
Explorando os últimos avanços na detecção e segmentação de objetos com o Grounded-Segment-Anything do Google Colab
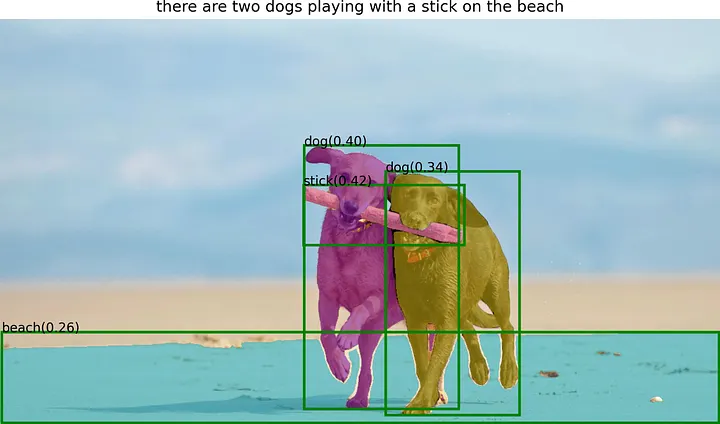
Crédito da imagem: https://github.com/IDEA-Research/Grounded-Segment-Anything
Introdução
A detecção e a segmentação de objetos são tarefas importantes na visão computacional, mas geralmente exigem a anotação manual de caixas delimitadoras ou máscaras de segmentação, o que pode ser demorado e caro. O Grounding DINO e o Segment Anything são dois modelos eficientes que podem automatizar essas tarefas com entradas de texto, permitindo a detecção e a segmentação de objetos com descrições de forma livre.
Que época para estar vivo!
Desde a semana de 10 de abril de 2023, tanto o Grounding DINO quanto o Segment Anything tem sido tendência entre os repositórios no GitHub Trending. Esses modelos chamaram a atenção por sua capacidade de detectar e segmentar objetos com entradas de texto de forma livre, oferecendo uma abordagem mais flexível e eficiente para o reconhecimento de objetos. Além disso, a demonstração do grupo IDEA Research do Grounded-Segment-Anything, que combina esses dois modelos, também tem gerado interesse devido ao seu potencial de geração automática de imagens e construção de conjuntos de dados. À medida que a pesquisa e o desenvolvimento nessa área continuarem, será interessante ver como esses modelos serão aplicados em vários setores e campos.
Não consigo ver o que a comunidade criará com essas ferramentas e estou animado com 'mais dois artigos' futuros.

Grounding DINO & Segment Anything
O Grounding DINO é um detector de objetos de tentativa zero (zero-shot) que pode gerar caixas e rótulos de alta qualidade com entradas de texto de forma livre. Por outro lado, o Segment Anything é um modelo de segmentação avançado que requer prompts como caixas ou pontos para gerar máscaras.
O SAM, abreviação de Segment Anything Model (Modelo de Segmentação de Qualquer Coisa), é uma ferramenta avançada para gerar máscaras de objetos de alta qualidade a partir de vários prompts de entrada, incluindo pontos ou caixas. Treinado em um conjunto de dados com mais de 11 milhões de imagens e 1,1 bilhão de máscaras, esse modelo de segmentação apresenta um desempenho robusto de tentativa zero em uma ampla gama de tarefas. Com o SAM, é possível gerar máscaras sem esforço para todos os objetos em uma imagem, o que o torna uma ferramenta inestimável para vários aplicativos de processamento de imagens.
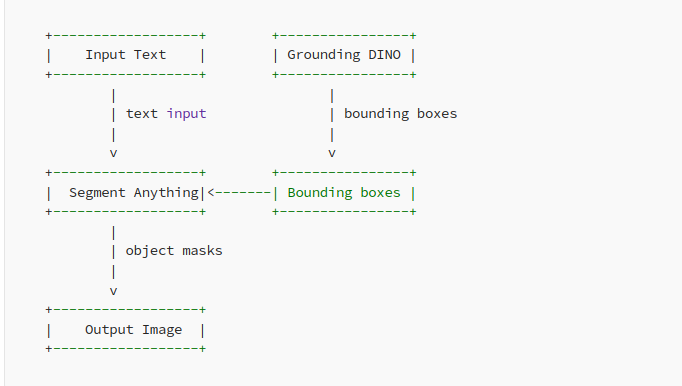
Ao combinar esses dois modelos, podemos detectar e segmentar objetos com entradas de texto sem a necessidade de caixas ou pontos explícitos. O Grounding DINO gera as caixas e os rótulos para os objetos, e o Segment Anything os utiliza para gerar máscaras de alta qualidade para segmentação. O modelo resultante, chamado Grounded-Segment-Anything, abre novas possibilidades para a detecção e segmentação de objetos em tarefas de processamento de linguagem natural.
A demonstração criada pelo IDEA Research mostra o poder combinado do Grounding DINO e do Segment Anything na detecção e segmentação de objetos com entradas de texto de forma livre. A demonstração permite que os usuários insiram um texto descritivo, que é processado pelo modelo Grounding DINO para gerar caixas delimitadoras e rótulos para os objetos descritos. Essas caixas delimitadoras e rótulos são então passados para o modelo Segment Anything, que gera máscaras de segmentação para os objetos. O resultado é uma imagem segmentada que retrata com precisão os objetos descritos na entrada de texto.
O repositório do GitHub para a demonstração pode ser encontrado em: https://github.com/IDEA-Research/Grounded-Segment-Anything.
Aqui está uma demonstração de implementação no Colab: https://colab.research.google.com/drive/1Sj13K6IHLccF2RnHzA7jWKrEmuU_ETWJ?usp=sharing
A demonstração mostra como usar a estrutura Grounded-Segment-Anything para detectar e segmentar objetos com entradas de texto de forma livre. Ela utiliza os modelos Grounding DINO e Segment Anything para realizar essa tarefa.

