
11 de novembro de 2022
Este artigo se concentrará em treinar uma incorporação mais profunda e capaz de ir além do software Stable Diffusion original que descrevemos no post anterior - Stable Diffusion Training for Personal Embedding, que já possui uma incorporação sólida para ser usado na geração de arte. Queremos treiná-la para ser ainda mais customizada, de forma que percorra contextos maiores e mais complexos.
O treinamento desse modelo de ponto de verificação mais generalizado será feito por meio do uso da técnica de treinamento de hiper-rede do Dreambooth. Isso combinará a imagem pessoal e a incorporação dentro dela, o que leva a uma nova arte com muito mais qualidade e precisão do que a arte anterior criada apenas a partir de um modelo básico de incorporação do Stable Diffusion. Este é o próximo passo e irá melhorar a fidelidade e precisão desta arte e a compreensão da IA das instruções dadas.

Figura: todas as imaginações criativas de incorporação pessoal no brinquedo e nos materiais! Do canto superior esquerdo, figura de ação, cabeça de batata, boneco de pelúcia, simpson, play-doh, minifigura de lego, gato garfield, disney, low-poly, funko-pop, pixar, plástico, videogame, cachorro, boneco de lã, blocos de lego.
Depois de aprendermos a usar o Dreambooth no treinamento de uma incorporação pessoal, também vamos explorar os tópicos sobre a criatividade da IA e aprender como melhorar as imagens geradas pelo inpainting do img2img.
Usando o Dreambooth
O Dreambooth e o Stable Diffusion são capazes de produzir grandes obras de arte. As principais diferenças são que o Dreambooth é mais voltado para usuários que desejam criar imagens que se pareçam com uma pessoa específica, enquanto o Stable Diffusion é uma geração de imagem mais geral.
- Com o Stable Diffusion, o artista cria um prompt e o executa no sistema de IA para ver quais imagens são geradas. Esse sistema pode produzir imagens mais realistas, mas pode demorar mais para gerar algo que o usuário goste.
- Com o Dreambooth, o artista treina um sistema de IA para criar um estilo de arte ou artista específico. As imagens produzidas são mais previsíveis e mais rápidas de gerar.
O Dreambooth é capaz de gerar resultados mais precisos, mas só pode gerar indivíduos específicos. O Stable Diffusion pode gerar uma variedade de imagens, mas os resultados podem ser menos precisos. Para uso geral, o Stable Diffusion é uma escolha melhor - embora para uso individual preciso, o Dreambooth seja uma escolha superior.

Figura: ao inserir um conjunto de imagens pessoais, o treinamento Dreambooth produzirá um modelo de hiper-rede do Stable Diffusion que pode ser usado em vários contextos. Veja o artigo original de Nataniel Ruiz, et. al., DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation.
Seguindo o vídeo “Aitrepreneur” no YouTube, que detalha como usar o Dreambooth para treinar um modelo de Stable Diffusion personalizado no RunPod.io ou no ambiente Colab do Google, ele explica o processo passo a passo e até inclui as referências de código necessárias na descrição do vídeo. Vemos que o modelo personalizado treinado tem um desempenho tão bom que nos motiva a experimentar a técnica nós mesmos!
Como Encontrar o Hardware de Treinamento?
Um dos nossos maiores obstáculos no treinamento com o algoritmo Dreambooth é o requisito de hardware. Esse algoritmo requer uma GPU com, no mínimo, 24GB de VRAM. Embora a NVidia RTX 3090 seja uma ótima opção, se você conseguir uma, o preço de uma nova é de um valor enorme de $ 1.500 CAD. Estamos procurando uma alternativa mais barata, como um serviço de nuvem que possa oferecer esse nível de VRAM por um preço mais baixo.
Depois de procurar servidores adequados com o hardware necessário, resolvemos usar o RunPod.io. Ele oferece a opção de alugar uma máquina segura baseada em nuvem que inclui uma RTX A5000 com 24GB de VRAM. Esse aluguel custa apenas US$ 0,49 a hora, muito mais acessível do que comprar a NVidia RTX 3090!
