

Introdução
Este artigo investiga o emocionante reino da IA verificável, com foco na integração de ZK-Snarks recursivos e esquemas de dobramento. O objetivo principal é combinar o processo de inferência de um modelo de rede neural em circuitos de conhecimento zero. Esses circuitos, escritos em Circom, fornecem uma estrutura poderosa para agrupar inferências repetidas em uma única instância, aumentando assim a eficiência e a privacidade.
Índice
·Introdução ·Índice ·OK, eu conheço ZK, mas o que diabos é ZKML? ·O que é Nova? ·Como o Nova pode ser usado em IA verificável (ZKML)? ∘Caso 1 ∘Caso 2 ·Como o Banana SDK está usando ZKML e Nova? ∘ID facial privado ∘Guardião para Triagem de Transações ·Conclusão
OK, eu conheço ZK, mas o que diabos é ZKML?
ZK-Snarks ganharam força significativa em aplicações blockchain devido à sua concisão e segurança. No campo de aprendizado de máquina, aprendizado profundo e IA, o ZK-Snarks oferece um enorme potencial. À medida que a utilização de ferramentas de IA, como ChatGPT e MidJourney, continua a aumentar, garantir a integridade desses sistemas e do conteúdo que eles geram torna-se crucial. O ZK-Snarks fornece uma solução viável para alcançar esta verificação. No entanto, a questão permanece: como podemos efetivamente alcançar a privacidade com a IA?
Os modelos de IA empregados em diversas aplicações dependem de uma ampla gama de parâmetros, muitas vezes abrangendo bilhões de pesos (weights) em redes neurais profundas. Por exemplo, o Chat GPT 4 emprega surpreendentes 100 trilhões de pesos para calcular sua produção. Um desafio predominante associado às inferências de modelos baseados em API é a falta de transparência em relação ao modelo específico usado para gerar o resultado.
Consequentemente, é possível que os utilizadores paguem pelo acesso a uma versão premium de um modelo, apenas para terem o resultado calculado utilizando um conjunto inferior de pesos. Embora isso possa ser irrelevante para tarefas triviais, torna-se extremamente importante em domínios como inferências médicas ou tomada de decisões financeiras, onde a precisão e a fiabilidade dos resultados da IA são fundamentais.
O que é Nova?
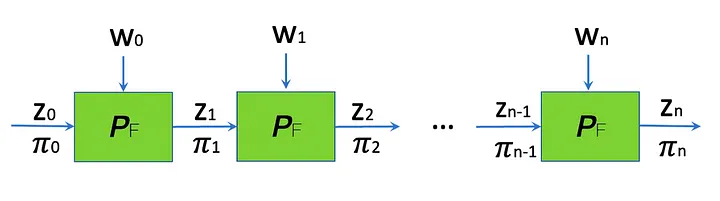
CIV
O Nova permite a geração recursiva de provas para argumentos zk, fornecendo um meio de demonstrar a execução de um conjunto específico de instruções de circuito N vezes, ao mesmo tempo que elimina etapas redundantes. Esta abordagem oferece ganhos de eficiência significativos. Por exemplo, considere um cenário onde há 10 assinaturas a serem verificadas. Em vez de executar o circuito dez vezes e gerar dez provas zk para verificação, Nova dobra o cálculo do circuito em uma única instância do R1CS, agilizando o procedimento geral de verificação.
O Nova adota uma abordagem diferida na construção de uma Computação Incrementalmente Verificável (CIV), o que elimina a necessidade de provas SNARK em cada etapa. O esquema de dobramento empregado em Nova facilita a consolidação de duas instâncias NP (Xi, Wi) em uma única instância NP dobrada, abrangendo provas da instância dobrada. Ao aproveitar esta abordagem, o processo de verificação é simplificado, resultando em maior eficiência e desempenho computacional.