No exemplo acima, consegui segmentar os óculos e substituí-los por dois prompts de texto
Aqui está uma breve visão geral dos componentes principais e das etapas importantes da demonstração:
1. Instale as dependências e clone o repositório: A demonstração requer vários pacotes Python e o repositório Grounded-Segment-Anything. Eles são instalados e clonados no início do notebook.
2. Baixe os modelos pré-treinados: A demonstração usa modelos pré-treinados para Grounding DINO e Segment Anything, que são baixados e carregados na memória.
3. Insira texto e gere caixas delimitadoras: O usuário insere descrições de texto de forma livre dos objetos que deseja detectar e segmentar. O modelo Grounding DINO gera caixas delimitadoras para os objetos com base na entrada de texto.
4. Segmentar objetos: O modelo Segment Anything é usado para segmentar os objetos dentro das caixas delimitadoras geradas pelo Grounding DINO.

1. Exibir resultados: As imagens resultantes com objetos segmentados são exibidas para o usuário.
A demonstração oferece uma maneira simples, porém eficiente, de detectar e segmentar objetos com entradas de texto. É uma ótima ferramenta para pesquisadores e desenvolvedores que desejam explorar os recursos do Grounded-Segment-Anything.
A demonstração do Colab para o Grounded-Segment-Anything não apenas demonstra a detecção e a segmentação de objetos com entradas de texto, mas também inclui um recurso adicional que utiliza a difusão estável para pintar a máscara selecionada. Isso permite que os usuários gerem novos dados preenchendo as áreas ausentes de uma imagem.
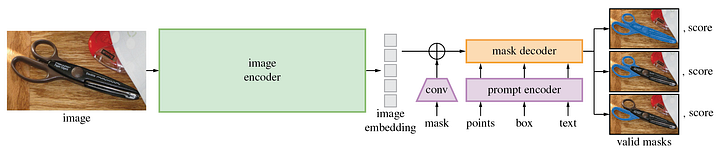
Crédito da imagem: https://github.com/facebookresearch/segment-anything
Aplicativos
O Grounded-Segment-Anything tem o potencial de ser aplicado em várias áreas, como geração automática de imagens, construção de conjuntos de dados e até mesmo na criação de modelos de base sólida com pré-treinamento de segmentação.
A geração automática de imagens pode ser obtida usando o Grounding DINO para gerar caixas e rótulos de alta qualidade com texto de forma livre, e o Segment Anything para segmentar os objetos. Isso pode ajudar a criar novos conjuntos de dados para aplicativos de aprendizado de máquina onde há falta de dados. Além disso, a combinação do Grounded-Segment-Anything com o Stable Diffusion pode ajudar a pintar a máscara selecionada, melhorando ainda mais a qualidade das imagens geradas.

Crédito da imagem: https://github.com/IDEA-Research/Grounded-Segment-Anything/tree/humanFace
Na construção de conjuntos de dados, o Grounded-Segment-Anything pode ser usado para rotular automaticamente imagens com caixas e máscaras, reduzindo o tempo e o esforço necessários para a rotulagem manual. Isso pode ser especialmente útil em aplicações como a detecção de objetos, em que grandes quantidades de dados rotulados são necessárias para o treinamento.
Em geral, o Grounded-Segment-Anything tem o potencial de melhorar muito a eficiência e a qualidade de vários aplicativos de aprendizado de máquina, e seus recursos são limitados apenas pela criatividade dos usuários que o aplicam.
Conclusão
O Grounded-Segment-Anything é uma ferramenta avançada para automatizar a detecção e a segmentação de objetos com entradas de texto, o que tem o potencial de economizar tempo e recursos em tarefas de visão computacional. Com a combinação do Grounding DINO e do Segment Anything, as possibilidades de geração automática de imagens e construção de conjuntos de dados são infinitas. Incentivamos pesquisadores e desenvolvedores a explorar o potencial do Grounded-Segment-Anything e a compartilhar seus projetos com a comunidade.
Saudações!

prompt = "Uma taça de vinho, de alta qualidade, detalhada, com muitos detalhes."
Se você estiver interessado em explorar mais ferramentas de IA de código aberto, confira minha recente análise do Open Assistant da LAION-AI, uma nova alternativa ao ChatGPT. Você pode encontrá-lo aqui: https://ashokpoudel.medium.com/a-new-open-source-chatbot-alternative-a-review-of-open-assistant-334b1b77901b e, se estiver interessado em OCR, leia meu outro artigo Transforming Document Processing with Pix2Struct and TrOCR: A Deep Dive into Modern OCR and VQA Technologies.
Não se esqueça de me seguir no Medium e no Twitter (@ashokpoudel) para obter mais atualizações sobre artigos semelhantes.
Este artigo foi escrito por Ashok Poudel e traduzido por Adriano P. de Araujo. O original em inglês pode ser encontrado aqui