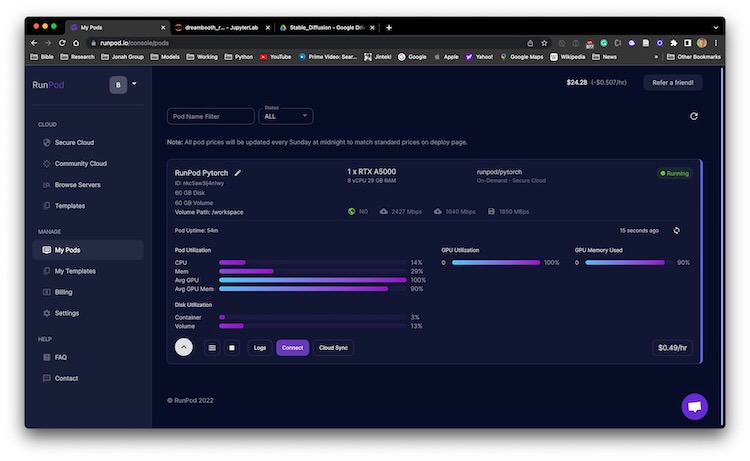
Nota importante!!! Ao iniciar o Pod, verifique se há mais espaços em disco alocados. No nosso caso, altere de 20 para 40GB para os espaços de disco de contêiner e de disco de volume; caso contrário, corremos o risco de ficar sem espaço em disco.
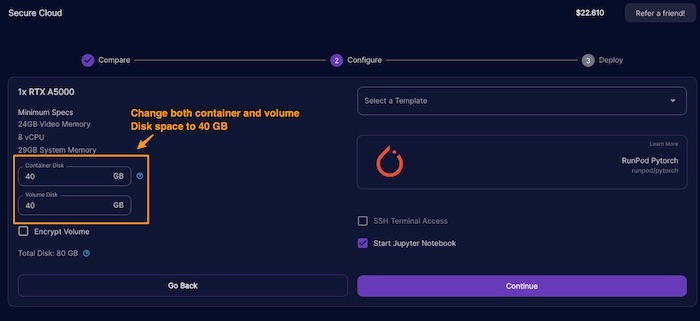
Qual Dreambooth-Stable-Diffusion?
Existem centenas de forks no Dreambooth-Stable-Diffusion original do Google. No entanto, o vídeo “Aitrepreneur” aponta que o ramo Joe Penna da Dreambooth-Stable-Diffusion contém notebooks jupyter especiais projetados para ajudar a treinar sua incorporação pessoal. Tem o notebook projetado para rodar no Google Colab ou no RunPod.io. Isso nos permite treinar um modelo de hiper-rede que funcionará com o Stable Diffusion. O objetivo é criar um modelo de ponto de verificação que possa ser usado como imagens de perfil pessoal com base em prompts de texto.
Processo de treinamento
Agora, para o principal dos detalhes do treinamento, treinar uma hiper-rede é o processo para gerar uma incorporação personalizada para o software Stable Diffusion; que cria uma incorporação que pode ser usada para gerar imagens em seu próprio estilo. Isso levará algum tempo para o Stable Diffusion treinar e, uma vez concluído, você receberá uma incorporação personalizada. Você pode treinar com quantos objetos e estilos únicos quiser.
O treinamento com o Dreambooth requer apenas uma quantidade limitada de dados de treinamento. Por exemplo: 20 imagens são suficientes para criar uma incorporação e os dados não precisam ser de alta qualidade. Ainda funcionará bem com imagens mal iluminadas ou incompletas. O tempo de treinamento é normalmente de cerca de uma hora em uma RTX3090 com 24G de RAM de GPU.
