Artigo traduzido do original Why sharding is great: demystifying the technical properties por Vitalik Buterin (https://vitalik.ca/general/2021/04/07/sharding.html)
Agradecimentos especiais a Dankrad Feist e Aditya Asgaonkar pela revisão
Sharding é o futuro da escalabilidade do Ethereum e será fundamental para ajudar o ecossistema a suportar milhares de transações por segundo e permitir que uma grande parcela do mundo use regularmente a plataforma a um custo acessível. No entanto, também é um dos conceitos mais incompreendidos no ecossistema Ethereum e, de forma geral, nos demais ecossistemas blockchain. Refere-se a um conjunto muito específico de ideias com propriedades muito específicas, mas muitas vezes é confundido com técnicas que têm propriedades de segurança muito diferentes e muito mais fracas. O objetivo deste post é explicar exatamente quais propriedades específicas o sharding oferece, como ele difere de outras tecnologias que não são baseadas em sharding e quais sacrifícios um sistema baseado em shards precisa fazer para alcançar essas propriedades.
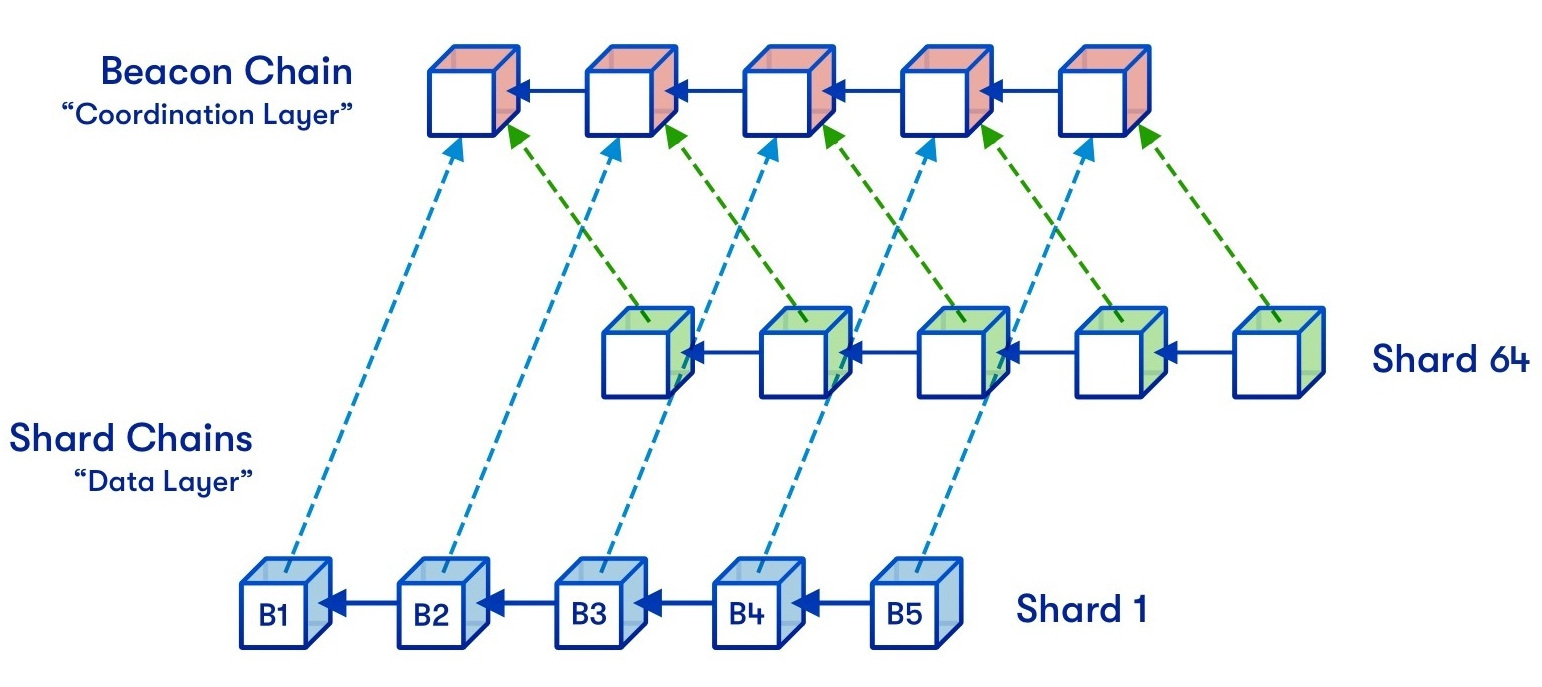
 Uma das muitas representações de uma versão de sharding do Ethereum. Diagrama original de Hsiao-wei Wang, design de Quantstamp.
