
Esse artigo é uma tradução de (Sicong Zhao) feita por (Diogo Jorge). Você pode encontrar o artigo original aqui. (https://medium.com/@luo9137/ai-in-web3-745fd2fe1f51).
Discutiremos o paradigma de adoção de inteligência artificial em Web3, com um projeto premiado.
Na Web 2.0, os algoritmos de machine learning rodam em servidores centralizados, comprometendo nossa privacidade enquanto oferece uma boa UX. Em relação à Web 3.0, deveria existir um novo paradigma para adoção da inteligência artificial. Neste artigo vou compartilhar minhas ideias sobre como embarcar a inteligência artificial na Web3.0. Juntamente com minha primeira tentativa, PrivateAI, um projeto premiado na ETHGlobal Hackathon.
Disclaimer: Este é um dos raros artigos que discutem inteligência artificial em Web3.0 em profundidade, com soluções técnicas práticas. Dado que o tópico é tão novo, e esta área não tem sido completamente explorada, alguma coisa deve ter que ser atualizada no futuro. Por favor, seja generoso e ofereça suas opiniões/feedbacks para ajudar com este processo.
Sumário
1 . Fundamentos ..... . A Arquitetura de uma aplicação de Web 3.0 ..... . O Propósito dos algoritmos de inteligência artificial
2 . Inteligência artificial e os Paradigmas da Web3 ..... . Parecidos com Web2 ..... . Melhores Práticas para Algoritmos Customizados ..... . Melhores Práticas para Algoritmos de Propósito Genérico ..... . PrivateAI
Fundamentos
Para começar, eu quero arranhar a superfície de dois conceitos fundamentais: (1) A Arquitetura de uma aplicação de Web 3, (2) O Propósito dos algoritmos de inteligência artificial. A futura discussão será baseada nestes conceitos.
A Arquitetura de uma aplicação de Web 3
 Fig.1 A Arquitetura de uma aplicação de Web 3.0
Fig.1 A Arquitetura de uma aplicação de Web 3.0
Existem três elementos. O Front-end não é diferente daqueles da Web 2.0, exceto que ele conecta diretamente a uma Blockchain ou indiretamente através de um Provedor.
Do ponto de vista da arquitetura, inteligência artificial pode ser adotada em todos os três componentes e aqui veremos como. No Front-end, TensorFlow.js habilita modelos de aprendizado de máquina e treinamento dentro dos navegadores. O Provedor é mais como um ambiente centralizado de Web 2.0, então a inteligência artificial pode ser aplicada sem atritos. Adicionalmente, smart contracts rodando na Blockchain podem implementar gradient descent (descida gradual) ou resolver parâmetros de modelos para aprendizado de máquina de closed form (forma fechada).
O Propósito dos algoritmos de inteligência artificial
Existem abordagens diferentes de classificar algoritmos de inteligência artificial. Aqui eu estou mergulhando inteligência artificial em Algoritmos Customizados e Algoritmos de Propósito Genérico. O primeiro dá um resultado único com base na identidade do solicitante (eg. Feed do Youtube), e o último é sem identidade (eg. detecção de Spam).
Inteligência artificial e os Paradigmas da Web3
Com base na discussão anterior, agora nós podemos montar a seguinte matriz para definir os 6 cenários para adoção de inteligência artificial na Web 3.0. O objetivo desta sessão é descobrir a melhor prática teórica entre esses cenários. Vamos nos aprofundar em cada um deles.
 Fig.2 Cenários para IA em Web3
Fig.2 Cenários para IA em Web3
Parecidos com Web2
Primeiro, eu gostaria de excluir o cenário 2 e 5. Eles são essencialmente Web2 e compartilham os mesmos atributos.
Melhores Práticas para Algoritmos Customizados
Em seguida, para necessidades customizadas, nós podemos tanto rodar inteligência artificial no Front-end ou nos smart contracts na Blockchain. Eu acho que o último é uma solução melhor com base na seguinte comparação.
 Fig.3 Comparação entre cenário 1 e 3
Fig.3 Comparação entre cenário 1 e 3
Em termos de custo, rodar o TensorFlow.js no Front-end custa quase nada, apenas uma força computacional mínima. Entretanto, se forem usados os smart contracts para rodar o algoritmo de inteligência artificial, então para cada usuário um novo smart contract vai ser feito deploy e treinado. Fazer o deploy pode custar muito, mas os custos de treinamento, o qual atualiza potencialmente um grande número de parâmetros dentro de um contrato por centenas de milhares de vezes, pode ser inesperadamente alto. É verdade que alguém pode treinar o modelo, encontrar o parâmetro ótimo antes de fazer o deploy de um smart contract. Entretanto, isto requer expertise técnica, a qual é inviável para produtos com base em consumidores. Ainda mais os altos custos de fazer deploy. Então, o cenário 1 é claramente o vencedor em termos de custo.
Em termos de privacidade, manter todos os dados dentro de seu navegador é claramente uma solução mais segura. No cenário 3, para treinar o smart contract, usuários podem precisar expor seus dados pessoais. E os modelos treinados que vivem dentro de smart contracts são abertos, o que também leva a preocupações com a privacidade. Portanto, o cenário 1 vence novamente.
