
Vamos imaginar que você precise acessar os dados em tempo real de alguns contratos inteligentes na Ethereum (ou Polygon, BSC etc.), como o Uniswap ou até mesmo a moeda PEPE, para analisar seus dados usando as ferramentas padrão de cientista/analista de dados: Python, Pandas, Matplotlib, etc. Neste tutorial, mostrarei ferramentas de acesso a dados mais sofisticadas que se assemelham mais a um bisturi cirúrgico (subgrafos do The Graph) do que a um canivete suíço bem conhecido (acesso a nós RPC) ou a um martelo (APIs prontas para uso). Espero que minhas metáforas não o assustem 😅.

Há alguns métodos diferentes para acessar os dados na Ethereum:
- Usar comando de nó RPC getBlockByNumber para obter as informações de bloco de baixo nível e, em seguida, acessar os dados do contrato inteligente por meio de bibliotecas como web3.py. Ele permite que você obtenha os dados bloco a bloco e, em seguida, colete-os em seu próprio banco de dados ou arquivo CSV. Esse método não é muito rápido e a análise de dados de contratos inteligentes populares usando esse método geralmente leva anos.
- Usar alguns provedores de análise de dados, como o Dune, que pode ajudá-lo com alguns dados populares de contratos inteligentes, mas não é realmente em tempo real. A latência pode ser de vários minutos.
- Usar algumas APIs prontas para uso, como NFT API/Token API/DeFi API. E essa pode ser uma excelente opção, pois geralmente a latência é baixa. O único problema que você pode enfrentar é que os dados de que precisa não estejam disponíveis. Por exemplo, nem todas as variáveis podem estar disponíveis como séries temporais históricas.
E se você ainda quiser ter dados de um contrato inteligente em tempo real, mas não estiver satisfeito com as soluções anteriores, porque você quer tudo:
- Você deseja dados de baixa latência (os dados estão sempre atualizados logo após a mineração de um novo bloco).
- Você precisa de uma porção personalizada de dados que não está disponível em nenhuma API pronta para uso.
- Você não quer se preocupar com o processamento manual dos dados bloco a bloco e com as reorganizações dos blocos de processamento.
Esse é o melhor caso de uso dos subgrafos do The Graph. Essencialmente, o The Graph é uma rede descentralizada para acessar dados de contratos inteligentes de forma descentralizada, pagando o preço das solicitações em tokens GRT.
Mas a tecnologia subjacente chamada "subgrafos" permite que você transforme sua descrição simples de quais variáveis precisam ser salvas (para acesso em tempo real) na segmentação de instruções (pipeline) ETL de nível de produção que:
- Extrai dados do blockchain.
- Salva-os no banco de dados.
- Torna esses dados acessíveis por meio da interface GraphQL.
- Atualiza os dados depois que cada novo bloco é minerado na rede.
- Processa automaticamente as reorganizações da cadeia.
Isso é muito importante. Você não precisa ser um engenheiro de dados altamente qualificado com experiência em blockchains compatíveis com EVM para configurar todo o fluxo de trabalho.
Mas vamos começar com algo pronto para usar. E se alguém já tiver desenvolvido um subgrafo que o ajude a acessar os dados de que você precisa?
Você pode acessar o site do serviço hospedado no The Graph, encontrar a seção de subgrafos da comunidade e tentar obter os subgrafos existentes no protocolo de que precisa. Por exemplo, vamos encontrar um subgrafo para acessar o protocolo Lido (que permite que os usuários coloquem seus Ethers em stake sem limitar o valor mínimo de 32 ethers, como é normalmente o caso e, além disso, obter os tokens que podem ser colocados em stake novamente, dá para acreditar nisso?😅).
O protocolo Lido está atualmente entre os primeiros em termos de TVL (Total Value Locked - valor total bloqueado - uma métrica usada para medir o valor total dos ativos digitais que estão bloqueados ou em stake em uma determinada plataforma DeFi ou DApp) de acordo com DeFiLlama.
