
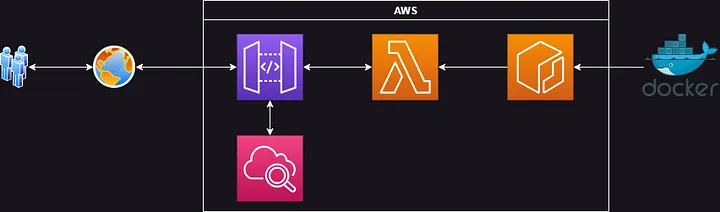
Neste tutorial, você criará um aplicativo com as seguintes etapas:
- Criar e manter um classificador KNN com Python, NumPy e scikit-learn.
- Criar uma função de manipulador do Lambda do AWS que receba um rótulo e executar o modelo para retornar os 30 "vizinhos mais próximos"..
- Empacotar o manipulador lambda e o classificador armazenado como uma imagem do Docker.
- Criar um repositório no AWS Elastic Container Registry (ECR - registro de contêiner elástico do AWS) para manter a imagem.
- Implantar a imagem do ECR em uma função Lambda do AWS.
- Integrar o Lambda com uma API no Portal de API do AWS.
- Testar a API com o Postman e o CloudWatch do AWS.
Você criará uma nova conta do AWS como uma etapa de pré-requisito e nós faremos todas as configurações necessárias. Este aplicativo usa serviços do AWS nas categorias "Always Free" (Sempre gratuito) e "12 Months Free" (12 meses gratuitos). Portanto, certifique-se de remover todos os serviços obsoletos antes desse momento.
Pré-requisitos:
- Conta WS.
- AWS CLI V2 (instale E configure criando uma chave de acesso)
- Docker
- Python
- Postman
Estes comandos listados são para Linux (Ubuntu).
1.Python
mkdir pyai
cd pyai
1.1 Configurar o Venv
O Venv é um módulo Python que permite a criação de ambientes isolados.
pip install virtualenv
Crie um novo ambiente e dê a ele o nome do nosso projeto:
python3 -m venv pyai
Ative o ambiente:
source ./pyai/bin/activate
1.2 Classificador KNN
O classificador será treinado em um conjunto de dados de reconhecimento facial. Em última análise, ele irá expor um método que recebe o nome de uma celebridade como input e retorna uma lista de celebridades com rostos semelhantes de acordo com o aprendizado Nearest Neighbors (vizinhos próximos) e o conjunto de dados.
Isenção de responsabilidade: tento seguir as práticas recomendadas, mas não sou cientista de dados. O modelo Nearest Neighbors foi escolhido pela simplicidade e intuitividade, mas não é necessariamente um modelo ideal para a classificação de imagens.
1.2.0 Instale as dependências
pip install scikit-learn, Pillow
1.2.1 Treinamento do módulo
Esse script será executado localmente para gerar os arquivos necessários para nosso aplicativo Dockerized.
touch train_model.py
Adicione as seguintes importações:
from sklearn.datasets import fetch_lfw_people
from sklearn.neighbors import NearestNeighbors
import numpy as np
from joblib import dump
Defina uma função que conterá o restante do código para esse arquivo:
def train_model():
...
