
Bom dia, família! Sejam bem-vindos ao meu primeiro post no Medium.
Ontem à noite, vi o seguinte tweet do usuário z0age e percebi que não sei o suficiente sobre como a codificação de ABI funciona, então aqui está minha interpretação pessoal depois de ler a documentação do Solidity.

Questionamento do usuário z0age
Como você provavelmente já sabe, no Solidity, a ABI é usada para codificar chamadas de função e estruturas de dados para comunicação ao interagir com contratos inteligentes. A ABI especifica como os argumentos de função, erro e evento são codificados e decodificados.
Ao chamar uma função de contrato inteligente, é preciso especificar duas coisas importantes:
- A função que estamos chamando, que é especificada pelo seletor de função;
- Os argumentos que escolhemos passar com essa chamada.
Neste artigo, vamos dar uma olhada rápida no primeiro item para nos concentrarmos no segundo.
Seletor de Função
Os primeiros quatro bytes de calldata (dados de chamada) para uma chamada de função especificam a função a ser chamada: esses são os primeiros 4 bytes do keccak256 da assinatura de tal função.
A assinatura é definida como a string contendo o nome da função, seguida pela lista de tipos de parâmetros entre parênteses, separados por vírgulas. Por exemplo:
-
"transferFrom (address, address, uint256)"é a assinatura do notório método ERC20. -
"addressProcessBundle ((uint256 [2], address [], (uint256, (uint256, address, bytes) []) []))"é um exemplo de uma assinatura que usa uma estrutura composta de um array de tamanho fixo, um array de tamanho dinâmico e um array de tamanho dinâmico de uma estrutura contendo um número e um array de tamanho dinâmico de outra estrutura contendo um número, um endereço e um array de bytes.
Ao fazer o hash dessas strings e pegar os primeiros 4 bytes da esquerda, obtemos seu seletor.

Usar a assinatura == boa ferramenta
Codificação de Argumentos
A partir do quinto byte de calldata, seguem os argumentos codificados.
Uma distinção importante é feita entre tipos estáticos e dinâmicos: os tipos estáticos são codificados no local, enquanto os tipos dinâmicos são codificados em uma posição adicional em relação ao atual "bloco" de argumentos.
Os tipos dinâmicos são: bytes, string, T[], T[k] para qualquer T e k >= 0 dinâmicos e (T1, .., Tk) se for para algum 1 <= i <= k, Ti é dinâmico.
Todos os outros tipos são estáticos!
Antes de entrar na especificação formal da codificação, definimos:
-
len(a)como o número de bytes em uma string bináriaa; -
enc, a codificação real, como um mapeamento de valores ABI para uma string binária, de forma quelen(enc(a))depende do valor dease e somente seafor dinâmico.
Observe que, pela definição de enc, temos que, se a for de um tipo estático, sua codificação não depende de seu valor (e vice-versa)!
Especificação Formal da Codificação
Respire fundo, pois vamos nos aprofundar.
Para qualquer valor X da ABI, enc(X) é definido recursivamente, baseado em seu tipo.
Para estruturas (T1, ..., Tk) onde k >= 0 e quaisquer tipos T1, ..., Tk:
- A codificação é composta por
kelementos "head" (cabeça) ekelementos "tail" (cauda), comoenc(X) = head(X(1)) .. head(X(k)) tail(X(1)) .. tail(X(k)), ondeX = (X(1), ..., X(k))eheadetailsão definidos paraTicomo:- Para
Tiestático:head(X(i)) = enc(X(i))etail(X(i)) = ""(tipos estáticos são codificados no local, lembra-se?); - Para
Tidinâmico:head(X(i)) = enc(len(head(X(1)) .. head(X(k)) tail(X(1)) .. tail(X(i-1))))etail(X(i)) = enc(X(i))(o que é uma maneira complicada de dizer que, onde você encontraria a codificação deXse fosse estática, você encontrará um deslocamento a partir da base da estrutura, onde encontrará a codificação real.). Voltaremos a isso com um exemplo no final.