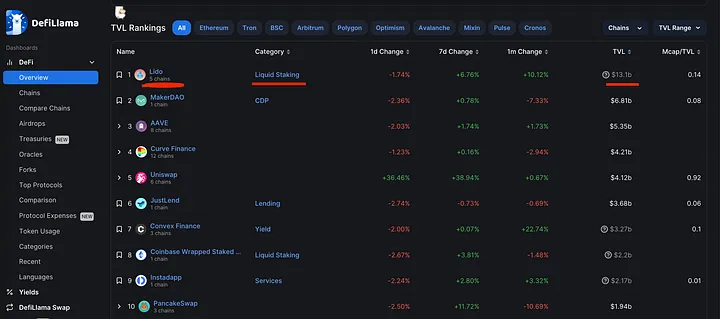
E aí está! O subgrafo feito pelo time do Lido está aqui.
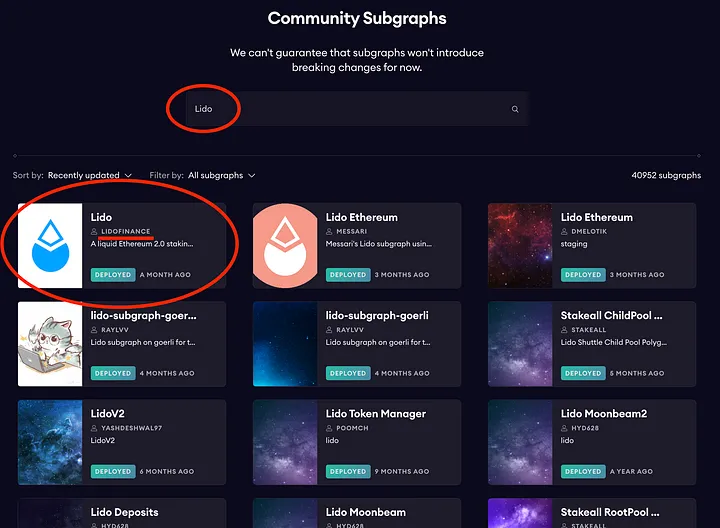
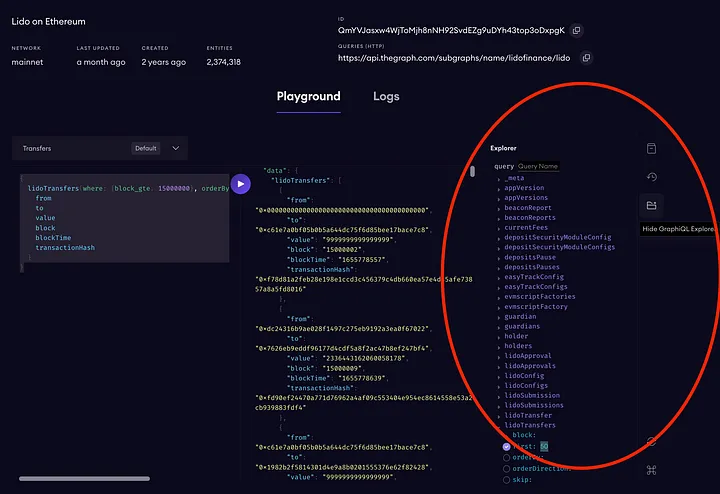
Vamos para a página de detalhes do subgrafo.
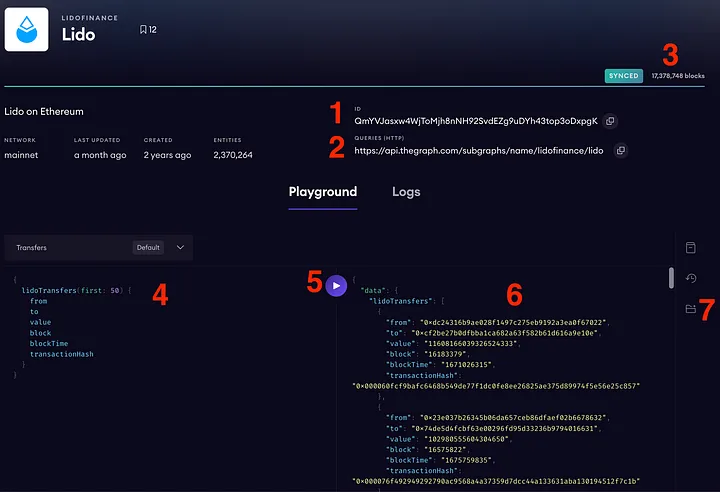
O que você consegue ver aqui?
