
A IA (inteligência artificial) generativa está avançando a uma velocidade sem precedentes nas últimas semanas - com diferentes versões de LLM (large language models ou modelos de linguagem grande) semelhantes ao GPT e a Stable Diffusion (Difusão Estável) XL de geração de imagens liderando o movimento. Algumas pessoas afirmam que esses modelos de IA podem tirar o trabalho de escritores, ilustradores e artistas, enquanto outros estão aproveitando essas tecnologias de IA para aumentar sua produtividade na criação de conteúdo de imagem ou texto.
Não importa de que lado você esteja, acredito que entender melhor como as IAs funcionam, além de vê-las como uma caixa preta mágica, pode nos ajudar a tomar decisões mais informadas - seja para amenizar seu medo de que elas possam tirar seus empregos ou aprofundar sua compreensão e tirar o máximo proveito delas em seu fluxo de trabalho.
 ######Caixa preta mágica. Imagem gerada pela Stable Diffusion.
######Caixa preta mágica. Imagem gerada pela Stable Diffusion.
Neste artigo, eu tentarei explicar o modelo de geração de imagem da Stable Diffusion em termos simples para meus leitores não técnicos - designers, gerentes de produto, empresários ou qualquer pessoa interessada no funcionamento interno de como as imagens são geradas. Ao final, você terá uma sólida compreensão da história desse modelo de geração de imagens, de como ele pode gerar imagens e de técnicas para melhorar a qualidade das imagens geradas.
(Se você também estiver interessado em saber como funcionam os modelos de linguagem grande, como o que está por trás do ChatGPT, leia este artigo: Como o ChatGPT realmente funciona, explicado para pessoas não técnicas)
O que é a Stable Diffusion e por que é popular?
A Stable Diffusion é uma série de modelos de geração de imagens da StabilityAI, CompVis e da RunwayML, lançada inicialmente em 2022 [1]. Sua principal capacidade é gerar imagens estéticas e detalhadas com base em entradas de texto, mas também pode realizar outras tarefas, como pintura interna (preenchimento de partes ausentes), pintura externa (ampliação de imagens) e geração de imagem para imagem.
Além de sua capacidade de gerar imagens altamente detalhadas, a popularidade da Stable Diffusion vem de sua natureza de código aberto, sua facilidade de uso e sua capacidade de ser executada em placas gráficas de nível de consumidor. Isso está, de certa forma, democratizando a geração de imagens e permite que qualquer pessoa interessada experimente e acrescente combustível à sua evolução.
Antes de nos aprofundarmos na arquitetura e no mecanismo da Stable Diffusion, vamos examinar rapidamente a história da geração de imagens e pela evolução da Stable Diffusion.
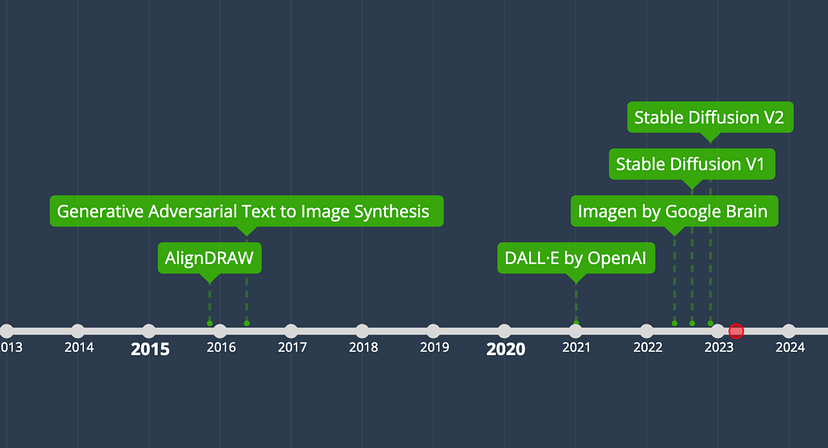 ######Linha do tempo de geração de imagem. Ilustração do autor.
######Linha do tempo de geração de imagem. Ilustração do autor.
- 2015: alignDRAW. Um modelo de texto para imagem da Universidade de Toronto [2]. Esse modelo só pode gerar imagens borradas, mas mostrou a possibilidade de gerar imagens “não vistas” pelo modelo a partir de entrada de texto.
- Reed, Scott e outros, propuseram uma abordagem usando redes adversárias generativas (GANs, um tipo de arquitetura de rede neural) para gerar imagens. Elas geraram com sucesso imagens razoáveis de pássaros e flores a partir de descrições de texto detalhadas [3]. Após esse trabalho, foi desenvolvida uma série de modelos baseados em GANs.
- A OpenAI lançou o DALL-E, que é baseado na arquitetura de transformador (outro tipo de arquitetura de rede neural) e chamou a atenção do público [4].
- O Google Brain lançou o Imagen para competir com o DALL-E da OpenAI [5].
- A Stable Diffusion foi anunciada como uma melhoria dos modelos de difusão no espaço latente. Devido à sua natureza de código aberto, muitas variações e modelos ajustados com base nele foram criados e despertaram ampla atenção e aplicações generalizadas.
- Muitos novos modelos e aplicativos surgiram, indo além do texto para imagem (text-to-image), estendendo-se ao texto para vídeo (text-to-video) ou texto para 3D (text-to-3D).