Uma das muitas representações de uma versão de sharding do Ethereum. Diagrama original de Hsiao-wei Wang, design de Quantstamp.
O Trilema da Escalabilidade
A melhor maneira de descrever o sharding começa com a declaração do problema que o moldou e inspirou a sua solução: o Trilema da Escalabilidade.
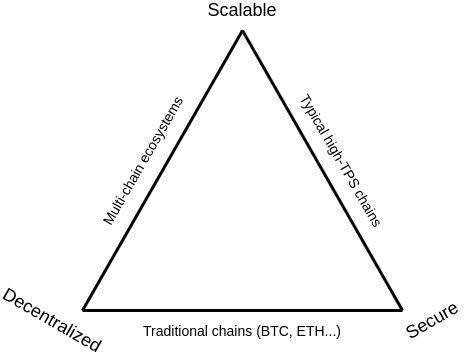
O trilema da escalabilidade diz que existem três propriedades que uma blockchain tenta ter e que, se você se ater a técnicas "simples", só poderá obter duas dessas três. As três propriedades são:
- Escalabilidade: a chain pode processar mais transações do que um único nó regular (pense em um notebook de usuário) possa verificar.
- Descentralização: a chain pode ser executada sem dependências de confiança em um pequeno grupo de grandes atores centralizados. Isso é geralmente interpretado como não depender da confiança (ou mesmo suposição de maioria honesta) em um conjunto de nós que você não possa se unir com apenas um notebook de usuário.
- Segurança: a chain pode resistir a uma grande porcentagem de nós participantes tentando atacá-la (idealmente 50%; qualquer coisa acima de 25% está bem, 5% definitivamente não está bem).
Agora podemos olhar para as três classes de "soluções fáceis" que obtêm apenas duas das três:
- Blockchains tradicionais - incluindo Bitcoin, Ethereum pré-PoS (Proof of stake)/sharding, Litecoin e outras chains semelhantes. Eles dependem de cada participante executando um nó completo que verifica todas as transações e, portanto, têm descentralização e segurança, mas não escalabilidade.
- Chains High-TPS - incluindo a família DPoS (Delegated Proof of Stake), mas também muitas outras. Eles dependem de um pequeno número de nós (geralmente de 10 a 100) mantendo o consenso entre si, com os usuários precisando confiar na maioria desses nós. Isso é escalável e seguro (usando as definições acima), mas não é descentralizado.
- Ecossistemas multi-chains - refere-se ao conceito geral de "scaling out" ao ter diferentes aplicações em diferentes chains e usando protocolos de comunicação cross-chains para conversar entre elas. Isso é descentralizado e escalável, mas não é seguro, porque um invasor precisa obter apenas uma maioria dos nós de consenso em uma das muitas chains (muitas vezes <1% de todo o ecossistema) para quebrar aquela chain e possivelmente causar efeitos em cascata que causam grande prejuízo para aplicações em outras chains.
O sharding é uma técnica que você obtém todos os três. Uma blockchain baseada em sharding é:
- Escalável: pode processar muito mais transações do que um único nó
- Descentralizada: pode sobreviver inteiramente em notebooks de usuários, sem dependência de "super nós"
- Segura: um invasor não pode atingir uma pequena parte do sistema com uma pequena quantidade de recursos; eles só podem tentar dominar e atacar a coisa toda
O resto do post descreve como blockchains baseadas em sharding conseguem fazer isso.
Sharding por amostragem aleatória
A versão mais fácil de entender de sharding é o sharding por amostragem aleatória. O sharding por amostragem aleatória tem propriedades de confiança mais fracas do que as formas de sharding que estamos construindo no ecossistema Ethereum, mas usa tecnologia mais simples.
A ideia central é a seguinte. Suponha que você tenha uma chain Proof of Stake com um grande número de validadores (por exemplo, 10.000) e um grande número de blocos que precisa ser verificado (por exemplo, 100). Nenhum computador é poderoso o suficiente para validar todos esses blocos antes que o próximo conjunto de blocos chegue.
Portanto, o que fazemos é dividir aleatoriamente o trabalho de verificação. Embaralhamos aleatoriamente a lista de validadores e atribuímos os primeiros 100 validadores na lista embaralhada para verificar o primeiro bloco, os segundos 100 validadores na lista embaralhada para verificar o segundo bloco etc. Um grupo de validadores selecionados aleatoriamente que é atribuído a verificar um bloco (ou realizar alguma outra tarefa) é chamado de comitê.