- O CID (identificador de conteúdo) do IPFS (sistema de arquivo interplanetário) desse subgrafo - é um identificador interno exclusivo desse subgrafo que aponta para o manifesto desse subgrafo no IPFS (protocolo ponto a ponto para localizar um arquivo por meio de um hash - essa é uma explicação extremamente simplificada, mas você pode descobrir como funciona por si mesmo).
- URL de consulta - esse é um endpoint real que usaremos em nosso código Python para acessar os dados do contrato inteligente.
- O indicador do status de sincronização de um subgrafo. Quando o subgrafo está atualizado, você pode consultar os dados, mas deve entender que, ao implantar um novo subgrafo, é necessário aguardar um pouco para sincronizá-lo. Durante esse processo, ele mostrará o número de blocos atuais em processamento.
- A consulta GraphQL. Cada subgrafo tem sua própria estrutura de dados (a lista de tabelas com dados) que precisa ser considerada ao criar uma consulta GraphQL. Em geral, o GraphQL é muito fácil de aprender, mas se você estiver com dificuldades, pode pedir ajuda ao ChatGPT 🙂. Aqui há um exemplo no final do artigo.
- O botão que executa a consulta.
- A janela de saída. Como você pode ver, a resposta do GraphQL é uma estrutura do tipo JSON.
- Uma chave que permite que você veja a estrutura de dados desse subgrafo.
Vamos ao que interessa (vamos revelar nossos notebooks do Jupyter🙂).
Obtendo os dados crus:
import pandas as pd
import requests
def run_query(uri, query):
request = requests.post(uri, json={'query': query}, headers={"Content-Type": "application/json"})
if request.status_code == 200:
return request.json()
else:
raise Exception(f"Unexpected status code returned: {request.status_code}")
url = "https://api.thegraph.com/subgraphs/name/lidofinance/lido"
query = """{
lidoTransfers(first: 50) {
from
to
value
block
blockTime
transactionHash
}
}"""
result = run_query(url, query)
A variável result (de resultado) tem a seguinte aparência:
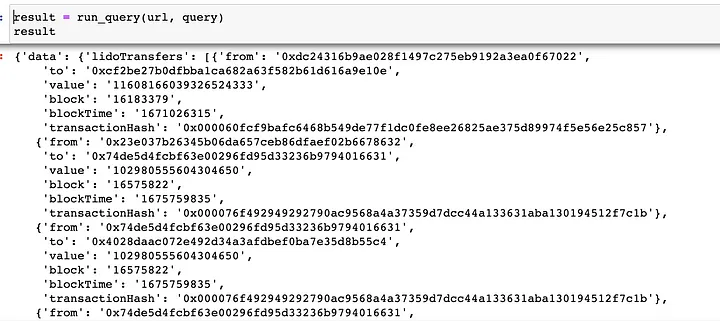
E a última transformação (que só é válida para uma resposta JSON plana) cria um dataframe:
df = pd.DataFrame(result['data']['lidoTransfers'])
df.head()
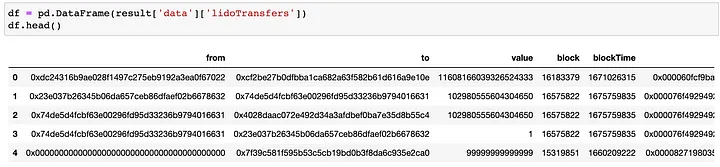
Mas como fazer o download de todos os dados da tabela? Com o GraphQL, há diferentes opções e estou escolhendo a seguinte. Considerando que os blocos são ascendentes, vamos fazer a varredura a partir do primeiro bloco, consultando 1.000 entidades de cada vez (1.000 é o limite para o nó do gráfico).
