcript:
f.write(f"{line['text']}\n")
Isso criará um novo diretório com o nome transcripts, que terá documentos de texto com o ID do vídeo como nome do arquivo. Dentro dele, você pode ver a transcrição do arquivo.
Carregue os documentos no LangChain e crie um banco de dados vetorial
Após termos os documentos de transcrição, precisamos carregá-los no LangChain usando DirectoryLoader e TextLoader. O que DirectoryLoader faz é, ele carrega todos os documentos em um caminho e os converte em pedaços usando TextLoader. Salvamos esses arquivos de texto convertidos na interface loader. Após carregados, usamos a ferramenta Embeddings do OpenAI para converter os pedaços carregados em representações vetoriais que também são chamadas de incorporações. Em seguida, salvamos as incorporações no banco de dados vetorial. Aqui usamos o banco de dados vetorial do ChromaDB.
No código a seguir, carregamos os documentos de texto, os convertendo em incorporações e salvando no banco de dados vetorial.
loader = DirectoryLoader(path='./', glob = "**/*.txt", loader_cls=TextLoader,
show_progress=True)
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
index = VectorstoreIndexCreator(embedding=embeddings).from_loaders([loader])
Vejamos o que está acontecendo aqui:
Criamos um objeto
DirectoryLoadernomeadoloader. Este objeto é responsável por carregar documentos de texto de um caminho especificado. O caminho é definido para o diretório atual ('./'). O parâmetroglobé definido como"**/*.txt", que especifica que queremos carregar todos os arquivos de texto (*.txt) recursivamente (**) do caminho especificado. O parâmetroloader_clsé definido comoTextLoader, indicando que queremos usar a classeTextLoaderpara processar cada arquivo de texto. O parâmetroshow_progressé definido comoTrue, permitindo a exibição do progresso durante o processo de carregamento.Em seguida, criamos uma instância de
OpenAIEmbeddingsnomeadoembeddings. Esse objeto é responsável por converter documentos de texto em representações vetoriais (embeddings) usando o modelo de idioma do OpenAI. Passamos oopenai_api_keyobtido das variáveis de ambiente para autenticar e acessar a API OpenAI.Por fim, criamos uma instância de
VectorstoreIndexCreatornomeadoindex. Esse objeto é responsável por criar um índice vetorial para armazenar as incorporações dos documentos de texto. Por padrão, isso usachromadbcomo a loja de vetores. Passamos o objetoembedding(embeddings) para oVectorstoreIndexCreatorpara associá-lo ao processo de criação de índice. O métodofrom_loaders()é chamado no objetoVectorstoreIndexCreator, e passamos o objetoloader(contendo os documentos de texto carregados ) como uma lista para carregar os documentos no índice.
Fornecendo memória
Para continuar uma conversa com o nosso YouTube Bot, precisamos fornecer uma memória onde ele possa armazenar as conversas que está tendo nessa sessão. Usamos o mesmo banco de dados vetorial que criamos anteriormente como memória para armazenar conversas. Podemos fazer isso usando este código:
retriever = index.vectorstore.as_retriever(search_kwargs=dict(k=5))
memory = VectorStoreRetrieverMemory(retriever=retriever)
Neste snippet de código, criamos dois objetos: retriever e memory.
O objeto retriever é criado acessando o atributo vectorstore do objeto index, que representa o índice vetorial criado anteriormente. Usamos o método as_retriever() no vectorstore para convertê-lo em um recuperador, o que nos permite executar operações de pesquisa. O parâmetro search_kwargs é fornecido com um dicionário contendo as configurações de pesquisa. Nesse caso, k=5 especifica que queremos recuperar os 5 principais resultados mais relevantes.
O objeto memory é criado passando o objeto retriever como parâmetro para a classe VectorStoreRetrieverMemory. Esse objeto serve como um componente de memória que armazena o recuperador e permite a recuperação eficiente dos resultados.
Essencialmente, esses dois objetos configuram o mecanismo de recuperação para pesquisar e recuperar informações relevantes do índice vetorial. O retriever executa as operações de pesquisa reais e o componente memory ajuda a gerenciar e otimizar o processo de recuperação.
Crie uma cadeia de conversação
_DEFAULT_TEMPLATE = """The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Relevant pieces of previous conversation:
{history}
(You do not need to use these pieces of information if not relevant)
Current conversation:
Human: {input}
AI:"""
PROMPT = PromptTemplate(
input_variables=["history", "input"], template=_DEFAULT_TEMPLATE
)
llm = OpenAI(temperature=0.7, openai_api_key=OPENAI_API_KEY)
# Pode ser qualquer LLM válido
conversation_with_summary = ConversationChain(
llm=llm,
prompt=PROMPT,
# Definimos um max_token_limit muito baixo para fins de teste.
memory=memory,
)
Aqui, definimos um modelo de conversa padrão e criamos uma instância do ConversationChain.
O _DEFAULT_TEMPLATE é uma sequência que contém um modelo de conversa amigável entre um humano e uma IA. Inclui uma seção para partes relevantes do histórico de conversas anterior e uma seção para a conversa atual onde a entrada humana será inserida. O modelo usa variáveis de espaço reservado, como {history} e {input} para ser substituído pelos detalhes reais da conversa.