- Para
- Para arrays de tamanho fixo
T[k]para qualquerTek:enc(X) = enc((X[0], ..., X[k-1]))ou seja, é codificado como uma tupla comkelementos do mesmo tipo. - Para arrays de tamanho dinâmico
T[]de tamanhok:enc(X) = enc(k) enc((X[0], ..., X[k-1]))ou seja, é codificado como uma tupla comkelementos do mesmo tipo, prefixados com o número de elementos! -
bytesde comprimentok:enc(X) = enc(k) pad_right(X)ou seja, é codificado como o número de bytes seguido pela sequência real de bytes, preenchida à direita para que seu comprimento seja um múltiplo de 32. -
string:enc(X) = enc(enc_utf8(X))ou seja,Xé UTF-8 e é interpretado comobytes. -
uint<M>:enc(X)é a codificação big-endian deX, preenchido à esquerda para quelen(enc(X)) == 32. -
int<M>:enc(X)é a segunda codificação complementar big-endian deX, preenchido à esquerda com0xffseXfor negativo e com bytes zero seXnão for negativo, de modo quelen(enc(X)) == 32. -
bool: codificado comouint8, onde1é usado paratruee0parafalse. -
bytes<M>:enc(X)é a sequência de bytes preenchida com zeros à direita para quelen(enc(X)) == 32.
Eu poderia mostrar também a codificação de tipos como fixed e ufixed, mas não o farei, pois eles ainda não têm suporte total no Solidity v0.8.19.
Um exemplo prático
Agora, gostaria de guiá-lo através de um exemplo de como você poderia ler o calldata bruto e decodificá-lo manualmente (se você estiver disposto a um desafio, tente codificá-lo manualmente).
Vamos pegar o calldata de uma chamada ao Vault da Balancer, em particular o de uma chamada à sua função de swap, já que ela leva 2 structs e 2 uint256 como argumentos.
Aqui você pode encontrar a transação que vamos dissecar.
Primeiro, vamos pegar o calldata mostrado pelo Etherscan (que faz um ótimo trabalho ao nos fornecer o calldata dividido em slots de 32 bytes):
Function: swap((bytes32,uint8,address,address,uint256,bytes), (address,bool,address,bool), uint256, uint256)
MethodID: 0x52bbbe29 Offset from start of argument encoding block
00000000000000000000000000000000000000000000000000000000000000e0 0x0000
0000000000000000000000008d7e58c0ebf988dbb31a993696286106964dd4f4 0x0020
0000000000000000000000000000000000000000000000000000000000000000 0x0040
0000000000000000000000008d7e58c0ebf988dbb31a993696286106964dd4f4 0x0060
0000000000000000000000000000000000000000000000000000000000000000 0x0080
0000000000000000000000000000000000000000000b3a7f984c82f6ffa3d428 0x00a0
ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff 0x00c0
929a9b6d40e4723f690db77a7ebb65d3254be1e00002000000000000000004d0 0x00e0
0000000000000000000000000000000000000000000000000000000000000000 0x0100
0000000000000000000000000000000000000000000000000000000000000000 0x0120
000000000000000000000000677d4fbbcdd9093d725b0042081ab0b67c63d121 0x0140
00000000000000000000000000000000000000000000000006f05b59d3b20000 0x0160
00000000000000000000000000000000000000000000000000000000000000c0 0x0180
0000000000000000000000000000000000000000000000000000000000000000 0x01a0
Vamos primeiro percorrer cada palavra de 32 bytes de cima para baixo:
- Do bytes
0x00a0x1fencontramos0xe0, onde deveríamos encontrar a cabeça do primeiro argumento, uma struct. Lembra o que isso significa? Significa que pelo menos um campo da struct é dinâmico! Na verdade, a primeira struct tem um membro debytes. - Nos bytes de
0x20a0x3f, onde deveríamos encontrar a cabeça da segunda struct, encontramos o que parece ser um endereço (address). Este é de fato o primeiro membro da segunda struct: nas posições seguintes, até0x9f, você pode ver todos os outros membros. - Nos bytes de
0xa0a0xbf, encontramos o número hexadecimal0x0b3a7f984c82f6ffa3d428, que é 13574434982555110814766120 em base decimal: o terceiro parâmetro da função. - Nos bytes de
0xc0a0xdf, todos os bytes0xff: isso significa que o quarto parâmetro foi definido comotype(uint256).max.