query = """{
lidoTransfers(orderBy: block, orderDirection: asc, first: 1) {
block
}
}"""
# aqui obtemos o primeiro número de bloco para começar
first_block = int(run_query(url, query)['data']['lidoTransfers'][0]['block'])
current_last_block = 17379510
#modelo de consulta para fazer consultas consecutivas
query_template = """{{
lidoTransfers(where: {{block_gte: {block_x} }}, orderBy: block, orderDirection: asc, first: 1000) {{
from
to
value
block
blockTime
transactionHash
}}
}}"""
result = [] # armazenando a resposta
offset = first_block # começando pelo primeiro bloco encontrado
while True:
query = query_template.format(block_x=offset) # gerar a consulta
sub_result = run_query(url, query)['data']['lidoTransfers'] # obter os dados
if len(sub_result)<=1: # interromper se acabar
break
sh = int(sub_result[-1]['block']) - offset # calcular o deslocamento
offset = int(sub_result[-1]['block']) # calcular o novo deslocamento
result.extend(sub_result) # anexar
print(f"{(offset-first_block)/(current_last_block - first_block)* 100:.1f}%, got {len(sub_result)} lines, block shift {sh}" ) #mostrar o registro
# converter para dataframe
df = pd.DataFrame(result)
Lembre-se de que fazemos consultas sobrepostas porque, a cada vez, usamos o último número de bloco da consulta para iniciar a próxima. Fazemos isso para evitar a falta de registros devido à possibilidade de várias transações por bloco.

Como vemos, cada consulta retorna 1.000 linhas, mas o número do bloco está mudando em várias dezenas de milhares. Isso significa que nem todo bloco contém pelo menos uma transação Lido. Uma etapa importante aqui é eliminar as duplicatas que coletamos, evitando registros perdidos:

Como podemos ver, há mais de 9 mil linhas duplicadas no dataframe.
Agora vamos fazer uma simples EDA (análise exploratória de dados).
col = "from"
df.groupby(col, as_index=False)\
.agg({'transactionHash': 'count'})\
.sort_values('transactionHash', ascending=False)\
.head(5)

Se verificarmos os endereços mais frequentes no campo "from", encontraremos o endereço “0x0000000000000000000000000000000000000000”. Normalmente, isso significa a emissão de novos tokens, portanto, podemos encontrar uma transação no Etherscan e checar:
(df[df['from']=='0x0000000000000000000000000000000000000000'].iloc[1000].to,\
df[df['from']=='0x0000000000000000000000000000000000000000'].iloc[1000].transactionHash,
df[df['from']=='0x0000000000000000000000000000000000000000'].iloc[1000].value,)
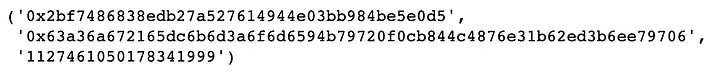
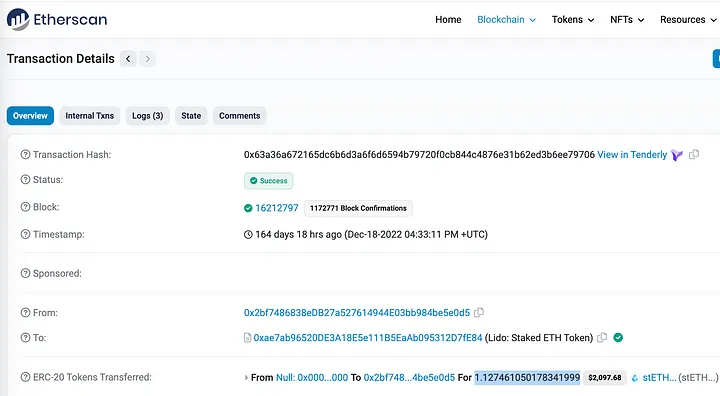
Veremos a transação que tem o mesmo "value":
Além disso, é interessante verificar o destinatário mais frequente de fundos (pelo campo chamado "to"):
col = "to"
df.groupby(col, as_index=False)\
.agg({'transactionHash': 'count'})\
.sort_values('transactionHash', ascending=False)\
.head(5)

O endereço “0x7f39c581f595b53c5cb19bd0b3f8da6c935e2ca0” pode ser encontrado no Etherscan como Lido: Token stETH encapsulado.