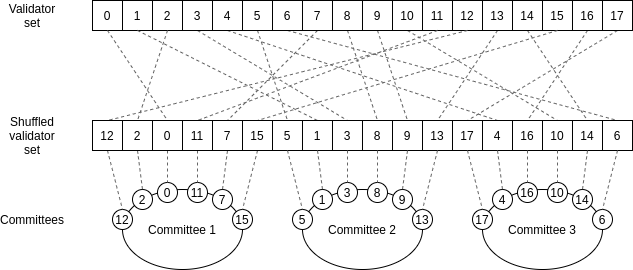
Quando um validador verifica um bloco, ele publica uma assinatura atestando o fato de que o fez. Todos os outros, em vez de verificar 100 blocos inteiros, agora verificam apenas 10.000 assinaturas - uma quantidade muito menor de trabalho, especialmente com agregação de assinatura BLS. Ao invés de cada bloco ser transmitido pela mesma rede P2P, cada bloco é transmitido em uma sub-rede diferente, e os nós precisam apenas ingressar nas sub-redes correspondentes aos blocos pelos quais são responsáveis (ou estão interessados por outros motivos).
Considere o que acontece se o poder de computação de cada nó aumentar em 2x. Como cada nó agora pode validar com segurança 2x mais assinaturas, você pode reduzir o tamanho mínimo do depósito de staking para suportar 2x mais validadores e, portanto, pode fazer 200 comitês ao invés de 100. Assim, você pode verificar 200 blocos por slot ao invés de 100. Além disso, cada bloco individual pode ser 2x maior. Assim, você tem 2x mais blocos de 2x o tamanho, ou 4x mais capacidade total na cadeia.
Podemos introduzir alguns jargões matemáticos para falar sobre o que está acontecendo. Usando notação Big O, usamos "O(C)" para nos referirmos à capacidade computacional de um único nó. Uma blockchain tradicional pode processar blocos de tamanho O(C). Uma cadeia baseada em sharding como descrita acima pode processar O(C) em paralelo (lembre-se, o custo de cada nó para verificar indiretamente cada bloco é O(1) porque cada nó precisa apenas verificar um número fixo de assinaturas), e cada bloco tem O(C) e, portanto, a capacidade total da cadeia baseada em sharding é O(C2). É por isso que chamamos esse tipo de sharding de sharding quadrático, e esse efeito é uma das principais razões pelas quais pensamos que, a longo prazo, sharding é a melhor maneira de dimensionar uma blockchain.
Pergunta frequente: como a divisão em 100 comitês é diferente da divisão em 100 chains separadas?
Existem duas diferenças principais:
- A amostragem aleatória impede que o invasor concentre seu poder em um shard. Em um ecossistema multi-chain de 100 chains, o invasor precisa apenas de ~0,5% da participação total para causar estragos: eles podem se concentrar em 51% atacando uma única chain. Em uma blockchain baseada em sharding, o invasor deve ter cerca de ~30-40% de todo stake para fazer o mesmo (em outras palavras, a chain compartilhou segurança). Certamente, eles podem esperar até que tenham sorte e obtenham 51% em um único shard por acaso, apesar de terem menos de 50% do stake total, mas isso fica exponencialmente mais difícil para invasores que têm muito menos de 51%. Se um invasor tiver menos de ~30%, é praticamente impossível.
- Acoplamento forte: mesmo que um shard receba um bloco ruim, toda a chain se reorganiza para evitá-lo. Existe um contrato social (e nas seções posteriores deste documento descrevemos algumas maneiras de impor isso tecnologicamente) que uma chain com mesmo um bloco defeituoso em um shard não é aceitável e deve ser descartada assim que for descoberta. Isso garante que, do ponto de vista de uma aplicação dentro da chain, haja perfeita segurança: o contrato A pode contar com o contrato B, pois se o contrato B se comportar mal devido a um ataque à cadeia, todo esse histórico é revertido, incluindo as transações em contrato A que se comportou mal como resultado do mau funcionamento do contrato B.
Ambas as diferenças garantem que o sharding crie um ambiente para aplicações que preserva as principais propriedades de segurança de um ambiente single-chain, de uma forma que os ecossistemas multi-chain fundamentalmente não fazem.
