
Sumário
- Como Incorporar Armazenamento Descentralizado em Seu Fluxo de Trabalho
- Introdução ao web3.storage
- Instale a Interface de Linha de Comando w3
- Criar um Token de API
- Comandos de Upload e Download
- Zarr e IPFS
- Repositório de Dados Descentralizado
- Abordagem Alternativa
- Considerações Finais
- Usando o IPFS para Hospedagem na Web
- Storj: Outra Opção de Armazenamento Descentralizado
Como Incorporar Armazenamento Descentralizado em Seu Fluxo de Trabalho
Tecnologias emergentes, como o InterPlanetary FileSystem (IPFS), podem contribuir para um ecossistema mais verificável e aberto. Como o IPFS depende de identificadores de conteúdo (CIDs) que são um hash do conteúdo, você pode ter certeza de que os dados retornados estão corretos. Além disso, o IPFS é uma rede aberta e pública. Assim, qualquer pessoa pode acessar o conteúdo da rede se tiver o CID correto.
Um projeto com o qual estou particularmente entusiasmado é o web3.storage, que é um serviço gratuito que reduz o atrito do uso de armazenamento descentralizado.

Neste post, vou…
- Fornecer uma introdução ao web3.storage e como configurá-lo,
- fornecer exemplos de operações CRUD básicas com IPFS em Python,
- descrever minha solução atual para criar um repositório de dados descentralizado.
Introdução ao web3.storage
Nosso objetivo hoje é fornecer uma experiência de fácil utilização que reduza massivamente a carga de integração de novos casos de uso no ecossistema web3 hoje — ao mesmo tempo em que fornecemos um caminho de atualização para o futuro. — Web3.Storage
O Web3.Storage permite que usuários e desenvolvedores usem armazenamento descentralizado fornecido pelo IPFS e pela rede Filecoin. Qualquer coisa carregada é duplicada em provedores de armazenamento distribuídos geograficamente, garantindo a resiliência da rede. O serviço também lida com o trabalho de fixar seu conteúdo em vários servidores.
Esteja atento ao fazer upload, uma vez que qualquer pessoa pode acessar o conteúdo na rede. No entanto, você pode criptografar o conteúdo antes de fazer o upload. Minha regra geral é, apenas faça upload de conteúdo que você se sinta confortável em ser permanentemente público.
A parte permanente é importante. Ao contrário do endereçamento baseado em localização (por exemplo, URLs), o endereçamento baseado em conteúdo (por exemplo, CIDs) dificulta a remoção de dados da rede depois de carregados, pois podem ser fixados em vários servidores.
Sua cota é limitada inicialmente a 1 TiB, mas pode ser aumentada gratuitamente enviando uma solicitação. O custo indireto é atualmente subsidiado pela Protocol Labs, isso provavelmente mudará para alguma forma de modelo de pagamento nativo de criptografia em um futuro próximo (por exemplo, apostando Filecoin para aumentar os limites de armazenamento).
A espinha dorsal que mantém tudo junto é o IPFS, um protocolo de hipermídia projetado para tornar a web mais resiliente ao endereçar os dados por seu conteúdo em vez de sua localização. Para fazer isso, o IPFS usa CIDs em vez de URLs — que apontam para o servidor em que os dados estão hospedados.
Há muito mais no web3.storage e eu encorajo você a explorar os documentos se você também estiver animado com este projeto – especialmente se você for um desenvolvedor.
Configurando o Web3.Storage
Vá para https://web3.storage para criar uma conta
Consulte a documentação para obter instruções detalhadas.
Criar um Token de API
Um API token é necessário para usar o web3.storage na linha de comando.
- Faça login na sua conta web3.storage
- Clique em conta na parte superior e depois em Criar API token
- Insira um nome descritivo para seu token e clique em criar
- Você pode clicar em Copiar para copiar seu novo API token para sua área de transferência.
Não compartilhe seu API token com ninguém, ele é específico da sua conta. Você também deve anotar o campo Token em algum lugar e armazená-lo com segurança.
