
Difusores + Abyss Orange Mix 2 + Google Colab
Em uma de minhas vidas passadas, eu costumava me interessar bastante por fotografia de glamour. Todo o processo de conceituação da imagem, direção do modelo e pós-processamento da fotografia era um desafio que eu realmente gostava.
Às vezes, eu até tornava as coisas ainda mais desafiadoras ao fotografar em filme, o que significava que eu só podia ver minhas fotos dias após a filmagem e não conseguia facilmente refazer nenhuma foto ruim. Caramba, eu até tinha planos de usar daguerreótipos para tornar as coisas ainda mais desafiadoras!
A vida, no entanto, decidiu me levar por um caminho diferente (em parte graças à descontinuação de vários filmes da Fujifilm), embora eu nunca tenha esquecido completamente a fotografia de glamour.
 ######Ilustração sintética criada usando Abyss Orange Mix 2 e Difusores. Imagem criada pelo autor.
######Ilustração sintética criada usando Abyss Orange Mix 2 e Difusores. Imagem criada pelo autor.
Apesar de não ter me envolvido seriamente com a fotografia há alguns anos, eu também entrei na onda com o resto do mundo quando modelos de IA (inteligência artificial) generativa de imagens, como a DALL-E, Midjourney ou Stable Diffusion foram lançados. Imediatamente comecei a brincar com eles para entender melhor o que podem fazer e, se quisesse, poderia usá-los como parte do meu fluxo de trabalho de pós-processamento (ainda tenho um grande acúmulo de trabalho de pós-processamento).
Fiquei extremamente surpreso e satisfeito com os recursos desses modelos de IA generativa de imagens e também muito grato por a vida ter decidido me direcionar para o aprendizado profundo! Neste artigo, compartilho minhas experiências e demonstro como usar modelos de difusão de última geração pré-treinados para criar imagens sintéticas (tipo fotografia de glamour)!
Stable Diffusion - IA generativa para pobres, avarentos e pão-duros
Muitos modelos de IA generativas de última geração não são de código aberto ou de uso gratuito. Felizmente, porém, existem várias opções de código aberto gratuitas para uso. Para a geração de imagens existe o Stable Diffusion (Difusão Estável) que pode ser executado em uma estação de trabalho típica equipada com uma GPU com 8 GB de RAM.
Para pobres, avarentos ou pão-duros que se recusam a desembolsar dinheiro mesmo para uma estação de trabalho típica, o Google Colab é uma ótima plataforma alternativa. Confira meu outro artigo sobre como executar modelos na GPU (Unidade de Processamento Gráfico) do Colab!
Nesta seção, apresentamos os principais detalhes do Stable Diffusion resumidos do artigo original, que recomendo você ler se tiver tempo.
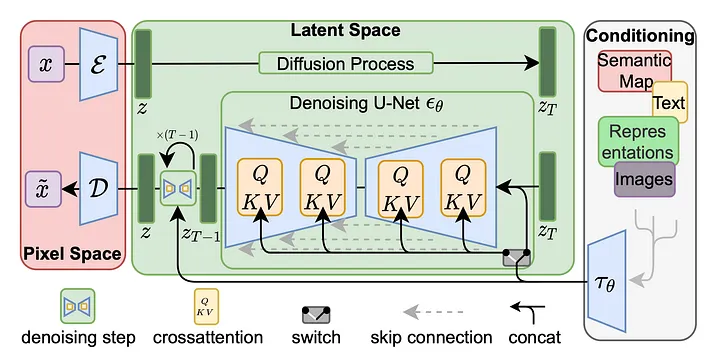 ######Diagrama mostrando como ocorre o treinamento do modelo da Stable Diffusion. Imagem retirada de https://arxiv.org/pdf/2112.10752.pdf.
######Diagrama mostrando como ocorre o treinamento do modelo da Stable Diffusion. Imagem retirada de https://arxiv.org/pdf/2112.10752.pdf.
Alucinando Imagens por meio de redução de ruídos
O Stable Diffusion não cria imagens do nada (isso é IA, não mágica!). Em vez disso, o Stable Diffusion cria imagens através de um processo iterativo de redução de ruído em uma imagem com ruído (processo inferior no diagrama acima) usando U-nets.