Melhorando o sharding com melhores modelos de segurança
Um refrão comum nos círculos do Bitcoin, e com o qual concordo completamente, é que blockchains como Bitcoin (ou Ethereum) NÃO dependem completamente de uma suposição de maioria honesta. Se houver um ataque de 51% em tal blockchain, o invasor poderá fazer algumas coisas desagradáveis, como reverter ou censurar transações, mas não poderá inserir transações inválidas. E mesmo que revertam ou censurem transações, os usuários que executam nós regulares podem detectar facilmente esse comportamento, portanto, se a comunidade desejar coordenar para resolver o ataque com um fork que tire o poder do invasor, poderá fazê-lo rapidamente.
A falta dessa segurança extra é uma fraqueza fundamental das chains mais centralizadas de High-TPS. Essas cadeias não têm e não podem ter uma cultura de usuários regulares executando nós e, portanto, os principais nós e participantes do ecossistema podem se reunir com muito mais facilidade e impor uma mudança de protocolo que a comunidade não gosta muito. Pior ainda, os nós dos usuários o aceitariam por padrão. Depois de algum tempo, os usuários perceberiam, mas então a mudança forçada de protocolo seria um fato consumado: o ônus da coordenação recairia sobre os usuários para rejeitar a mudança, e eles teriam que tomar a dolorosa decisão de reverter o valor de um dia ou mais de atividade que todos pensavam já estarem finalizadas.
Idealmente, queremos ter uma forma de sharding que evite 51% de suposições de confiança para validade e que preserve o poderoso baluarte de segurança que as blockchains tradicionais obtêm de verificações completas. E é exatamente sobre isso que grande parte da nossa pesquisa tem sido nos últimos anos.
Verificação escalável da computação
Podemos dividir em dois casos o problema de validação escalável à prova de ataque dos 51%:
- Validando a computação: verificando que alguma computação foi feita corretamente, assumindo que você possui todas as entradas para a computação
- Validando a disponibilidade dos dados: verificando que as entradas para a computação em si são armazenadas de alguma forma onde você pode baixá-las se realmente precisar; esta verificação deve ser realizada sem realmente baixar todas as entradas (porque os dados podem ser muito grandes para baixar para cada bloco)
Validar um bloco em uma blockchain envolve tanto computação quanto verificação de disponibilidade de dados: você precisa estar convencido de que as transações no bloco são válidas e que o hash do novo estado raiz que está sendo reivindicado no bloco é o resultado correto da execução dessas transações, mas você também precisa estar convencido de que dados suficientes do bloco foram realmente publicados para que os usuários que baixarem esses dados possam calcular seu estado e continuar processando a blockchain. Esta segunda parte é um conceito muito sutil, mas importante, chamado de problema de disponibilidade dos dados; mais sobre isso a seguir.
Validar a computação de forma escalável é relativamente fácil; existem duas famílias de técnicas: fraud proofs (provas de fraude) e ZK-SNARKs.
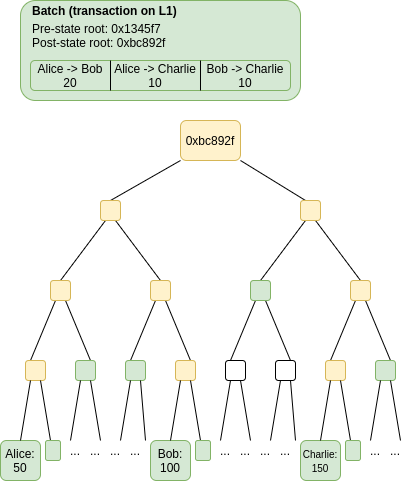
As provas de fraude são uma maneira de verificar a computação de forma escalável.
As duas tecnologias podem ser descritas de forma simples:
- Fraud proofs são um sistema em que para aceitar o resultado de um cálculo, você exige que alguém com um depósito assine uma mensagem do tipo "Certifico que se você fizer o cálculo C com a entrada X, você obtém a saída Y". Você confia nessas mensagens por padrão, mas deixa em aberto a oportunidade para outra pessoa com depósito staked realizar um desafio (uma mensagem assinada dizendo "Eu discordo, a saída é Z"). Todos os nós executam a computação somente quando há um desafio. Qualquer uma das duas partes que estava errada perde seu depósito, e todos os cálculos que dependem do resultado desse cálculo são recalculados.
- ZK-SNARKs são uma forma de prova criptográfica que comprova diretamente a afirmação "realizar a computação C na entrada X dá a saída Y". A prova é criptograficamente "sólida": se C(x) não for igual a Y, é computacionalmente inviável fazer uma prova válida. A prova também é rápida de verificar, mesmo que executar C leve muito tempo. Veja este post para mais detalhes matemáticos sobre ZK-SNARKs.