Obtenha o banco de dados codificado de características faciais:
face_data = fetch_lfw_people(min_faces_per_person=5)
Separe o conjunto de características, os rótulos numéricos e os rótulos de texto:
X = face_data.data
labels = face_data.target # numeric labels corresponding to individuals
names = face_data.target_names # names corresponding to numeric labels
O usuário fornece um nome de texto, que deve ser mapeado para um índice numérico para o modelo. O modelo emite índices numéricos que devem ser mapeados para nomes de texto para o usuário. Crie esses mapeamentos para uso posterior:
names_to_labels = {}
labels_to_names = {}
for index, names_idx in enumerate(labels):
name = names[names_idx]
if name in names_to_labels:
names_to_labels[name].append(index)
else:
names_to_labels[name] = [index]
labels_to_names[index] = names[labels[index]]
Ajuste o modelo ao conjunto de características:
nn_model = NearestNeighbors(n_neighbors=15)
nn_model.fit(X, labels)
Salve o modelo, a matriz de características e os objetos de mapeamento para uso posterior:
dump(nn_model, 'nn_model.joblib', compress=3)
np.save('feature_matrix.npy', X)
np.save('names_to_labels.npy', names_to_labels)
np.save('labels_to_names.npy', labels_to_names)
if __name__ == '__main__':
train_model()
1.2.2 Módulo de classificação
Esse é o módulo que o manipulador lambda chamará com o nome da entrada:
touch classifier.py
Adicione as seguintes importações:
from joblib import load
import numpy as np
from collections import Counter
Defina uma função que conterá o restante do código para esse arquivo:
def classify(input_name):
...
Carregue os ativos que criamos ao executar o train_model.py localmente:
nn_model = load('nn_model.joblib')
X = np.load('feature_matrix.npy')
names_to_labels = np.load('names_to_labels.npy', allow_pickle=True).item()
labels_to_names = np.load('labels_to_names.npy', allow_pickle=True).item()
if input_name not in names_to_labels:
print(f"{input_name} not found in dataset.")
return []
Obtenha as amostras da matriz de características correspondentes ao input_name:
name_record_indices = names_to_labels[input_name]
input_samples = X[name_record_indices]
Obter os 15 vizinhos mais próximos para cada uma das amostras de entrada:
distances, indices = nn_model.kneighbors(input_samples, n_neighbors=15)
Achate os resultados e crie tuplas de índice e distância:
index_distance_tuples = [(idx, dist) for dists, idxs in zip(distances, indices) for idx, dist in zip(idxs, dists)]
Obtenha as 15 tuplas mais comuns:
counter = Counter(index_distance_tuples)
most_common_tuples = counter.most_common(15)
Classifique as tuplas por distância e retorne os índices:
sorted_indices_by_distance = [idx for idx, _ in sorted(most_common_tuples, key=lambda x: x[1])]
Obtenha os nomes correspondentes a esses índices::
nearest_neighbors_names = [labels_to_names[idx] for idx, _ in sorted_indices_by_distance]
Retorna o array de nomes:
return nearest_neighbors_names
if __name__ == '__main__':
classify('Angelina Jolie')
Neste ponto, vale a pena executar o train_model.py e o classifier.py localmente com algumas declarações de impressão para verificar a saída.
1.3 Manipulador Lambda
Esta é a função que o Lambda do AWS invocará.
touch lambda_function.py
Adicione o seguinte código:
import json
from classifier import classify
def lambda_handler(event, context):
try:
data = json.loads(event['body'])
label = data['label'] if 'label' in data else ''
results = classify(label)
return json.dumps(results) if results else json.dumps([])
except Exception as e:
return str(e)
Essa assinatura de função é definida pelo Lambda e deve ser respeitada.
Nossa API aceitará solicitações de POST com o rótulo incluído no corpo da solicitação.
Convertemos os resultados em uma string de caracteres JSON válida e a devolvemos ao Portal da API . O Portal de API é capaz de inferir o restante da estrutura de resposta com base em nosso tipo de retorno.
Informações Adicionais:
2.Docker
Agora, empacotamos o aplicativo como uma imagem do Docker.
2.1 Crie um arquivo de requisitos usando o pip:
pip freeze > requirements.txt
2.2 Copie este Dockerfile na raiz do seu projeto:
FROM public.ecr.aws/lambda/python:3.11
COPY requirements.txt ${LAMBDA_TASK_ROOT}
COPY . ${LAMBDA_TASK_ROOT}
RUN pip install --no-cache-dir -r requirements.txt
CMD ["lambda_function.lambda_handler"]
Usamos uma imagem ECR pública projetada especificamente para Python e configurada para Lambda.