Originalmente, o provador CVI gera uma prova para cada passo incremental, garantindo a correção do cálculo. Esta prova inclui um circuito aumentado que incorpora um “circuito verificador” para verificar a prova da etapa anterior. Recursivamente, a prova final prova a correção de todo o cálculo incremental. Essa verificação pode ser alcançada usando ciclos de curva, como curvas Pasta. Como sabemos, existem dois campos de uma curva elíptica, o campo base e o campo escalar. Nesta verificação recursiva, o verificador utiliza uma curva elíptica onde os campos são trocados.
Curvas Pasta para recursão
O Nova aproveita um sistema Rank-1 de restrição (R1CS) relaxado para permitir seu esquema de dobramento. Enquanto o R1CS tradicional é uma linguagem que se enquadra na categoria NP-completa, servindo como uma generalização da satisfatibilidade do circuito aritmético, a versão relaxada do Nova introduz flexibilidade. As matrizes A, B e C em R1CS fornecem informações essenciais sobre portas para um sistema de restrições específico.
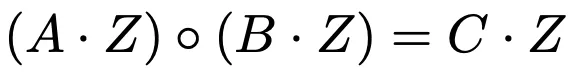
Z é o vetor de solução e consiste em ‘x’ e ‘W’, onde ‘x’ são as entradas públicas e ‘W’ é a testemunha privada. Vamos inserir Z primeiro para completar a avaliação dos polinômios e então a prova é dada ao verificador para verificação através de pares bilineares (pelo menos isso acontece em Groth’16).
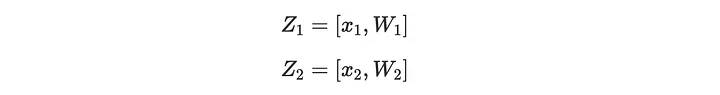
Agora, se tentarmos combinar dois vetores de solução, Z1 e Z2, com uma combinação linear aleatória em R1CS normal.
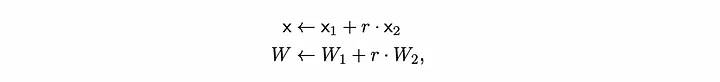
Combinação Linear Aleatória
Depois de inserir os valores da combinação linear aleatória:
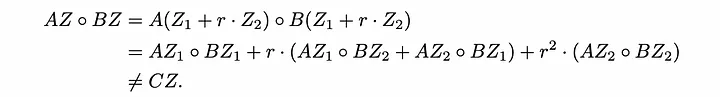
Como podemos ver, isso não está funcionando e estamos obtendo muitos termos cruzados e potência quadrática de 'r'.
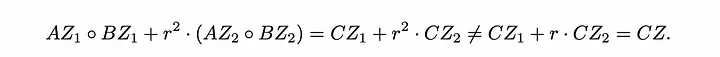
Usamos o R1CS relaxado aqui para acomodar esses termos extras:
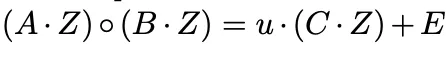
Usamos um vetor Slack E para absorver os termos cruzados e um escalar u para as potências extras de 'r':
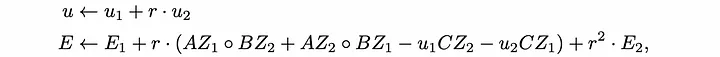
Depois de usar essas modificações, agora temos que nos comprometer com duas coisas: testemunha W e vetor de folga E.
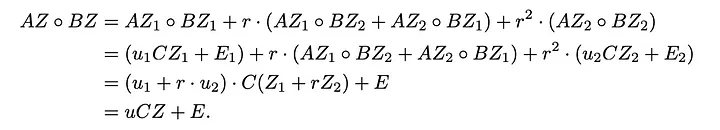
As restrições geradas na etapa final são usadas com prova oracle interativa (POI), ou seja, Spartan para gerar as provas. Esta é uma introdução de alto nível ao Nova e mais detalhes podem ser encontrados no documento.