Em termos de velocidade, esta é a parte que eu não tenho tanta certeza. Eu acho que a velocidade do cenário 1 é aceitável para aplicações normais, como demonstrado na seção final deste artigo. Para a velocidade da EVM eu não tenho certeza. Eu devo fazer algum experimento no futuro. Por favor me avise se você tiver alguma ideia! Neste artigo eu vou apenas considerar que eles tem velocidade similar com base na minha experiência chamando a função view dentro dos contratos.
Resumindo, para Algoritmos Customizados, você deve preferir implementar ele dentro do Front End usando TensorFlow.js. Porém, há um lado ruim, fazendo isso o front-end deve exigir mais dados do que necessário da Blockchain. Como resultado isso pode drenar a memória e influenciar negativamente a performance do navegador.
Melhores práticas para de Algoritmos de Propósito Genérico
Então, para algoritmos de Propósito Genérico as coisas são diferentes, uma vez que não há necessidade de instanciar um smart contract por usuário.
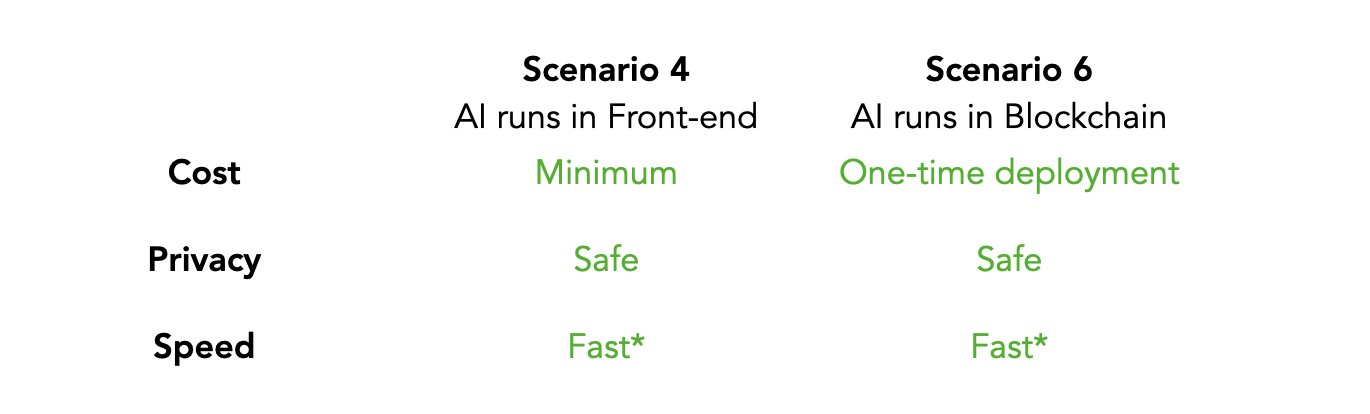 Fig.4 Comparação entre cenário 4 e 6
Fig.4 Comparação entre cenário 4 e 6
Em termos de custo, o cenário 4 é idêntico ao cenário 1, TensorFlow.js custa quase nada. Para o cenário 6, o smart contract pode ser feito deploy apenas uma vez e servir a todos.
Em termos de privacidade, uma vez que tarefas de propósito genérico normalmente não requerem dados de usuários, ambas soluções são seguras.
Em termos de velocidade, a comparação ainda é idêntica à seção anterior. Sem evidência concreta, eu assumiria que elas são similares.
Resumindo, pessoalmente eu ainda usaria TensorFlow.js no front-end, simplesmente porque eu acho que é mais fácil de implementar. Entretanto, eu não acho que haja um vencedor claro até que eu aprenda mais sobre as diferenças em velocidade.
PrivateAI
Eu participei na LFGrow Hackathon, e venci o prêmio de Mais Criativo uso de ML, e também um prêmio Finalista (top 10 projetos).
Este projeto usa modelos de inteligência artificial rodando em navegador para melhorar a experiência do usuário em um dApp de rede social. Existem dois modelos: (1) O primeiro modelo detecta informação maliciosa e protege usuários contra ela. Este é um modelo pré-treinado com base em comentários tóxicos online oferecidos pelo TensorFlow. (2) O segundo modelo ajuda a recomendar à mídia social informações baseadas nas preferências dos usuários. Quando os usuários dão like/dislike em um conteúdo, esta informação será usada para treinamento de modelos que acontecem dentro do navegador. Com o tempo, o modelo estará melhor em recomendar/esconder postagens com base na preferência dos usuários. Uma vez que os modelos de treinamento acontecem nos navegadores os dados estão sempre no navegador, para assim garantir a segurança dos dados.
Aqui está o vídeo de demonstração:
https://www.youtube.com/watch?v=o5s3Pr1xzTg
O Fim
Então aí está! Eu vou continuar trabalhando no PrivateAI, potencialmente tornando-se uma ferramenta de desenvolvimento que o desenvolvedor pode usar para adicionar inteligência artificial ao seu dApp. Me avise caso você queira fazer uma parceria comigo! Eu posso fazer tudo, mas estou passivamente buscando parcerias e aprendizado com pessoas ótimas. Juntos podemos alcançar algo maior.
Que entrar em contato? Sinta-se à vontade para contatar (my Linkedln) ou Discord Saikong#4009