Copiamos o arquivo de requisitos para o diretório raiz do Lambda no contêiner do Docker, assim como nossos outros arquivos.
Instalamos as dependências com base no arquivo requirements.txt no contêiner do Docker.
Por fim, definimos o comando padrão a ser executado quando o contêiner do Docker for executado.
2.3 Construa a imagem:
Nota: No Linux, talvez seja necessário, primeiro, adicionar seu usuário atual ao grupo do docker:
sudo usermod -aG docker ${USER}
Informações adicionais: Gerencie o Docker como um usuário não raiz
Crie a imagem:
docker build -t pyai .
2.4 Execute um contêiner a partir da imagem (apenas para teste):
docker run -p 9000:8080 pyai
Informações adicionais:
Implante funções Lambda no Python com imagens de contêineres
3.Registro de Contêiner Elástico AWS (ECR)
O ECR manterá a imagem usada para nosso lambda.
3.1 Crie um Repositório ECR:
Navegue até o console do ECR AWS e clique em Create repository (Criar repositório).
Em Visibility settings (Configurações de visibilidade), mantenha a seleção Private (Privado).
Em Repository name entre com pyai.
Clique Create repository (Criar repositório).
Em sua lista de repositórios privados, você deverá ver pyai.
3.2 Envie a imagem local do Docker para o repositório ECR:
Selecione a caixa de seleção ao lado de pyai.
Clique em **View push commands **(visualizar comandos push).
Copie o comando em Retrieve an authentication token and authenticate your Docker client to your registry (Recupere um token de autenticação e autentique seu cliente Docker no seu registro). Cole-o em sua linha de comando e pressione Enter.
Copie o comando docker tag e execute-o.
Copie o comando docker push e execute-o.
Esse primeiro envio pode levar alguns minutos porque o Docker precisa enviar todas as camadas da imagem. Quando for concluído, você deverá ver o repositório pyai no console ECR.
4.Lambda AWS
Navegue até o console lambda AWS e clique em Create function (Criar função).
Selecione Container image (Imagem do contêiner).
Nome da função: pyai.
URI da imagem do contêiner: Clique em Browse images (imagens do navegador). Selecione o repositório: pyai. Em images, marque latest. Clique em Select image.
Observe, em Permissions: "Por padrão, o Lambda criará uma função de execução com permissões para carregar os registros no Amazon CloudWatch Logs. Você pode personalizar essa função padrão posteriormente ao adicionar gatilhos."
Expanda a função de execução padrão Change. Mantenha a seleção padrão Create a new role (Criar uma nova função) com permissões básicas do Lambda.
O LambdaECRImageRetrievalPolicy deve ser automaticamente criado para o repósitorio ECR pyai. Se não, siga essas instruções: Permissões ECR.
Na página da função pyai, clique em Configuration (Configuração) e depois em General configuration (Configuração geral).
Clique em Edit, e defina o Timeout para 30 seg. Em seguida, defina Memória para 1000 MB. Clique em Save. Provavelmente, você só precisará de cerca de 400 MB de memória; sinta-se à vontade para reduzir a escala posteriormente com base nos registros do CloudWatch para o Lambda.
5.Portal API do AWS
Navegue até o console lambda do AWS e clique em Create API.
Em HTTP API, clique em Build.
Em Integrations, clique em Add integration e selecione Lambda e na função Lambda, clique em pyai function.
Nome da API: pyai.
Clique em Create.
Em Routes ele listará pyai e um link 'ANY'. Clique nele e, em seguida, em Route details (detalhes da rota), clique em Edit. Em vez de ANY, selecione POST. Clique em Save (Salvar).
Se você clicar em Integrations na barra lateral, deverá ver o Lambda AWS ao lado da nossa rota POST.
5.1 CORS
Clique em CORS e Configure.
Access-Control-Allow-Origin: entre http://localhost:3000.
Access-Control-Allow-Methods: selecione POST.