Aqui está o que sabemos até agora:
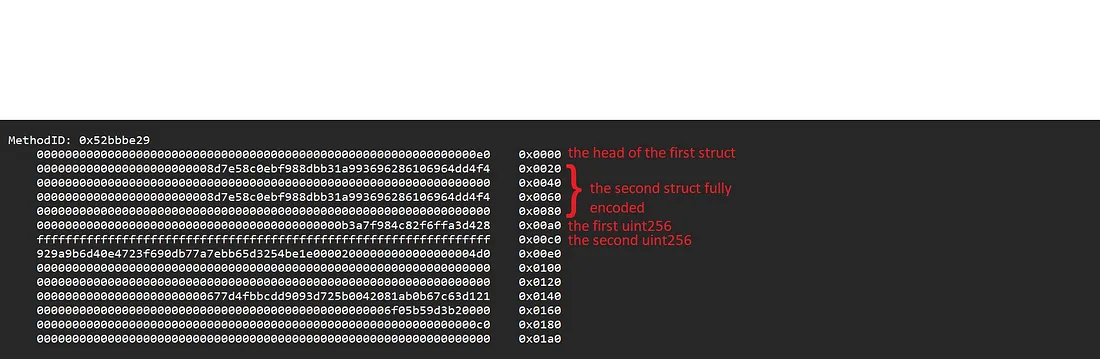
Encontramos as cabeças
Agora encontramos 3 dos 4 argumentos, não há muitos lugares onde o último possa estar escondido: lendo a cabeça da primeira struct como um deslocamento, somos levados à oitava palavra de cima, que é o primeiro membro da primeira struct, um elemento bytes32.
Depois disso, em cada palavra podemos encontrar todos os membros subsequentes da struct, até encontrarmos um 0xc0, onde o último membro bytes deveria estar.
A princípio, isso pode não fazer muito sentido, dado que o segundo uint256 é colocado na palavra que começa em 0xc0, então, o que está acontecendo? O que resolve essa confusão é entender que esse deslocamento não deve ser interpretado a partir do byte 0x00 da codificação do argumento, mas sim um deslocamento a partir de onde os membros da primeira struct são listados, ou seja, 0xe0.
Então, onde está o membro bytes? Na palavra que começa em 0xe0 + 0xc0 = 0x01a0! Como é um array de bytes vazio, este slot codifica 0 e nenhum dado subsequente é listado.
Aqui está o quadro completo:
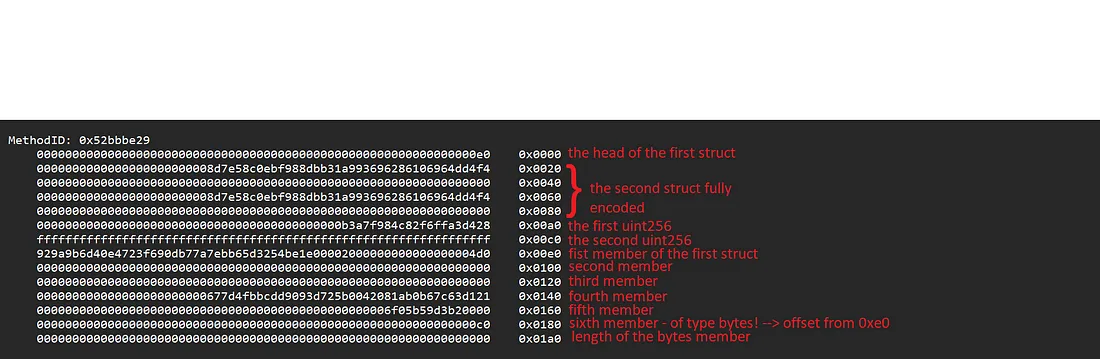
Detalhamento do calldata
Conclusão
Espero que esta tenha sido uma leitura interessante para você e que você tenha aprendido algo novo, assim como eu.
Se você quiser continuar e experimentar combinações mais exóticas de tipos (por exemplo, um array de tamanho dinâmico de estruturas que têm arrays de estruturas contendo membros de bytes), eu recomendo que você experimente o cast da cadeia de ferramentas Foundry: crie uma assinatura aleatória com esses tipos malucos e passe-os pelo cast abi-encode com os dados que você quiser e tente concluir o exercício que fizemos hoje.
Até a próxima!
Artigo original publicado por ljmanini. Traduzido por Paulinho Giovannini.






Oldest comments (0)