A computação baseada em fraud proofs é escalável porque "no caso normal" você substitui a execução de uma computação complexa pela verificação de uma única assinatura. Existe o caso excepcional, em que você precisa verificar a computação na chain porque há um desafio, mas o caso excepcional é muito raro porque ativá-lo é muito caro (o reclamante original ou o desafiante perdem um grande depósito). ZK-SNARKs são conceitualmente mais simples - eles apenas substituem uma computação por uma verificação de prova muito mais barata - mas a matemática por trás de como eles funcionam é consideravelmente mais complexa.
Existe uma classe de sistema semi-escalável que apenas verifica a computação de forma escalável, enquanto ainda exige que cada nó verifique todos os dados. Isso pode ser bastante eficaz usando um conjunto de "truques" de compactação para substituir a maioria dos dados por computação. Este é o domínio dos rollups.
Verificação escalável de disponibilidade de dados é difícil
Uma fraud proof não pode ser usada para verificar a disponibilidade de dados. As fraud proofs para computação dependem do fato de que as entradas para a computação sejam publicadas na chain no momento em que a reivindicação original é enviada e, portanto, se alguém contestar, a execução do desafio estará acontecendo exatamente no mesmo "ambiente" em que a execução original aconteceu. No caso de verificar a disponibilidade dos dados, não é possível fazer isso, pois o problema é justamente o fato de haver muitos dados a serem verificados para publicá-los na chain. Portanto, um esquema fraud proof para disponibilidade de dados se depara com um problema fundamental: alguém pode alegar que "os dados X estão disponíveis" sem publicá-los, esperar para ser desafiado e só então publicar os dados X e fazer com que o desafiante pareça para o resto da rede que estava incorreto.
Isso é expandido no dilema do pescador (fishermen dilemma):
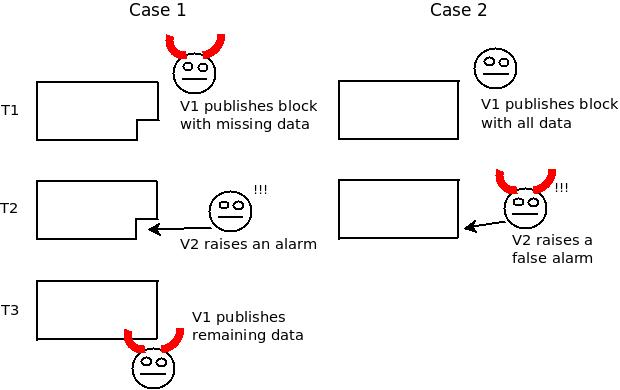
A ideia central é que os dois "mundos", um onde V1 é um editor malvado e V2 é um desafiante honesto e o outro onde V1 é um editor honesto e V2 é um desafiante malvado, são indistinguíveis para quem não estava tentando fazer o download desse dado no momento específico. E, claro, em uma blockchain descentralizada e escalável, cada nó individual só pode esperar o download de uma pequena parte dos dados, então apenas uma pequena parte dos nós veria algo sobre o que aconteceu, exceto pelo mero fato de que houve um desacordo.
O fato de ser impossível distinguir quem estava certo e quem estava errado torna impossível ter um esquema fraud proofs funcional para disponibilidade de dados.
Pergunta frequente: e se alguns dos dados não estiverem disponíveis? Com um ZK-SNARK você pode ter certeza de que tudo é válido, e isso não é suficiente?
Infelizmente, a mera validade não é suficiente para garantir que uma blockchain esteja funcionando corretamente. Isso ocorre porque se a blockchain for válida mas todos os dados não estiverem disponíveis, os usuários não terão como atualizar os dados necessários para gerar provas de que qualquer bloco futuro é válido. Um invasor que gera um bloco válido, mas indisponível, e que depois desaparece, pode efetivamente paralisar a cadeia. Alguém também pode reter os dados da conta de um usuário específico até que o usuário pague um resgate, para que o problema não seja puramente um problema de prova de vida.
Existem alguns argumentos fortes da teoria da informação de que esse problema é fundamental, e que não há "truque" inteligente (por exemplo, envolvendo acumuladores criptográficos) que possa contorná-lo. Este documento tem mais detalhes.
Então, como você verifica se 1 MB de dados está disponível sem realmente tentar fazer o download? Isso parece impossível!