Access-Control-Allow-Headers: entre content-type.
Clique em Save.
5.2 CloudWatch do AWS
Em Monitor clique em Logging, selecione o estágio $default e clique em Select.
Clique em Edit, e alterne para Access logging.
Abra uma nova guia do navegador e navegue até a página do console CloudWatch do AWS.
Clique em Create log group.
Nome do grupo de registros: pyai.
Clique no grupo de registros recém-criado e, em seguida, copie seu ARN.
De volta ao console do Portal API, em Log destination, entre com o ARN.
Em Log format, clique em JSON.
Cole o seguinte JSON. Ele contém algumas das variáveis originais e algumas novas variáveis úteis relacionadas à integração:
{ "requestId":"$context.requestId", "ip": "$context.identity.sourceIp", "requestTime":"$context.requestTime", "httpMethod":"$context.httpMethod","routeKey":"$context.routeKey", "status":"$context.status","protocol":"$context.protocol", "responseLength":"$context.responseLength", "errorMessage": "$context.error.message", "integrationErrorMessage": "$context.integration.error", "integrationStatus": "$context.integration.integrationStatus" }
Clique em Save.
Informações adicionais:
API Gateway & Lambda Integration
API Gateway & Lambda Request/Response Formats
6.Teste com Postman & CloudWatch
6.1 Postman
Do console do portal API do AWS, em Deploy, clique em Stages.
Em Stage details, copie o Invoke URL.
Execute o aplicativo Postman.
Para a nova solicitação, selecione POST.
No espaço URL digite Invoke URL.
No final do URL, adicione /pyai.
Abaixo do URL clique em Body.
Selecione raw.
Digite o seguinte:
{
"label": "Angelina Jolie"
}
Esse deve ser o nome de uma celebridade no banco de dados, ou o programa lançará uma exceção. Certifique-se de usar aspas duplas válidas.
Clique em Send.
Veja os nomes de celebridades retornados que nosso classificador simples acredita serem semelhantes à Angelina Jolie (seu nome deve ser o primeiro).
6.2 CloudWatch
Abra o console CloudWatch do AWS.
Clique em Log groups, depois pyai.
Em Log streams, veja os últimos eventos da API.
Verifique também o grupo de registros criado automaticamente para o Lambda em /aws/lambda/pyai. É aqui que você verá informações de depuração, como instruções de impressão do seu código Python.
Etapas da Reimplantação
Se você fizer alterações no aplicativo, siga estas etapas para reimplantar:
- Reconstrua a imagem do Docker localmente.
- Exclua a imagem antiga (não o repositório) do ECR do AWS para economizar espaço.
- Execute novamente os dois comandos push do ECR que usamos anteriormente.
- No console do Lambda AWS, em Image (Imagem), clique em Deploy new image (Implantar nova imagem) -> Browse Images (Procurar imagens) -> select the ECR repository (selecione o repositório ECR) -> marque a caixa com a tag de Imagem latest (Imagem mais recente) -> Save (Salvar).
- Limpe imagens e contêineres antigos do Docker usando o docker rmi e o docker prune.
Próximos Passos
Algumas direções possíveis para levar esse projeto adiante:
- Adicione CI/CD com CodeBuild & CodePipeline do AWS.
- Adicione seu próprio banco de dados com o RDS do AWS e conecte-se a ele a partir do aplicativo Python.
- Crie um aplicativo de página única que interaja com a API.
Em linguagem simples
Obrigado por fazer parte de nossa comunidade! Antes de ir embora:
- Não deixe de aplaudir e seguir o escritor! 👏
- Você pode encontrar ainda mais conteúdo em PlainEnglish.io 🚀
- Inscreva-se para nossa newsletter semanal gratuita. 🗞️
- Siga-nos no Twitter(X), LinkedIn, YouTube e Discord.
Esse artigo foi escrito por Mike Brinkman e traduzido por Fátima Lima. O original pode ser lido aqui.