Instale a interface de linha de comando w3
A interface de linha de comandow3(CLI) é uma ferramenta baseada em node para usar o web3.storage a partir do terminal
Em um Mac, você pode instalar facilmente o node via homebrew, isso também é instalar o gerenciador de pacotes do node (npm).
brew install node
Use npm para instalar a interface de linha de comando w3.
npm install -g @web3-storage/w3
Execute o seguinte comando para conectar o w3 ao web3.storage.
w3 token
Você será solicitado a fornecer o API token criado anteriormente.
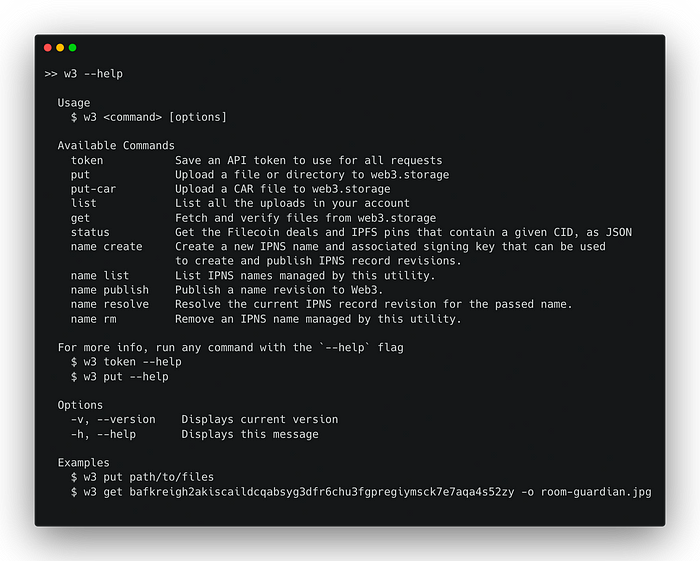
O seguinte exibe informações sobre cada um dos comandos disponíveis.
w3 --help
Comandos de Upload e Download
w3 put /path/to/file(é assim que fazemos upload de conteúdo para web3.storage)w3 get CID(é assim que baixamos conteúdo de um CID específico)
Liste seus arquivos no web3.storage
w3 list
Exemplo Usando o Comando put
Primeiro, crie um arquivo de texto com uma mensagem.
echo "Olá web3.storage" > hello.txt
Vamos agora usar o comando put para enviar o arquivo para o IPFS.
w3 put hello.txt --name hello
hello será o nome que aparece no web3.storage, use w3 list para verificar
O CID e um link de gateway público são emitidos.
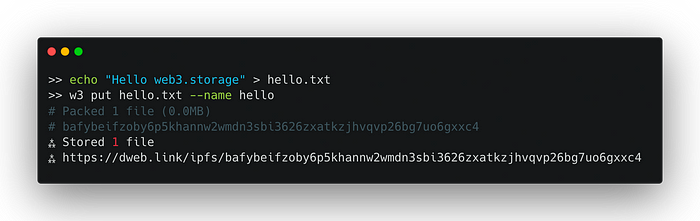
Se você seguiu as etapas acima exatamente, seu CID deve ser idêntico ao meu. O CID é um hash que identifica exclusivamente o conteúdo.
Use o link abaixo para visualizar a mensagem por meio de um gateway público.
[https://dweb.link/ipfs/bafybeifzoby6p5khannw2wmdn3sbi3626zxatkzjhvqvp26bg7uo6gxxc4](https://dweb.link/ipfs/bafybeifzoby6p5khannw2wmdn3sbi3626zxatkzjhvqvp26bg7uo6gxxc4)
Nota: o link será diferente se sua mensagem for diferente
Recuperar Conteúdo com Python
No futuro, esperamos que o web3.storage seja compatível com S3, o que significa que podemos acessar dados armazenados lá de forma semelhante à forma como acessamos dados em buckets S3.
Por enquanto, podemos usar solicitações HTTP para ler os dados em Python. No entanto, bibliotecas como pandas nos permitem ler arquivos CSV diretamente de uma gateway URL. Além disso, ipfsspec nos permite ler armazenamentos de dados zarr do IPFS com xarray.