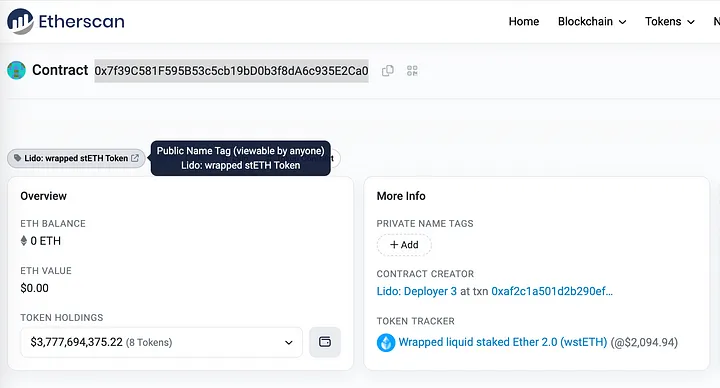
Agora vamos ver o número de transações por mês:
import datetime
import matplotlib.pyplot as plt
df["blockTime_"] = df["blockTime"].apply(lambda x: datetime.datetime.fromtimestamp(int(x)))
df['ym'] = df['blockTime_'].dt.strftime("%Y-%m")
df_time = df.groupby('ym', as_index=False).agg({'transactionHash': 'count'}).sort_values('ym')
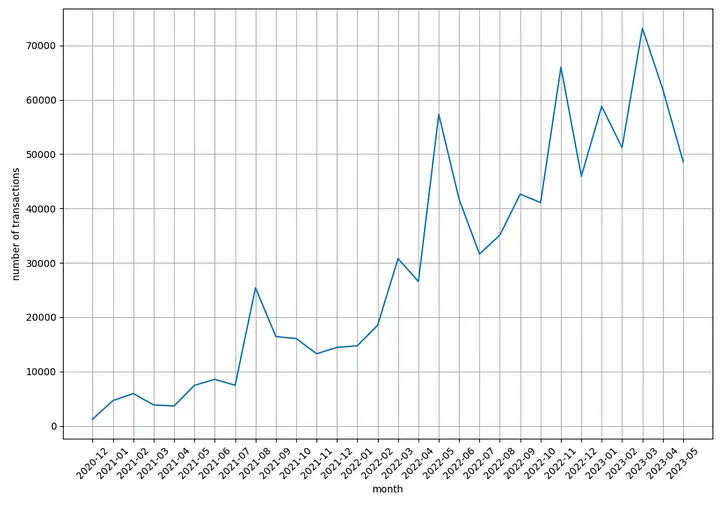
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(df_time['ym'].iloc[:-1], df_time['transactionHash'].iloc[:-1])
plt.xticks(rotation=45)
plt.xlabel('month')
plt.ylabel('number of transactions')
plt.grid()
plt.show()
O número de transações por mês está crescendo constantemente ao longo dos anos!
Você pode continuar sua investigação com os outros campos ou fazer outras consultas a diferentes tabelas no mesmo subgrafo:
O que mais você pode fazer com subgrafos
Primeiramente, se precisar acessar os dados de qualquer outro contrato inteligente que ainda não tenha um subgrafo (ou se os dados não forem suficientes), você poderá escrever facilmente seu próprio subgrafo usando estes tutoriais:
- How to access the Tornado Cash data easily using The Graph’s subgraphs
- How to access transactions of PEPE ($PEPE) coin using The Graph subgraphs and ChatGPT prompts
- Indexing Uniswap data with subgraphs
- A beginner’s guide to getting started with The Graph
Em segundo lugar, se você quiser se tornar um desenvolvedor avançado de subgrafos, considere estes tutoriais aprofundados:
- Explaining Subgraph schemas
- Debugging subgraphs with a local Graph Node
- Fetching subgraph data using javascript
Em terceiro lugar, se você for usar dados em tempo real de subgrafos em seu aplicativo de produção, poderá implantar seu subgrafo no serviço de hospedagem de ** **subgrafos da Chainstack que é muito mais rápido e 99,9% confiável.
Finalmente, se você ainda não se sentir confortável com os subgrafos, não hesite em fazer perguntas no chat do telegram “Compartilhamento de experiências com subgrafos”.
Além disso, se você tiver alguma dúvida sobre o desenvolvimento de contratos inteligentes, participe do chat “Desenvolvimento em Solidity”
Esse artigo foi escrito por Kirill Balakhonov | Chainstack e traduzido por Fátima Lima. O original pode ser lido aqui.