A partir de ruído puro, o Stable Diffusion alucina detalhes aqui e ali em cada iteração durante o processo de redução de ruído e, em iterações suficientes, uma imagem inteira é alucinada de ruído puro!
Durante o treinamento, um processo reverso está envolvido — as imagens são difundidas até se tornarem ruído puro (processo superior no diagrama). É daí que vem a “difusão” no Stable Diffusion. O processo de redução de ruído pode ser pensado como a reversão do processo de difusão de uma imagem para ruído!
Além da imagem latente de ruído puro inicial, um prompt de entrada que consiste em texto tokenizado e codificado é usado para orientar o processo de redução de ruído - precisamos dizer ao modelo o que desenhar!
Espaço Latente
O Stable Diffusion trabalha no espaço latente em vez do espaço de pixels — é isso que permite que o Stable Diffusion funcione em uma estação de trabalho típica. O espaço de pixels é extremamente grande e requer recursos de computação poderosos para processar.
Por outro lado, o espaço latente é essencialmente um espaço comprimido perceptivamente equivalente ao espaço de pixels original. O espaço latente é menor do que o espaço de pixels, mas ainda contém detalhes perceptivos importantes.
No entanto, isso também significa que as saídas do Stable Diffusion devem ser decodificadas do espaço latente para o espaço do pixels. Isso pode ser executado usando um codificador automático, por exemplo (lembre-se de que um codificador automático é usado para aprender representações eficientes e de baixa dimensão de algum espaço dimensional alto).
Resumo do processo de redução de ruído
O texto de um prompt é tokenizado e codificado numericamente. Uma imagem aleatória de ruído puro é inicializada no espaço latente. Esta imagem latente ruidosa tem seu ruído reduzido iterativamente usando o U-nets enquanto é guiada pelo prompt. Após um determinado número de iterações, a imagem latente sem ruído é convertida para um espaço de pixels.
Bibliotecas do Python
Embora existam muitas IUs (interfaces do usuário) disponíveis para uso, como a automatic1111 ou a Swift Diffusers para Macs, vamos nos concentrar nas bibliotecas do Python neste artigo.
O Stable Diffusion está disponível através de várias bibliotecas do Python, como a KerasCV ou a Diffusers — para o artigo, usaremos o Diffusers e os modelos pré-treinados disponíveis no HuggingFace.
Diffusers
O Diffusers é uma segmentação de instruções (pipeline) de difusão, que fornece acesso a vários modelos de difusão no HuggingFace. Embora possa ter sua utilização “pronta para uso”, o Diffusers também permite que os usuários personalizem cada um dos sete componentes da segmentação de instruções de difusão:
- Feature Extractor (Extrator de Recursos) — extrai recursos de imagens geradas para serem usadas como entradas para o verificador de segurança.
- Safety Checker (Verificador de Segurança) — modelo de classificação que examina as saídas em busca de conteúdo potencialmente nocivo. Fará com que o modelo gere uma imagem preta se for detectado conteúdo de saída prejudicial.
- Scheduler (Agendador) — essencialmente técnicas de integração Equações Diferenciais Ordinárias (EDO). Define como as saídas da U-net da iteração anterior são atualizadas na próxima iteração.
- Text Encoder (Codificador de Texto) — codifica texto do prompt para recursos numéricos.
- Tokenizer (Tokenizador) — tokeniza o texto do prompt. Isso, junto com o codificador de texto, é usado para guiar o processo de redução de ruído, conforme descrito na seção acima.
- U-net —reduz ruído de imagens ruidosas iterativamente no espaço latente. Esta é a parte principal do Stable Diffusion descrita na seção acima.
- Variational Auto-Encoder (VAE, Codificador Automático Variacional) — gera a imagem de saída final decodificando as imagens do espaço latente para o espaço do pixels.
A maioria dos modelos de difusão no HuggingFace fornece todos os componentes necessários para executar toda a segmentação de instruções de difusão, embora seja possível substituir os componentes padrão e até mesmo misturar e combinar componentes compatíveis de diferentes modelos. No entanto, os resultados podem variar.