Demonstrarei a leitura de cada um deles nas seções a seguir
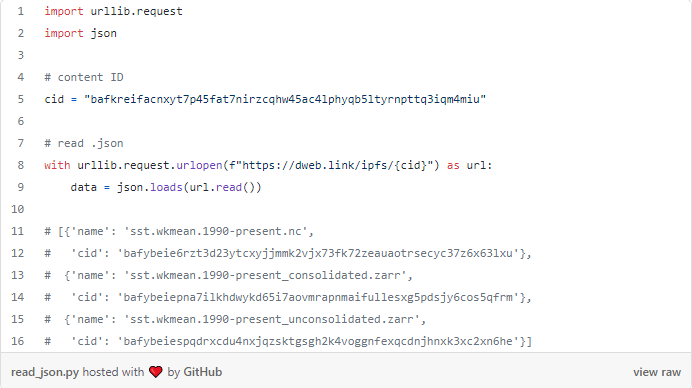
Lendo JSON
Aqui está um exemplo de leitura de um arquivo .json armazenado no IPFS.
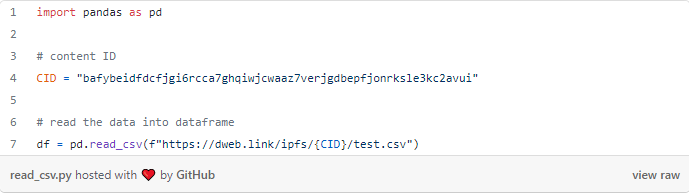
Lendo Arquivos CSV
Se você tiver um arquivo CSV, poderá lê-lo diretamente em um DataFrame do pandas.
Zarr e IPFS
O formato Zarr é um novo formato de armazenamento que torna grandes conjuntos de dados facilmente acessíveis à computação distribuída, tornando-se uma melhoria em relação ao NetCDF comumente usado — um formato para armazenar dados multidimensionais.
Se você está começando a mudar para o formato zarr, eu recomendo que você confira o “Guia para preparar dados otimizados para nuvem” da Pangeo.
Os arquivos NetCDF ainda são muito comuns e as funções do xarray facilitam a conversão desses arquivos NetCDF para armazenamentos de dados zarr.
import xarray as xr
ds = xr.open_dataset('/path/to/file.nc')
ds.to_zarr("./file.nc", consolidated=True)
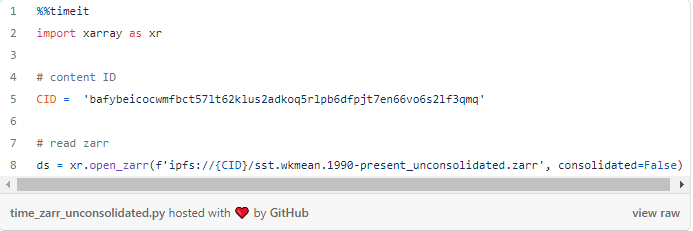
consolidated=True cria um dotfile “oculto” junto com o armazenamento de dados que torna a leitura do zarr mais rápida com xarray. Em um teste simples, descobri que a leitura de armazenamentos de dados consolidados é 5 vezes mais rápida do que a não consolidada.
zarr (consolidated): 635 ms
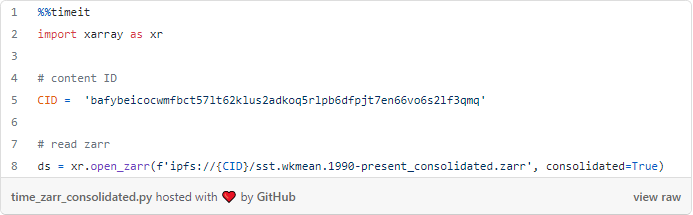
zarr (unconsolidated): 3,19s
Se você quiser testar o código acima, carregue o conjunto de dados NOAA Optimum Interpolation SST V2 no formato zarr consolidado e não consolidado para o IPFS. Este conjunto de dados fornece médias semanais da temperatura da superfície do mar oceânico (SST) de 1990 até o presente com uma resolução espacial de 1 grau.