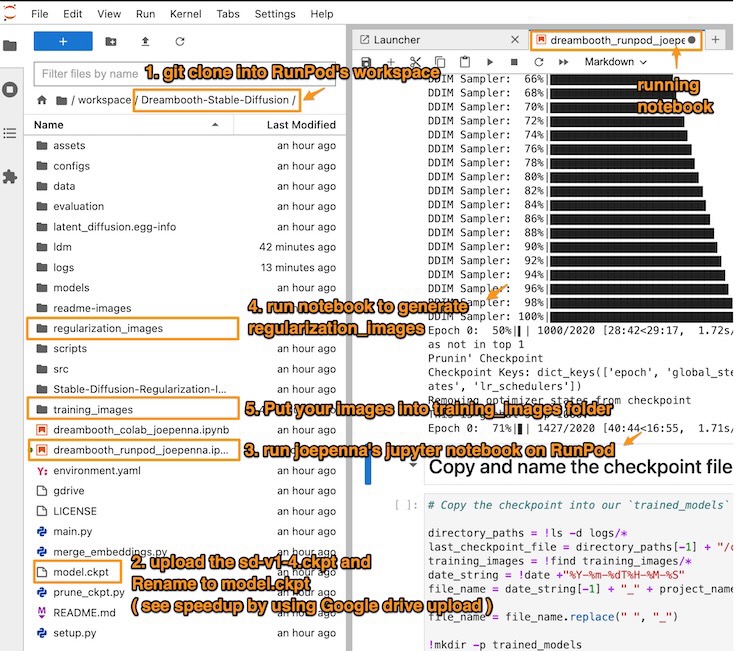
Figura: mostra a referência às etapas para executar com sucesso o notebook de treinamento no RunPod.io. Para cada descrição da etapa de treinamento, podemos voltar a esta imagem para referência.
O notebook Jupyter é um programa de execução de código baseado na Web que pode ser usado para escrever e executar código de forma interativa. Esse programa possibilita a execução de scripts Python e outras linguagens de programação em uma janela do navegador. Existem muitos módulos úteis disponíveis que podem ser usados para executar várias tarefas, como criar gráficos ou visualizações.
1. Clone o Repositório com o Git no Espaço de Trabalho do RunPod
Dentro de um novo notebook Jupyter, execute este comando git para clonar o repositório de código no espaço de trabalho do Pod.
Para reiterar, o ramo Joe Penna do Dreambooth-Stable-Diffusion contém notebooks Jupyter projetados para ajudar a treinar sua incorporação pessoal. Pode ser executado no RunPod.io.
!git clone https://github.com/JoePenna/Dreambooth-Stable-Diffusion/
2. Faça o Upload do sd-v1-4.ckpt no Espaço de Trabalho do Pod
Para acelerar a velocidade de upload do modelo Stable Diffusion (muito lento para usar diretamente o upload do RunPod), recomendamos o uso do Google Drive. No notebook, faça esta instalação:
%pip install gdown
Em seguida, use gdown para fazer o download do link do Google Drive para o arquivo. Para encontrar o link para o seu arquivo de ponto de verificação de hugging-face, você precisa encontrar o ID do link compartilhado do Google Drive.
!gdown https://drive.google.com/uc?id=<link_to_file_location_id>
3. Execute o Notebook no Pod
Após a clonagem, devemos encerrar o notebook de download e mudar para usar o repositório Dreambooth-Stable_Diffusion no espaço de trabalho do Pod,
- usar o notebook
Dreambooth_runpod_joepenna.ipynb.
Nota importante!!! A partir de [09/01/2023], o notebook Jupyter do RunPod.io do JeoPenna está com algum módulo Python faltando para ser executado com sucesso. Por favor, adicione o seguinte na célula
BUILD DEVque está fazendopip installcom os seguintes módulos em falta:
!pip install taming-transformers-rom1504
!pip install clip
4. Execute a Célula do Notebook para Gerar Imagens de Regularização
Em vez de gerar um conjunto de imagens de regularização, podemos pular para a célula do notebook para executar “Baixar imagens de regularização pré-geradas” (Download pre-generated regularization images).
As imagens de regularização são um tipo de dados que ajuda as redes neurais a detectar padrões e melhorar sua precisão. As imagens de regularização podem ser criadas pegando um conjunto de pontos de dados (como pixels ou imagens vetoriais) e modificando-os aleatoriamente para adicionar ruído. Essas imagens são usadas durante o treinamento para evitar o overfitting, que é onde uma rede neural começa a ver padrões que não existem nos dados. O overfitting pode fazer com que uma rede neural se torne excessivamente precisa em um conjunto de treinamento específico, sem poder usar seu conhecimento para fazer previsões precisas sobre novos dados.