Abyss Orange Mix 2 — Ilustrações altamente realistas de alta qualidade
Agora que descrevemos como o Stable Diffusion funciona, bem como os principais componentes da biblioteca Diffusers, é hora de passar para os modelos. Conforme descrito anteriormente, as U-nets são usadas para criar imagens sintéticas removendo o ruído de imagens ruidosas. Dependendo de como as U-nets são treinadas e condicionadas, os resultados finais serão muito diferentes.
Há uma grande variedade de modelos para escolher. Por exemplo, a versão básica lançada pela Stability AI é capaz de gerar uma ampla variedade de imagens, como astronautas andando a cavalo. No restante deste artigo, usaremos o Abyss Orange Mix 2 (AOM2) — um dos modelos Orange Mix fornecidos sob a licença CreativeML OpenRAIL-M, projetado para gerar ilustrações de alta qualidade e altamente realistas (não fotografias).
Usamos o AOM2 em vez de um modelo fotorrealista, em parte porque originalmente pretendíamos reimaginar a fotografia de glamour em vez de recriar ou replicar a fotografia de glamour!
AOM2 pré-treinado no HuggingFace
Os pesos pré-treinados para o AOM2 podem ser baixados diretamente do HuggingFace — o conteúdo baixado dos sete componentes deve ser colocado em um diretório local com a seguinte estrutura. Observe que, além dos sete componentes acima, há também um arquivo model_index.json contendo informações gerais sobre o modelo.
abyss_orange_mix_2
├── feature_extractor
│ └── preprocessor_config.json
├── model_index.json
├── safety_checker
│ ├── config.json
│ └── pytorch_model.bin
├── scheduler
│ └── scheduler_config.json
├── text_encoder
│ ├── config.json
│ └── pytorch_model.bin
├── tokenizer
│ ├── merges.txt
│ ├── special_tokens_map.json
│ ├── tokenizer_config.json
│ └── vocab.json
├── unet
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── vae
├── config.json
└── diffusion_pytorch_model.bin
Carregando os componentes AOM2 baixados
Os componentes AOM2 baixados podem ser carregados diretamente usando a segmentação de instruções do Diffusers por meio da função do Python abaixo. A função carrega o modelo pré-treinado e permite que o usuário substitua o agendador e o verificador de segurança, se desejar.
Conforme mencionado anteriormente, os agendadores definem como as saídas da iteração anterior são atualizadas. Portanto, agendadores diferentes resultarão em saídas diferentes para o mesmo modelo e prompts. Demonstraremos esse efeito muito em breve.
# Carrega (texto para imagem) a segmentação de instruções do diffuser baixado do HuggingFace.
# Atualmente, suporta apenas a troca de agendadores e o verificador de segurança.
def load_pipeline(model_dir,
scheduler = None,
safety_checker = False,
device_name = torch.device("cpu"),
torch_dtype = torch.float32):
"""
Loads a pre-trained diffusion pipeline downloaded from HuggingFace.
Arguments
model_dir: str
Path to the downloaded model directory.
scheduler: str or None
Scheduler to use. Currently only "EDS", "EADS" or "DPMSMS"
are supported. If None, default scheduler will be used.
safety_checker: bool
Turn on/off model safety checker.
device_name: torch.device
Device name to run the model on. Run on GPUs!
torch_dtype: torch.float32 or torch.float16
Dtype to run the model on. Choice of 32 bit or 16 bit floats.
16 bit floats are less computationally intensive.
Returns
pipe: StableDiffusionPipeline
Loaded diffuser pipeline.