A gateway URL para esses dados é mostrado abaixo
[https://dweb.link/ipfs/bafybeicocwmfbct57lt62klus2adkoq5rlpb6dfpjt7en66vo6s2lf3qmq](https://dweb.link/ipfs/bafybeicocwmfbct57lt62klus2adkoq5rlpb6dfpjt7en66vo6s2lf3qmq)
Carregar Armazenamentos de Dados Zarr para o IPFS
Ao fazer upload de arquivos zarr para IPFS, você deve certificar-se de fazer upload dos dotfiles “ocultos”. Com w3 isso implica adicionar o sinalizador --hidden:
w3 put ./* --hidden --name filename.zarr
Ler Armazenamentos de Dados Zarr do IPFS
Para ler os armazenamentos de dados zarr do IPFS com xarray, você precisará do pacote ipfsspec (assim como xarray e zarr)
conda install -c conda-forge xarray zarr pip install ipfsspec
O ipfsspec garante que o xarray possa interpretar o protocolo IPFS.
Observe no exemplo abaixo que estou usando o protocolo IPFS em vez da gateway URL com HTTPS. No entanto, nos bastidores, o código está realmente lendo de um gateway.
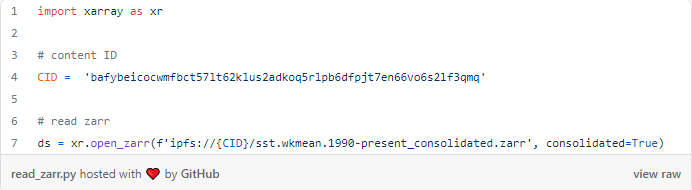
Repositório de Dados Descentralizado
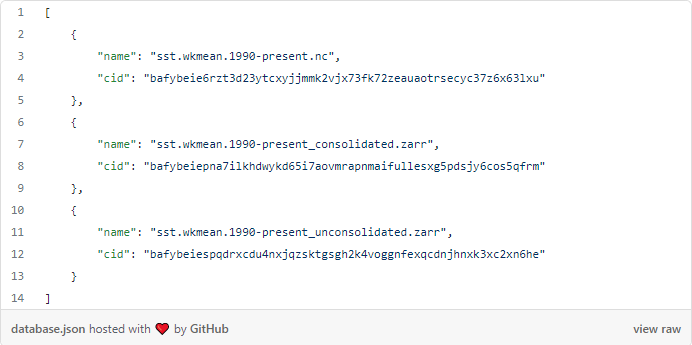
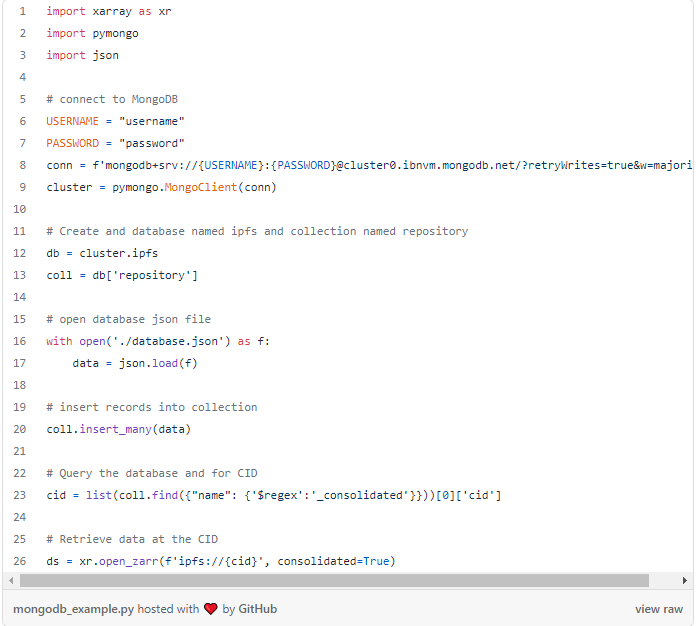
O IPFS pode ser usado como um repositório de dados. No entanto, você precisa vincular o CID a algo que seja legível por humanos para que essa seja uma solução viável. Não tenho conhecimento de nenhuma prática recomendada em torno do gerenciamento de CID. No entanto, seguindo algumas dicas das melhores práticas para dados NFT, minha abordagem atual é armazenar CIDs e seus nomes de arquivos associados como um par chave:valor em JSON e, em seguida, usar um banco de dados NoSQL, como MongoDB, para consultas.