Como o Nova pode ser usado em IA verificável (ZKML)?
Caso 1
Em modelos de redes neurais, cada inferência envolve operações de multiplicação de matrizes entre camadas. Essas operações apresentam padrões repetitivos quando a arquitetura de camadas consecutivas, como as camadas 1, 2 e 3, permanece a mesma, contendo um número idêntico de neurônios ou ativações. Nova oferece uma solução para lidar eficientemente com essas multiplicações repetitivas através de uma técnica de dobramento.
Dentro do circuito, a multiplicação entre duas camadas (por exemplo, L1 e L2) é implementada, e este circuito é então utilizado pelo Nova para realizar o dobramento N vezes. Dobrar uma combinação linear aleatória é um processo computacionalmente eficiente que utiliza Multiplicações Seguras Multipartidárias (MSMs), que são mais eficientes do que as Transformadas Rápidas de Fourier (TFR) não paralelizáveis. Este processo de dobragem produz uma única reivindicação que abrange todas as N etapas ou camadas.
O envolvimento de máquinas SNARK caras só é necessário para provar esta única instância. Isso ocorre quando a instância dobrada gerada pelo Nova é alimentada em um SNARK como o Spartan, facilitando a criação de uma prova sucinta. Aproveitando essa técnica de dobramento e a integração de Nova e Spartan, provas eficientes e concisas podem ser alcançadas para os cálculos da rede neural dobrada.
Uma limitação da abordagem acima mencionada é a sua exigência de camadas intermediárias de tamanho fixo na rede neural, o que pode nem sempre ser viável. Redes modernas e poderosas geralmente empregam camadas de tamanhos variados. No entanto, essa limitação pode ser superada utilizando o SuperNova, que oferece maior flexibilidade ao acomodar múltiplos circuitos.
O Super Nova distingue-se pela introdução de um modelo de custo no qual o custo de provar uma etapa do programa depende exclusivamente do tamanho do circuito que representa a instrução executada por essa etapa. Isto representa um afastamento significativo das metodologias anteriores que empregavam circuitos universais, onde o custo de provar uma etapa do programa é normalmente proporcional à soma dos tamanhos dos circuitos que representam todas as instruções suportadas. Notavelmente, apesar de uma etapa do programa invocar apenas uma instrução específica, as abordagens anteriores ainda incorrem em custos associados a todas as instruções suportadas.
Caso 2
Podemos ter outro modelo onde podemos ter todo o modelo ML dentro do circuito Circcom. Isso inclui todas as camadas do circuito, ou seja, há uma entrada para os dados e a saída é diretamente o resultado do modelo. Isso pode ser usado quando precisamos fazer inferências a partir de um grande número de pontos de dados. Em cada etapa podemos calcular a saída e verificar uma determinada condição ou agregar os resultados da inferência com uma prova SNARK, finalmente, de que todo o cálculo foi feito corretamente em cada etapa incremental. O Nova emprega um esquema de dobramento para sistemas não interativos e instancia uma única instância R1CS relaxada no início do cálculo e dobra-a N vezes.
O modelo no início é alimentado com algumas entradas públicas e testemunhas privadas e, em seguida, realizando a inferência para uma amostra, o termo de erro é calculado e um compromisso com esse termo de erro é mantido para o verificador. Ao contrário de outras CVIs, a prova não é gerada sempre que uma amostra é concluída. Em vez disso, estamos aproveitando a propriedade de que as matrizes A, B e C do RICS são fixas em todos os circuitos e apenas o vetor solução está mudando. Portanto, o vetor solução torna-se um RLC do vetor solução atual e anterior. Isso leva à geração de termos cruzados que são então calculados e comprometidos (committed).
Como o Banana SDK está usando ZKML e Nova?