"""
# Carrega a segmentação de instruções de difusão pré-treinada.
pipe = diffusers.StableDiffusionPipeline.from_pretrained(
model_dir,
torch_dtype = torch_dtype
)
# Altera o agendador para EDS, EADS ou DPMSMS.
# TODO
# Adiciona mais opções para o agendador.
if scheduler in [
"EulerAncestralDiscreteScheduler",
"EADS"
]:
pipe.scheduler = diffusers.EulerAncestralDiscreteScheduler.from_config(
pipe.scheduler.config
)
elif scheduler in ["EulerDiscreteScheduler", "EDS"]:
pipe.scheduler = diffusers.EulerDiscreteScheduler.from_config(
pipe.scheduler.config
)
elif scheduler in ["DPMSolverMultistepScheduler", "DPMSMS"]:
pipe.scheduler = diffusers.DPMSolverMultistepScheduler.from_config(
pipe.scheduler.config
)
# Caso contrário, o agendador padrão será usado.
# Altera o verificador de segurança, se desejar.
if safety_checker is False:
pipe.safety_checker = lambda images, **kwargs: [
images, [False] * len(images)
]
# Carrega a segmentação de instruções na GPU, caso disponível.
pipe = pipe.to(device_name)
return pipe
Executando a segmentação de instruções carregada
A segmentação de instruções de difusão carregada pode ser executada usando a função do Python abaixo. Além da segmentação de instruções de difusão carregada, prompt e prompt negativo, há mais alguns pontos importantes a serem observados.
- Primeiro, precisamos especificar o número de etapas de redução de ruído a serem executadas - 50 é um bom ponto de partida e você definitivamente vai querer brincar com esse valor.
- O Abyss Orange Mix 2 também requer que as dimensões da imagem de saída sejam múltiplas de 8. Isso se deve à arquitetura interna do modelo. Eu gosto de usar um valor maior, como 12.
- A escala controla o quanto o modelo segue os prompts. Uma escala maior significa que o modelo seguirá os prompts o mais próximo possível, às custas da qualidade da imagem.
- Por fim, precisamos de uma semente (seed) para inicializar a imagem com ruído.
# Executa a segmentação de instruções do difusor.
def run_pipe(pipe,
prompt,
negative_prompt = None,
steps = 50,
width = 512, # Multiple of 8
height = 704, # Multiple of 8.
scale = 12,
seed = 123456789,
n_images = 1,
device_name = torch.device("cpu")):
"""
Arguments
pipe: StableDiffusionPipeline
Stable diffusion pipeline from load_pipeline.
prompt: str
Prompt used to guide the denoising process.
negative_prompt: str or None
Negative prompt used to guide the denoising process.
Used to restrict the possibilities of the output image.
steps: int
Number of denoising iterations.
width, height: int
Dimensions of the output image. Must be a multiple of 8.
scale: float
Scale which controls how much the model follows the prompt.
Higher values lead to more imaginative outputs.
seed: int
Random seed used to initialize the noisy image.
n_images: int
How many images to produce.
device_name: torch.device
Device name to run the model on. Run on GPUs!
Returns
image_list: list
List of output images.
"""
if width % 8 != 0:
print("Image width must be multiples of 8... adjusting!")
width = int(width / 8) * 8
if height % 8 != 0:
print("Image width must be multiples of 8... adjusting!")
height = int(height / 8) * 8
# O uso de um torch.Generator permite um comportamento determinístico.
gen = torch.Generator(device = device_name).manual_seed(seed)
image_list = []
with torch.autocast("cuda"):
for i in range(n_images):
image = pipe(prompt,
height = height,
width = width,
num_inference_steps = steps,
guidance_scale = scale,
negative_prompt = negative_prompt,
generator = gen)
image_list = image_list + image.images
return image_list
A função acima permite a seleção de 3 agendadores diferentes. Se um agendador não for especificado, o PNDMScheduler padrão será usado. O uso de agendadores diferentes tenderá a alterar a imagem de saída final.
- PNDMS Scheduler — Métodos pseudo-numéricos para modelos de difusão. Usa Runge-Kutta e métodos lineares de várias etapas.
- Euler Discrete Scheduler — Etapas do método de Euler baseadas na implementação original do k-diffusion por Katherine Crowson.
- Euler Ancestral Discrete Scheduler — Etapas do método de Euler com amostragem ancestral com base na implementação original do k-diffusion por Katherine Crowson.
- DPM Solver Multistep Scheduler — Solucionador rápido e dedicado de alta ordem para difusão de EDOs com garantia de ordem de convergência.