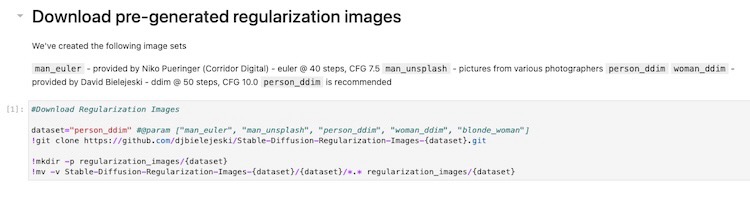
Figura: mostrando a célula do notebook que baixa as imagens de regularização para a classe em questão.
Depois de executar a célula do notebook, ela buscará 1.500 dessas imagens de regularização e as colocará na pasta ./regularization_images para a próxima etapa de treinamento.
5. Coloque Suas Imagens na Pasta de Imagens de Treinamento
Nota Importante!!! O treinamento espera imagens em PNG, portanto, certifique-se de que as imagens do treinamento estejam no formato PNG!
Para treinar sua incorporação, você precisará de um conjunto de imagens. As imagens devem estar no formato PNG e as dimensões devem ser de 512 x 512 pixels. Você também deve incluir uma descrição de texto para as imagens para que o modelo possa aprender com elas. As imagens devem ser claras e bem iluminadas, e deve haver variedade suficiente nas imagens para fornecer ao modelo informações suficientes para trabalhar.
A célula dos notebooks exige que coloquemos cada arquivo como uma localização URL. Mas, na verdade, depois que a célula baixar as imagens das localizações URL, essas imagens são armazenadas na pasta ./training_images. Em outras palavras, podemos colocar diretamente o conjunto de imagens de treinamento na pasta ./training_images, sem ter de passar por todo o processo de fazer upload para um serviço na nuvem.
Não precisamos executar a célula de notebook a seguir. Ela está usando uma lista de URLs, que são inseridos manualmente, para baixar as imagens da Web.
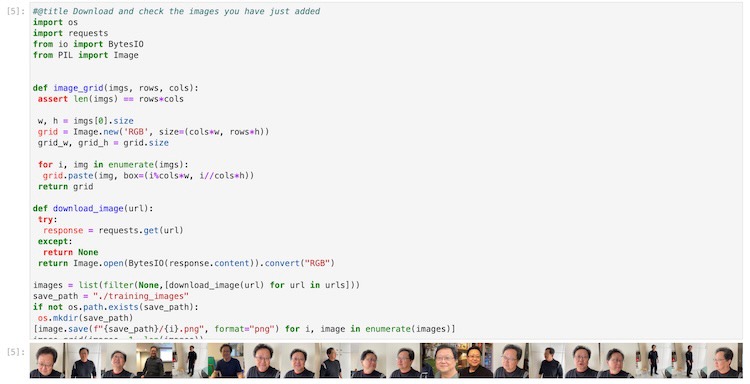
Figura: a célula do notebook exibida que está passando pela lista de URLs e baixando as imagens na pasta “./training_images”. Uma vez que entendermos esta célula, podemos colocar as imagens de treinamento diretamente na pasta “./training_image”. Isso é bom para vermos as imagens que serão usadas no treinamento como a saída da execução da célula.
6. Treinando o modelo
Nota Importante!!! Isso é necessário para o Dreambooth, certifique-se de renomear o arquivo
sd-v1-4.ckptparamodel.ckpt.
Depois de toda a configuração de instalação, o upload das imagens de regularização e treinamento está pronto. Estamos quase prontos para iniciar o treinamento após as seguintes edições na célula de treinamento do notebook.
- Defina um nome de projeto, por exemplo,
bennycheung, que será usado no nome do arquivo do modelo de ponto de verificação. - Defina um token exclusivo, por exemplo,
bennycheunge uma palavra de classeperson. É importante lembrar que a combinação de “classe de token”, por exemplo, “pessoa bennycheung”, será usada para acionar a incorporação personalizada na hiper-rede. - Defina o número de
max_training_steps, devemos ter 100 etapas por imagem de treinamento, neste caso, estamos usando 30 imagens de treinamento - isso significa que precisamos de 3000 etapas.