Atualmente no Banana SDK, temos como alvo dois casos de uso de ZKML:
ID facial privado
O reconhecimento facial privado para recuperação de carteira é uma área crítica de exploração para contas Banana. Atualmente, nossa solução de recuperação de carteira depende de computação multipartidária (CMP) segura, que envolve o armazenamento de fragmentos de recuperação em diferentes entidades. No entanto, para conseguir uma maior descentralização e aumentar a privacidade do usuário, estamos investigando a integração de redes neurais privadas e argumentos de conhecimento sucintos e não interativos de conhecimento zero (ZK-SNARKs) para reconhecimento facial.
Ao aproveitar redes neurais privadas, os usuários terão a capacidade de escanear seus rostos para fins de recuperação. As características faciais serão correspondidas e a verificação da prova anexa validará a correção do rosto. Essa abordagem elimina a dependência de entidades centralizadas e oferece uma solução mais segura e que preserva a privacidade para recuperação de carteiras.
Através dos nossos esforços contínuos de investigação e desenvolvimento, pretendemos avançar no campo do reconhecimento facial privado e contribuir para a evolução de soluções descentralizadas e centradas no usuário. Estamos empenhados em ultrapassar os limites da inovação para fornecer aos nossos usuários mecanismos de recuperação de carteira robustos e seguros. Fique ligado nas atualizações sobre este desenvolvimento emocionante.
Guardião para Triagem de Transações
O estado atual de Passkeys (Chaves de acesso) representa um risco potencial, pois os dados da transação antes da assinatura permanecem invisíveis. Essa falta de visibilidade aumenta a probabilidade de os usuários assinarem mensagens e transações incorretas sem saber. Para resolver esse problema, uma solução simples envolve a implementação de uma caixa de diálogo que exibe detalhes da transação antes do prompt de autenticação da chave de acesso, garantindo a conscientização do usuário.
No entanto, surge o desafio de evitar que atores mal-intencionados exibam pop-ups com informações enganosas. Para resolver isso, é necessário um guardião na rede para mitigar as transações de phishing. Esse guardião contaria com um modelo de classificação, operando dentro de um ZK-SNARK, para identificar transações potencialmente fraudulentas. O modelo de classificação considera as informações da transação como variáveis privadas, produzindo um resultado acompanhado de uma prova.
É importante notar que essa solução está atualmente na sua fase inicial e requer um refinamento substancial em termos de arquitetura e design gerais. Mais exploração e desenvolvimento são necessários para otimizar a funcionalidade e a segurança do sistema.
Ao enfrentar esses desafios e avançar na arquitetura, pretendemos aumentar a confiabilidade e a credibilidade das transações baseadas em Passkey. Pesquisas e melhorias contínuas serão fundamentais no estabelecimento de uma estrutura robusta e segura para autenticação de usuários e verificação de transações.
Conclusão
Este espaço está sendo alvo de pesquisas ativas recentemente e veremos muitos avanços em termos de comprovação do lado do cliente em IA verificável. Com o advento dos LLMs, podemos ver o espaço da IA crescendo. Precisaremos de mais sistemas que permitam privacidade, que os usuários possam usar sem comprometer suas informações privadas e que a transparência completa seja mantida pelos usuários. Espero que você tenha gostado de ler o artigo e adoraria ter um feedback seu. Por favor, deixe seus comentários abaixo ou entre em contato comigo no Twitter.
Por fim, gostariamuito de receber qualquer feedback ou crítica construtiva se houver alguma área que precise de melhorias. Sua contribuição é altamente valorizada e nos ajudará a melhorar a qualidade do nosso trabalho. Desde já agradecemos por dedicar seu tempo para fornecer seus valiosos insights.
Gostaria de expressar minha sincera gratidão a Dr Cathie, e Nitanshu pela sua inestimável contribuição na revisão deste trabalho. Seu feedback perspicaz e experiência melhoraram muito a qualidade deste artigo.
Créditos da foto da capa para Divyam.
Este artigo foi escrito por Rishabh Gupta e traduzido por Diogo Jorge. O artigo original pode ser encontrado aqui.