Engenharia de Prompt
Os prompts são necessários para dizer ao Stable Diffusion que tipo de imagem criar - o Stable Diffusion não pode ler sua mente!
Na forma mais simples, os prompts são inseridos no Abyss Orange Mix 2 como uma série de palavras descritivas separadas por vírgulas. Um exemplo de prompt para a imagem de uma mulher usando um vestido preto elegante em pé em um salão de baile poderia ser:
prompt = """mulher, vestido preto elegante, em pé, salão de baile"""
Colocar as descrições entre parênteses força o Stable Diffusion a prestar mais atenção a esses detalhes. Aumentar o número de parênteses aumenta a quantidade de atenção que o Stable Diffusion presta a esses detalhes. Por exemplo, para enfatizar o salão de baile e dar mais ênfase no vestido elegante preto:
prompt = """mulher,((vestido preto elegante)),de pé,(salão de baile)"""
Além dos prompts, a segmentação de instruções também permite o uso de prompts negativos. Os prompts negativos são talvez ainda mais importantes que os prompts - eles dizem ao Stable Diffusion o que NÃO desenhar.
Por exemplo, a documentação do Orange Mix sugere o uso de prompts negativos simples para negar imagens gerais de baixa qualidade, como:
negative_prompt = """(pior qualidade, baixa qualidade:1.4)"""
A engenharia de prompts é uma arte em si, e as possibilidades de prompts e prompts negativos são infinitas. Felizmente, comunidades online como o Reddit fornecem um lugar para todos compartilharem seus resultados e trocarem ideias. Existem também outros recursos, como a stable-diffusion-art ou esta postagem do Medium por Umberto Grando.
Executando a segmentação de instruções da AOM2
Em primeiro lugar, carregue os arquivos do modelo baixados do HuggingFace. Especificamos o diretório dos arquivos de modelo baixados e, por enquanto, não especificamos um agendador a ser usado. Por enquanto, não ativamos o verificador de segurança e indicamos que gostaríamos de executar o modelo na GPU usando a precisão float32.
# Carrega a segmentação de instruções a partir dos arquivos baixados.
# Observe que ao definir o agendador como "EDS", "EADS" ou "DPMSMS"
# podemos usar diferentes agendadores.
pipe = load_pipeline(model_dir = "abyss_orange_mix2",
scheduler = None,
safety_checker = False,
device_name = torch.device("cuda"),
torch_dtype = torch.float32)
Não revelaremos os prompts reais usados neste artigo - a busca por prompts que resultam em imagens que você realmente gosta faz parte da experiência!
Depois de criar alguns prompts, a segmentação de instruções carregada pode ser executada para gerar uma lista de imagens sintéticas. As imagens são geradas como objetos PIL.Image e podem ser facilmente salvas ou exibidas.
# Valor inicial da semente aleatória.
i = 0
# 10 sementes = 10 imagens diferentes.
seeds = [i for i in range(i, i + 10, 1)]
images = []
for seed in seeds:
images += run_pipe(
pipe,
prompt,
negative_prompt,
steps = 50,
width = 512, # 512 = 64 * 8
height = 768, # 768 = 96 * 8
scale = 12,
seed = seed,
n_images = 1,
device_name = device_name
)
Observe que as dimensões de saída têm uma proporção de tela de 1,5, que é a proporção de tela do filme de câmera de 35 mm! Outras proporções de tela de filme comumente usadas são 6 × 6 e 6 × 7 (filme de 120) ou 4 × 5 (filme de grande formato).
Além disso, observe que o tamanho da sua imagem de saída depende da sua GPU. GPUs com menor capacidade não conseguirão lidar com imagens grandes.
Efeitos de diferentes agendadores
Como mencionado anteriormente, os agendadores definem como as saídas da U-net da iteração anterior são atualizadas. Nas imagens de saída de exemplo abaixo, em geral, a imagem geral não muda, embora pequenos detalhes dentro da imagem mudem.