A chave é uma tecnologia chamada amostragem de disponibilidade de dados. A amostragem de disponibilidade de dados funciona da seguinte forma:
- Use uma ferramenta chamada erasure coding (codificação de eliminação) para expandir um dado com N fragmentos em um pedaço de dados com 2N fragmentos, de modo que qualquer N desses fragmentos possa recuperar os dados inteiros.
- Para verificar a disponibilidade, ao invés de tentar fazer o download de todos os dados, os usuários simplesmente selecionam aleatoriamente um número constante de posições no bloco (por exemplo, 30 posições) e aceitam o bloco somente quando tiverem encontrado com sucesso os fragmentos
- no bloco de suas posições selecionadas.
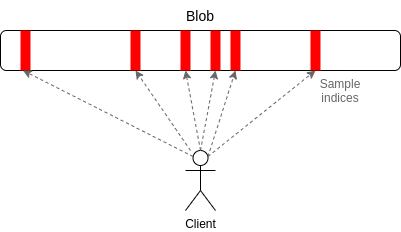
Os **erasure codes **(códigos de eliminação) transformam um problema de "verificação de 100% de disponibilidade" (todos os dados estão disponíveis) em um problema de "verificação de 50% de disponibilidade" (pelo menos metade das peças estão disponíveis). A amostragem aleatória resolve o problema de disponibilidade de 50%. Se menos de 50% dos dados estiverem disponíveis, pelo menos uma das verificações quase certamente falhará, e se pelo menos 50% dos dados estiverem disponíveis, enquanto alguns nós podem falhar em reconhecer um bloco como disponível, leva apenas um nó honesto para executar o procedimento de reconstrução do código de eliminação para trazer de volta os 50% restantes do bloco. E assim, ao invés de precisar baixar 1 MB para verificar a disponibilidade de um bloco de 1 MB, você só precisa baixar alguns kilobytes. Isso torna viável executar a verificação de disponibilidade de dados em cada bloco. Veja esta postagem para saber como essa verificação pode ser implementada com eficiência com sub-redes ponto a ponto.
Um ZK-SNARK pode ser usado para verificar se o erasure coding em um dado foi feito corretamente e, em seguida, as Merkle branches podem ser usadas para verificar partes individuais. Alternativamente, você pode usar polynomial commitments (por exemplo Kate commitments (também chamado de KZG)), que essencialmente realizam erasure coding, comprovam elementos individuais e verificam a corretude, tudo em um componente simples - e é isso que está sendo usando no sharding em Ethereum.
Recapitulando: como estamos garantindo que tudo esteja correto novamente?
Suponha que você tenha 100 blocos e queira verificar com eficiência a exatidão de todos eles sem depender de comitês. Precisamos fazer o seguinte:
- Cada cliente realiza a amostragem de disponibilidade de dados em cada bloco, verificando se os dados em cada bloco estão disponíveis, enquanto realiza o download de apenas alguns kilobytes por bloco, mesmo que o bloco como um todo tenha um megabyte ou seja maior. Um cliente só aceita um bloco quando todos os dados de seus desafios de disponibilidade foram respondidos corretamente.
- Agora que verificamos a disponibilidade dos dados, fica mais fácil verificar a exatidão. Existem duas técnicas:
- Podemos usar fraud proofs: alguns participantes com depósitos em staking podem assinar a exatidão de cada bloco. Outros nós, chamados desafiadores (ou pescadores/fishermen), verificam aleatoriamente e tentam processar os blocos completamente. Como já verificamos a disponibilidade dos dados, sempre será possível realizar o download dos dados e processar integralmente qualquer bloco específico. Se eles encontrarem um bloco inválido, farão um desafio que todos verificarão. Se o bloco for ruim, então esse bloco e todos os blocos futuros que dependem dele precisam ser recalculados.
- Podemos usar ZK-SNARKs. Cada bloco viria com um ZK-SNARK provando a exatidão.
- Em qualquer um dos casos acima, cada cliente precisa fazer apenas uma pequena quantidade de trabalho de verificação por bloco, não importa o tamanho do bloco. No caso de fraud proofs, os blocos, ocasionalmente, precisarão ser totalmente verificados on-chain, mas isso deve ser extremamente raro porque até mesmo lançar um desafio é muito caro.
E isso é tudo o que há! No caso do sharding em Ethereum, o plano de curto prazo é tornar os blocos sharded **data-only **(apenas dados); ou seja, os shards são puramente um "motor de disponibilidade de dados" e é o trabalho dos layer-2 rollups usar esse espaço de dados seguro, além de fraud proofs ou ZK-SNARKs, para implementar capacidades de processamento de transações seguras de high-throughput. No entanto, é completamente possível criar um sistema integrado para adicionar execução de high-throughput de forma "nativa".