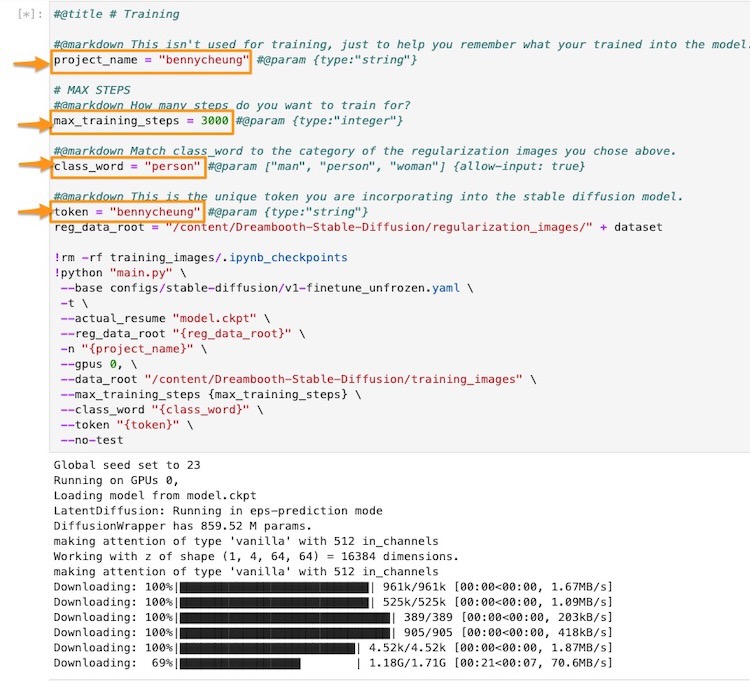
Figura: célula de treinamento do notebook ilustrada. Precisamos fazer as modificações nos parâmetros destacados, que são descritos nesta seção.
Em seguida, leve cerca de 80 minutos para treinar 3.000 etapas.
Quando o treinamento for concluído, execute a célula para copiar o modelo de ponto de verificação final para a pasta ./trained_models. Em seguida, você pode baixar o modelo final de ponto de verificação a ser usado. O arquivo é nomeado com todos os detalhes do treinamento.
2022-11-10T00-46-29_bennycheung_30_training_images_3000_max_training_steps_bennycheung_token_person_class_word.ckpt
Recomendamos renomeá-lo para um nome mais curto, por exemplo, bennycheung-v1-3000.ckpt.
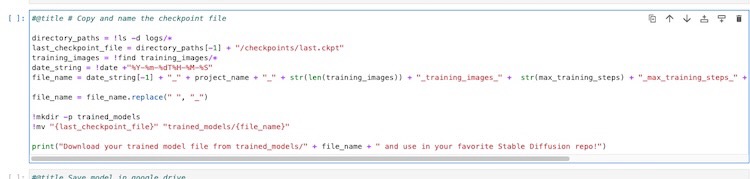
Figura: a célula do notebook ilustrada que salva o último modelo de ponto de verificação na pasta “modelos_treinados” (trained_models).
Uso do modelo
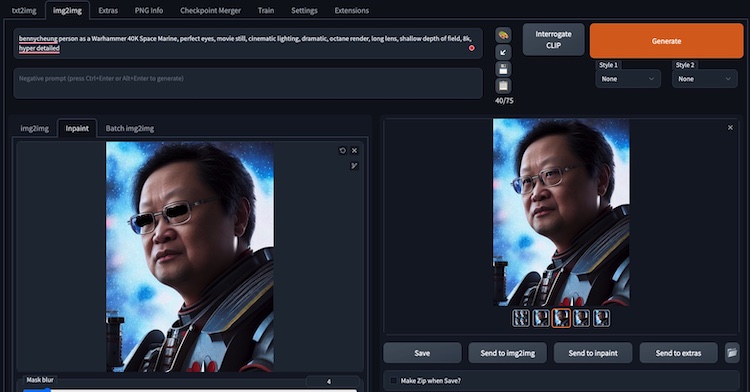
A maneira de usar sua incorporação é através dos pares padrão de <token> <class>, por exemplo - o modelo treinado ilustrado é bennycheung person e não apenas bennycheung.
bennycheung person as a Warhammer 40K Space Marine, movie still,
cinematic lighting, dramatic, octane render, long lens,
shallow depth of field, 8k, hyper detailed
bennycheung personcom essa combinação, acionará a incorporação para influenciar os resultados da imagem.