O padrão PNDMS scheduler não desenhou o rosto muito bem e desenhou vincos no vestido. Por outro lado, os agendadores EDS e DPMSM produziram desenhos faciais muito melhores e suavizaram os vincos do vestido. Além disso, o agendador do DPMSM renderizou a árvore à direita como uma lâmpada de rua.
 ######Efeitos do uso de diferentes agendadores. Imagem criada pelo autor.
######Efeitos do uso de diferentes agendadores. Imagem criada pelo autor.
Para outras imagens, usar agendadores diferentes pode produzir imagens completamente diferentes. Por exemplo, embora não tenha sido exibido acima, o agendador EADS produziu uma imagem completamente diferente — o vestido era completamente preto e com um design diferente.
O problema com as mãos
Apesar das capacidades dos modelos de IA generativa, eles têm muita dificuldade em renderizar as mãos corretamente. A grande maioria das imagens geradas continham mãos mal desenhadas, como muitos dedos, poucos dedos, mãos mutiladas, mãos anatomicamente impossíveis, etc. Uma possível razão para esse fenômeno é que mesmo para humanos, mãos realistas são difíceis de desenhar!
 ######Mãos mal desenhadas são a norma! Imagem criada pelo autor.
######Mãos mal desenhadas são a norma! Imagem criada pelo autor.
Em muitos casos em que a imagem pode ser corrigida, um software de edição de imagem, como o GIMP, pode ser usado para corrigir erros. Na verdade, muito raramente obtenho uma imagem utilizável diretamente do Stable Diffusion - o resultado final geralmente envolve alguma quantidade de pós-processamento e edição.
Perspectivas
O que demonstramos neste artigo é extremamente superficial, e as possibilidades para o Stable Diffusion são infinitas. Por exemplo, representações podem ser usadas em conjunto com prompts para maior controle sobre como as imagens sintéticas são geradas.
As imagens de saída são geralmente imagens de baixa resoluç��o (<1000 pixels), principalmente devido às limitações de memória das GPUs. No entanto, isso pode ser superado usando os Real-ESRGANs para redimensionar a imagem para uma resolução muito maior. Da mesma forma que o Stable Diffusion, os Real-ESRGANs alucinam detalhes a partir de uma imagem pequena para criar uma imagem maior. Isso é IA, não mágica!
As imagens de saída também podem ser pós-processadas usando técnicas de inpainting (pintura interna). Isso pode ajudar a corrigir erros, como mãos mal desenhadas, ou a adicionar mais detalhes ou elementos à imagem.
Além disso, neste artigo, demonstramos o que é conhecido como geração de texto para imagem. Existem outras segmentação de instruções também, como geração de imagem para imagem. As segmentações de instruções de imagem para imagem permitem que você use uma imagem de entrada para usar como condições iniciais. Esta é a segmentação de instruções principal que eu uso para o meu backlog de pós-processamento de fotografia de glamour!
Mais uma vez, não posso enfatizar o quão verdadeiramente inspiradora é a comunidade do Reddit. Esta comunidade é um ótimo lugar para aprender com os sucessos dos outros e, mais importante, aprender com seus fracassos! Obrigado por ler!
Referências
[1] High-Resolution Image Synthesis with Latent Diffusion Models
[2] Learning Transferable Visual Models From Natural Language Supervision
[3] https://huggingface.co/docs/diffusers/index
[4]https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/img2img
[5] https://keras.io/guides/keras_cv/generate_images_with_stable_diffusion/
[6] https://getimg.ai/guides/interactive-guide-to-stable-diffusion-guidance-scale-parameter
[7] Pseudo Numerical Methods for Diffusion Models on Manifolds
[8] Elucidating the Design Space of Diffusion-Based Generative Models
[9] DPM-Solver: A Fast ODE Solver for Diffusion Probabilistic Model Sampling in Around 10 Steps
[10] DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models
[11] https://www.reddit.com/r/sdforall/comments/10woqgs/stable_diffusion_prompt_a_definitive_guide/
BECOME a WRITER at MLearning.ai // invisible ML // Detect AI img
https://medium.com/mlearning-ai/mlearning-ai-submission-suggestions-b51e2b130bfb
Artigo escrito por Y. Natsume. Traduzido por Marcelo Panegali.