Quais são as principais propriedades dos sistemas baseados em sharding e quais são as vantagens e desvantagens?
O principal objetivo do sharding é chegar o mais próximo possível de replicar as propriedades de segurança mais importantes das blockchains tradicionais (não-sharded), mas sem a necessidade de cada nó verificar pessoalmente cada transação.
O sharding chega bem perto. Em uma blockchain tradicional:
- blocos inválidos não podem seguir porque os nós de validação percebem que são inválidos e os ignoram.
- Blocos indisponíveis não podem seguir porque os nós de validação falham em realizar o download e os ignoram.
Em uma blockchain baseada em sharding com recursos de segurança avançados:
- Blocos inválidos não podem seguir porque:
- uma fraud proof os identifica rapidamente e informa toda a rede sobre a incorreção do bloco e penaliza fortemente o criador, ou
- um ZK-SNARK prova a correção, e você não pode criar um ZK-SNARK válido para um bloco inválido.
- Blocos indisponíveis não podem seguir porque:
- Se menos de 50% dos dados de um bloco estiverem disponíveis, pelo menos uma verificação de amostra de disponibilidade de dados quase certamente falhará para cada cliente, fazendo com que o cliente rejeite o bloco,
- Se pelo menos 50% dos dados de um bloco estiverem disponíveis, então o bloco inteiro estará disponível, porque é preciso apenas um único nó honesto para reconstruir o resto do bloco.
As cadeias tradicionais de high-TPS e sem sharding não têm como fornecer essas garantias. Ecossistemas multi-chain não têm como evitar o problema de um invasor selecionar uma chain para atacá-la e tomá-la facilmente (as cadeias podem compartilhar a segurança, mas se isso for mal feito, se transformará de fato em uma chain tradicional de high-TPS com todas as suas desvantagens, e, se fosse bem feito, seria apenas uma implementação mais complicada das técnicas de sharding acima).
Sidechains são altamente dependentes da implementação, mas normalmente são vulneráveis às fraquezas das cadeias tradicionais de high-TPS (isto é, se elas compartilham mineradores/validadores), ou às fraquezas dos ecossistemas multi-chain (isto é, se eles não compartilham mineradores/validadores). As chains baseadas em sharding evitam esses problemas.
No entanto, existem algumas rachaduras na armadura dos sistemas baseados em sharding. Notavelmente:
- chains baseadas em sharding que dependem apenas de comitês são vulneráveis a adversários adaptáveis e têm responsabilidade mais fraca. Ou seja, se o adversário tiver a capacidade de invadir (ou simplesmente desligar) qualquer conjunto de nós de sua escolha em tempo real, ele só precisará atacar um pequeno número de nós para quebrar um único comitê. Além disso, se um adversário (seja um adversário adaptativo ou apenas um atacante com 50% da participação total) quebrar um único comitê, apenas alguns de seus nós (os que estão nesse comitê) poderão ser confirmados publicamente como participantes desse ataque e, portanto, apenas uma pequena quantidade em staking poderá ser penalizada. Esta é outra razão importante pela qual a amostragem de disponibilidade de dados juntamente com provas de fraude ou ZK-SNARKs são um complemento importante para as técnicas de amostragem aleatória.
- A amostragem de disponibilidade de dados só é segura se houver um número suficiente de clientes online para que eles coletivamente façam solicitações de amostragem de disponibilidade de dados suficientes para que as respostas quase sempre se sobreponham para abranger pelo menos 50% do bloco. Na prática, isso significa que deve haver algumas centenas de clientes online (e esse número aumenta quanto maior for a relação entre a capacidade do sistema e a capacidade de um único nó). Este é um modelo de confiança de poucos de N (few-of-N trust model) - geralmente bastante confiável, mas certamente não tão robusto quanto a confiança de 0 de N (0-of-N) que os nós em chains non-sharded têm disponíveis.
- Se a cadeia baseada em sharding depende de fraud proofs, então ela depende de suposições de tempo; se a rede for muito lenta, os nós podem aceitar um bloco como finalizado antes que a prova de fraude chegue mostrando que está errado. Felizmente, se você seguir uma regra estrita de reverter todos os blocos inválidos assim que a invalidez for descoberta, esse limite é um parâmetro definido pelo usuário: cada usuário individual escolhe quanto tempo espera até a finalização e, se não quiser o suficiente, sofrerá, mas usuários mais cuidadosos são seguros. Mesmo assim, isso é um enfraquecimento da experiência do usuário. Usar ZK-SNARKs para verificar a validade resolve isso.