Aqui estão alguns exemplos de resultados, uma incorporação muito precisa e de alta fidelidade nas imagens geradas de acordo com o prompt de texto.

Figura: o sonho de se visualizar como o Astartes de Warhammer de 40k finalmente se torna realidade!
Muitas pessoas podem pensar que a parte mais importante da arte da IA é a própria IA. Mas a qualidade da arte gerada também pode depender muito do prompt de texto fornecido à IA, pois esse prompt de texto influenciará fortemente as escolhas da IA ao criar uma nova arte. O OpenArts é um dos principais especialistas neste campo e eles lançaram um incrível livro em PDF sobre o Stable Diffusion Prompt Book, explicando como melhorar a precisão do prompt de texto. Isso melhorará a precisão do prompt de texto ao criar arte de IA, o que leva a uma arte melhor e mais precisa!
Sobre a criatividade da IA
No que diz respeito ao debate sobre se uma IA está realmente sendo criativa ou não, um indivíduo pode argumentar que está simplesmente combinando ideias e arte existentes para criar algo novo. Essa é uma afirmação compreensível. No entanto, o mesmo poderia ser dito em relação à criatividade humana. Há uma diferença entre copiar e criar algo novo, uma vez que os próprios artistas humanos aprendem com outros estilos de arte para criar algo único. Isso significa que a criatividade humana não é real?
Indiscutivelmente, a IA não está simplesmente recriando obras existentes, mas explorando novas possibilidades e estilos de arte. No caso específico do Stable Diffusion, ele cria novas artes e estilos diferentes do que seria feito por um humano, de uma forma única e interessante. A tecnologia é capaz de fazer novas conexões entre o conhecimento existente para encontrar mais variações e formas eficazes de combinação, o que permite estilos de arte mais exclusivos. Também pode buscar abordagens e estratégias incomuns para criar uma arte mais interessante e surpreendente, de maneiras que os humanos são limitados.
Com uma perspectiva mais positiva, os avanços na IA estão progredindo muito rapidamente. As redes neurais, cada vez maiores e mais eficientes, com ligações neurais maiores, são capazes de estabelecer conexões entre diferentes ideias e memórias. Esse nível de simulação é o que as redes neurais estão tentando recriar. À medida que essa capacidade é simulada diversas vezes, ela permite que uma IA seja criativa, pois pode fazer conexões mais complexas entre diferentes ideias, memórias e estilos de arte, bem como criar novas ideias a partir das existentes.
Galeria de obras de arte de modelos personalizados
A galeria a seguir mostra as variações criativas produzidas pelo Stable Diffusion. O nível de profundidade e criatividade é evidente, e você pode apreciar como as ligações neurais foram criadas para criar novos estilos de arte. Este artista de IA é realmente muito talentoso para ser capaz de gerar tantas variações a partir do prompt fornecido!
bennycheung person, anime, warhammer 40k, space marine, meditative look,
trending on artstation, watercolor pen by brad mesina, greg rutkowski
- usando vários Sampler e escala CFG, Seed: 769704955

Figura: esses trabalhos criativos de IA ilustram as inúmeras variedades e estilos criados por meio do modelo treinado personalizado. O Stable Diffusion é capaz de produzir uma variedade de imagens a partir de um prompt singular, cada trabalho sendo único em estilo e detalhes.
Esta IA realmente aproveitou a criatividade. Embora a obra de arte mostrada tenha sido criada com o uso de IA, ela não deixa de ser um produto da criatividade. Há muitas coisas com as quais a IA foi programada, mas é a rede neural que pode combiná-las e criar um produto ou conceito original. Ela tem a capacidade de usar memórias novas e existentes para criar arte verdadeiramente bela.