O PROMPT é criado usando a classe PromptTemplate , que pega as variáveis de entrada history e input, e o _DEFAULT_TEMPLATE como o modelo.
Em seguida, criamos uma instância do modelo OpenAI de linguagem chamado llm. É inicializado com um valor de temperatura de 0,7, que controla a aleatoriedade das respostas do modelo. A openai_api_key é fornecida para autenticar e acessar a API OpenAI. Observe que llm pode ser substituído por qualquer modelo de idioma válido.
Finalmente, criamos uma instância de ConversationChain chamada conversation_with_summary. É inicializado com o objeto llm, o PROMPT, e o objeto memory ( que criamos anteriormente ). O memory serve como componente de recuperação para acessar informações relevantes do índice vetorial. O ConversationChain encapsula a lógica e a funcionalidade de gerar respostas com base no histórico de conversas e na entrada atual usando o modelo de idioma especificado.
No geral, esse código configura o modelo de conversa, o modelo de idioma e o mecanismo de recuperação de memória para o ConversationChain, que será usado para gerar respostas inteligentes no chatbot desenvolvido pelo YouTube.
Crie a interface do usuário
Em seguida, configuramos a interface do usuário para o chatbot, que mostra as mensagens e fornece na caixa de texto de entrada para interagir com o bot.
st.header("YouTubeGPT")
if 'generated' not in st.session_state:
st.session_state['generated'] = []
if 'past' not in st.session_state:
st.session_state['past'] = []
def get_text():
input_text = st.text_input("You: ","Hello, how are you?", key="input")
return input_text
user_input = get_text()
if user_input:
output = conversation_with_summary.predict(input = user_input)
st.session_state.past.append(user_input)
st.session_state.generated.append(output)
if st.session_state['generated']:
for i in range(len(st.session_state['generated'])-1, -1, -1):
message(st.session_state["generated"][i], key=str(i))
message(st.session_state['past'][i], is_user=True, key=str(i) + '_user')
Aqui está uma visão geral do que o código faz:
A linha do
st.header("YouTubeGPT")exibe um cabeçalho intitulado "YouTubeGPT" no aplicativo Streamlit.O código verifica se as teclas ‘ geradas ’ e ‘ passadas ’ estão presentes no
st.session_state. Se eles não estiverem presentes, listas vazias serão atribuídas a essas chaves.A função
get_text()é definida para recuperar a entrada do usuário por um campo de entrada de texto usandost.text_input(). O valor padrão para o campo de entrada está definido como "Olá, como você está?". A função retorna o texto de entrada do usuário.A variável
user_inputé atribuída o valor retornado porget_text().Se o
user_inputnão está vazio, o métodoconversation_with_summary.predict()é chamado com a entrada do usuário como o parâmetro 'input. A saída gerada do chatbot é atribuída a variáveloutput.A entrada do usuário e a saída gerada são anexadas às listas ‘ passado ’ e ‘ geradas ’ nas listas
st.session_state, respectivamente.Se houver saídas geradas armazenadas no
st.session_state['generated'], um loop é iniciado para iterar através deles na ordem inversa.Para cada saída gerada e entrada do usuário correspondente, a função
message()é chamada para exibi-las como mensagens no aplicativo Streamlit. O parâmetro 'key' é usado para diferenciar entre mensagens diferentes.É isso aí. Agora você pode executar seu aplicativo usando este comando no terminal
É isso aí. Agora você pode executar seu aplicativo usando este comando no terminal
streamlit run youtube_gpt.py
É assim que será. Neste exemplo, usei algumas críticas de laptop como vídeos.
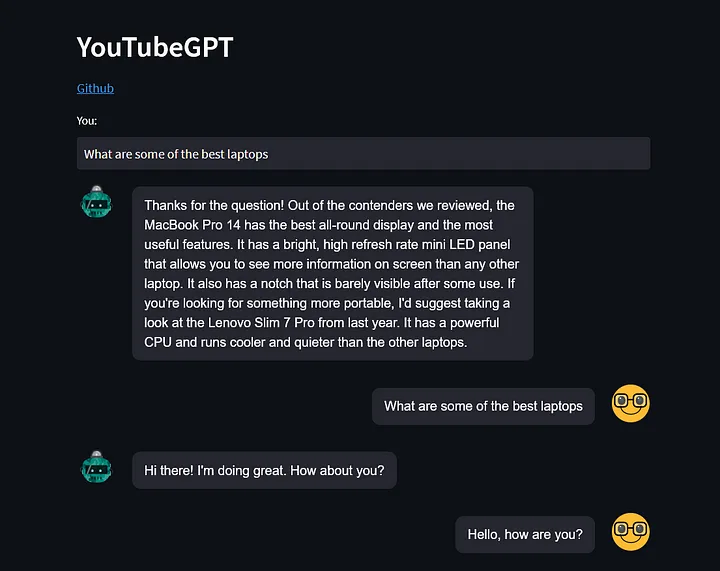
Repositório Git: https://github.com/akshayballal95/youtube_gpt.git
Este artigo foi escrito por Akshay Ballal e traduzido por Adriano P. de Araujo. O original em inglês pode ser encontrado aqui.