- Há uma quantidade muito maior de dados brutos que precisam ser repassados, aumentando o risco de falhas em condições extremas de rede. Pequenas quantidades de dados são mais fáceis de enviar (e mais fáceis de serem ocultadas com segurança, se um governo poderoso tentar censurar a chain) do que grandes quantidades de dados. Os exploradores de blocos precisam armazenar mais dados se quiserem manter toda a cadeia.
- Blockchains baseadas em sharding dependem de redes peer-to-peer baseadas em sharding, e cada "sub-rede" p2p individual é mais fácil de atacar porque tem menos nós. O modelo de sub-rede usado para amostragem de disponibilidade de dados atenua isso porque há alguma redundância entre as sub-redes, mas mesmo assim há um risco.
Essas são preocupações válidas, embora, em nossa opinião, sejam superadas pela redução na centralização no nível do usuário habilitada ao permitir que mais aplicações sejam executadas on-chain ao invés de por meio de serviços de layer-2 centralizados. Dito isso, essas preocupações, especialmente as duas últimas, são, na prática, as restrições reais para aumentar a taxa de transferência de uma chain baseada em sharding além de um certo ponto. Há um limite para a quadraticidade do sharding quadrático.
Aliás, os crescentes riscos de segurança de blockchains baseadas em sharding se sua taxa de transferência se tornar muito alta também são a principal razão pela qual o esforço para estender para o sharding superquadrático foi amplamente abandonado; parece que manter o sharding quadrático apenas quadrático é realmente o meio termo.
Por que não produção centralizada e a verificação em sharding?
Uma alternativa ao sharding que é frequentemente proposta é ter uma chain estruturada como uma chain high-TPS centralizada, exceto que usa amostragem de disponibilidade de dados e sharding no topo para permitir a verificação de validade e disponibilidade.
Isso melhora as chains high-TPS centralizadas como existem hoje, mas ainda é consideravelmente mais fraco do que um sistema baseado em sharding. Isso ocorre por alguns motivos:
- É muito mais difícil detectar censura por produtores de blocos em uma chain high-TPS. A detecção de censura requer (i) ser capaz de ver todas as transações e verificar se não há transações que claramente mereçam entrar e que inexplicavelmente não conseguem entrar, ou (ii) ter um modelo de confiança 1-de-N em produtores de blocos e verificando se nenhum bloco falha ao entrar. Em uma chain high-TPS centralizada, (i) é impossível e (ii) é mais difícil porque a pequena contagem de nós torna até mesmo um modelo de confiança 1-de-N mais propenso a quebrar, e se a chain tiver um tempo de bloqueio muito rápido para o DAS (como a maioria das chains high-TPS centralizadas), é muito difícil provar que os blocos de um nó não estão sendo rejeitados simplesmente porque todos estão sendo publicados muito lentamente.
- Se a maioria dos produtores de blocos e membros do ecossistema tentar forçar uma mudança impopular do protocolo, os clientes dos usuários certamente detectarão, mas é muito mais difícil para a comunidade se rebelar e se separar (fork) porque precisaria criar um novo conjunto de nós de alta performance (high-performance) bastante caros para manter uma chain que mantém as regras antigas.
- A infraestrutura centralizada é mais vulnerável à censura imposta por atores externos. A alta taxa de transferência dos nós produtores de blocos os torna muito detectáveis e fáceis de desligar. Também é politicamente e logisticamente mais fácil censurar computação dedicada de alta performance do que perseguir notebooks de usuários individuais.
- Há uma pressão mais forte para que a computação de alta performance mude para serviços de nuvem centralizados, aumentando o risco de que toda a chain seja executada nos serviços de nuvem de 1 a 3 empresas e, portanto, o risco da chain cair devido a muitos produtores de blocos falharem simultaneamente. Uma chain baseada em sharding com uma cultura de execução de validadores no próprio hardware é novamente muito menos vulnerável a isso.
Sistemas baseados em sharding são adequadamente melhores como camada-base. Dada uma camada-base baseada em sharding, você sempre pode criar sistemas de produção centralizados (por exemplo, porque deseja um domínio de alto rendimento com capacidade de composição síncrona para DeFi) em camadas superiores, construindo-os como um rollup. Mas se você tiver uma camada-base com dependência na produção centralizada de blocos, não poderá construir uma layer-2 mais descentralizada no topo.