Sobre correções na geração de imagem
Consertando os Olhos
O Stable Diffusion é ruim para gerar os olhos com precisão. Felizmente, podemos usar o recurso interno de Inpainting img2img para corrigir os olhos estranhos na imagem gerada.
Por exemplo, os meus globos oculares estão desproporcionais e parecem retorcidos. Vamos mostrar como corrigir.
Podemos enviar a imagem para o recurso da subguia Inpaint da guia img2img (Imagem para imagem).
- Devemos manter um prompt semelhante ao da imagem de origem.
- O tamanho da imagem deve ser exatamente igual ao da imagem original.
- Utilize a ferramenta caneta (que pode ser redimensionada) para pintar (escurecer) a parte da imagem que queremos regenerar. Nesse caso, queremos pintar os olhos em que desejamos usar o
Inpaintpara substituir esses pixels. - Normalmente, geramos mais algumas imagens, dependendo da sorte (puro acaso), o algoritmo produzirá os olhos perfeitos que gostamos. Então, podemos manter essa imagem. Para os outros pixels, que não são pintados, eles devem permanecer os mesmos - nenhum pixel é regenerado.
Os olhos são melhorados a um nível satisfatório. É isso que escolhemos. As imagens mostram o antes e o depois da operação de correção dos olhos com Inpaint.

Figura: mostrando que os olhos são “pintados” para gerar olhos mais equilibrados e realistas de mim mesmo, eu sei.
Consertando as Mãos
Outra fraqueza da geração de imagem do Stable Diffusion, dependendo da sorte, as mãos também ficarão confusas. Podemos aplicar a técnica Inpaint semelhante para regenerar as mãos, com o prompt “corrigir mãos” para enfatizar ao algoritmo que preste atenção à geração de “mãos corretas”.
Observações Finais
Atualmente, estamos testemunhando um grande avanço na arte e na tecnologia, uma IA agora é capaz de entender e imitar a arte humana, além de criar seus próprios estilos artísticos! Este é o melhor dos dois mundos, pois a criatividade humana pode ser combinada com a precisão da máquina para produzir obras de arte verdadeiramente belas. Isso tudo é feito com o uso da técnica Dreambooth para treinar uma hiper-rede para fazer os melhores estilos artísticos com a incorporação pessoal.
Para este artigo, o custo total de treinamento no RunPod.io é de - $ 0,608, o que é um ótimo negócio para toda a diversão!!
Referências
- Aitrepreneur, Dreambooth: Train Stable Diffusion With Your Images Using Google’s AI!, vídeo do Youtube, outubro de 2022
- Ótimo tutorial, passo a passo do processo de treinamento usando RunPod.io com o repositório do Dreambooth-Stable-Diffusion Jupyter notebook.
Publicações formais
- Robin Rombach, et. al., High-Resolution Image Synthesis with Latent Diffusion Models, arXiv:2112.10752v2 cs.CV, 13 de abril de 2022.
- Nataniel Ruiz, et. al., DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation, arXiv:2208.12242v1 cs.CV, 25 de agosto de 2022, Pesquisa no Google.
- Postagem on-line do blog DreamBooth.
Outras postagem de blog relacionadas
- Suraj Patil, Training Stable Diffusion with Dreambooth, Weights & Biases, outubro de 2022.
- Uma análise de seus experimentos para treinar o Stable Diffusion com Dreambooth, grandes detalhes e explicação técnica dos parâmetros de treinamento.
- OpenArts, Stable Diffusion Prompt Book, outubro de 2022.
- Baixar PDF;
- O recém-lançado livro de prompts do Stable Diffusion da OpenArts, onde eles reúnem dicas e truques de prompts.
Ferramentas de suporte
- Brinque com o Lexica para ver muitos exemplos de prompts que geram belas artes do Stable Diffusion.
- Use o Birme para redimensionar a coleção de imagens.
- O processo de treinamento espera que as imagens fornecidas sejam de dimensão 512x512. Se suas imagens tiverem um tamanho diferente, você pode usar este site para ajustar e redimensionar as imagens para que correspondam aos requisitos adequados para a leitura da rede neural.
Esse artigo foi escrito por Benny Cheung e traduzido por Isabela Curado Nehme. Seu original pode ser lido aqui.