Depois de carregar o conteúdo para web3.storage, você adiciona um novo registro ao arquivo que identifica o que é o conjunto de dados e o CID do conteúdo. Esta é a quantidade mínima de informação necessária.
Aqui está um exemplo de CIDs armazenados como uma matriz JSON.
O pacote pymongo facilita o trabalho com o MongoDB em Python.
Aqui está um exemplo de inserção de registros em uma coleção e, em seguida, consultando o banco de dados para um CID específico.
Abordagem Alternativa
Uma abordagem alternativa que tenho considerado, mas ainda não implementada, é aproveitar a saída da w3 list.
Isso exibe o CID e o nome que você forneceu quando carregou o conteúdo.
A ideia é escrever um awk script para gerar um arquivo JSON a partir da saída.
Algumas desvantagens ou armadilhas para isso incluem:
Manipulação de CIDs que apontam para diretórios em vez de arquivos puros
Ignorando CIDs que são irrelevantes para seu banco de dados
O maior obstáculo que posso ver é lidar com diretórios. Só por esse motivo, estou mantendo a atualização manual do meu banco de dados, especialmente porque ele é pequeno e fácil de gerenciar - pelo menos por enquanto.
Considerações Finais
O IPFS pode ser um local para armazenamento de longo prazo com CIDs funcionando como controle de versão integrado.
A CLI w3 facilita o envio de dados para o IPFS e qualquer formato comum (JSON, CSV, Zarr) pode ser lido do IPFS para o Python.
No entanto, um dos desafios do uso do IPFS é o gerenciamento do CID. Minha solução atual para criar um repositório de dados descentralizado é armazenar CIDs e seus nomes de arquivos associados como pares de valores-chave no MongoDB. A solução é um pouco desajeitada e estou aberto a sugestões sobre como melhorar essa configuração.
Usando o IPFS para Hospedagem na Web
Outra ótima aplicação do IPFS é hospedar um site. Minha página pessoal está hospedada no IPFS. Acho que criei uma solução elegante para gerenciar um site descentralizado, você pode ler sobre minha solução no artigo abaixo.
https://betterprogramming.pub/modern-way-to-host-a-site-on-ipfs-7941b65d27c3
Storj: Outra Opção de Armazenamento Descentralizado
Finalmente, o IPFS não é sua única opção. Se você deseja um armazenamento de objetos compatível com S3, recomendo que você faça o check-out do Storj. A solução Storj depende do armazenamento de fragmentos de dados criptografados em uma rede descentralizada, em vez de duplicar seus dados. Este é um serviço pago, mas muito acessível, especialmente se você estiver usando a AWS. Eu pessoalmente uso o Storj para o meu trabalho diário. Confira o artigo abaixo se você estiver interessado em aprender como eu uso o Storj. https://betterprogramming.pub/storj-decentralized-cloud-storage-my-new-favorite-cloud-object-storage-99d95ddc4e6a
Este artigo foi escrito por (Luke klueger) e traduzido por Jhonattan Farias, você pode encontrar o artigo original aqui.
Abrace a oportunidade de elevar sua jornada de desenvolvimento para um nível superior. Armazenar dados no IPFS é apenas o começo; os builds incríveis da WEB3DEV representam a chave de entrada para o emocionante cenário web3. 🚀🧑💻
Não perca tempo, 👉inscreva-se👈 agora mesmo e comece a desbravar o universo Blockchain! Seja também WEB3DEV!