Como podemos ver na linha do tempo, a conversão de texto em imagem é, na verdade, um campo bastante jovem. O surgimento da Stable Diffusion é, na verdade, um marco importante e promoveu o crescimento exponencial desse campo como um modelo de código aberto que requer significativamente menos recursos do que os modelos anteriores.
Então, como a Stable Diffusion gera imagens a partir do texto? Vamos nos aprofundar no modelo e desmistificar o processo de treinamento e geração.
Componentes da Stable Diffusion
A Stable Diffusion não é um modelo simples de IA. É um processo que combina diferentes redes neurais. Podemos dividir todo o processo de geração de texto para imagem com a Stable Diffusion em diferentes etapas e explicá-las uma a uma.
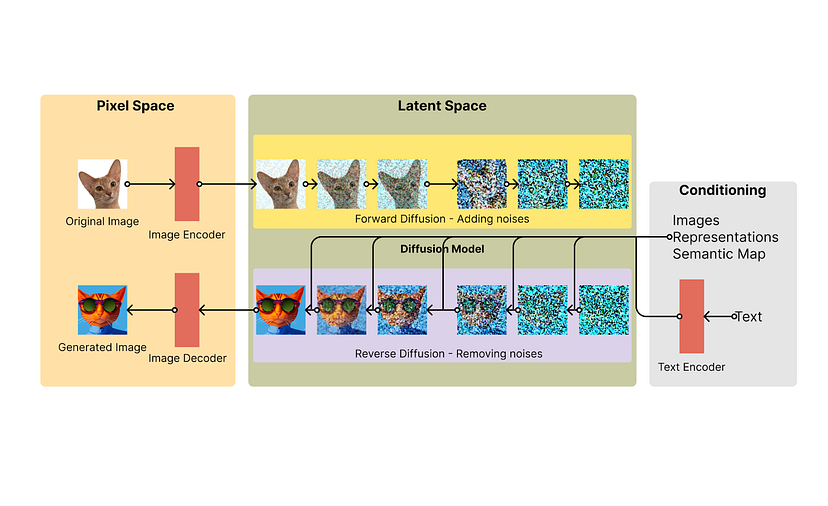 ######Componentes da Stable Diffusion. Simplificado e adaptado de [1]
######Componentes da Stable Diffusion. Simplificado e adaptado de [1]
Vamos começar com uma visão geral do processo de geração de texto para imagem [1].
- Codificador de imagem. Tradução de imagens de treinamento em vetores em um espaço latente para processamento posterior. O espaço latente é um espaço matemático onde as informações da imagem podem ser representadas como vetores (ou seja, matrizes de números)
- Codificador de texto. Tradução de texto em vetores de alta dimensão (você pode pensar neles como matrizes de números que representam o significado dos textos) que os modelos de aprendizado de máquina podem entender.
- Modelo de difusão. Geração de novas imagens no espaço latente, condicionada pela orientação do texto (ou seja, o texto de entrada orienta a geração de imagens neste espaço latente)
- Decodificador de imagem. Traduzir a informação da imagem no espaço latente para uma imagem real construída com pixels.
Cada uma das etapas é realizada com suas próprias redes neurais. Nas próximas seções, vamos nos aprofundar em cada uma das etapas e ver como a Stable Diffusion é treinada para gerar imagens.
O codificador de texto converte a entrada de texto em embeddings
Imagine que você quer que um artista estrangeiro desenhe uma pintura para você, mas você não fala a língua dele, provavelmente usará o Google Tradutor ou um tradutor humano para traduzir o que deseja. O mesmo acontece com os modelos de geração de imagens — os modelos de aprendizado de máquina não entendem o texto diretamente, então eles precisam de um codificador de texto para traduzir suas instruções de texto em números que possam entender. Esses números não são apenas números aleatórios — eles são chamados de text embeddings, que são vetores de alta dimensão que podem capturar o significado semântico dos textos (ou seja, a relação entre as palavras e seu contexto).
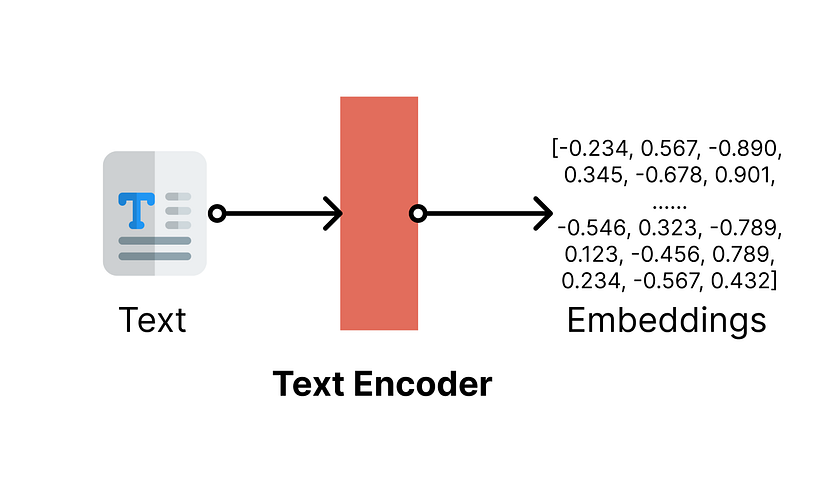 ######O codificador de texto converte o texto em embeddings vetoriais de alta dimensão. Ilustração feita com ícones do https://www.flaticon.com/
######O codificador de texto converte o texto em embeddings vetoriais de alta dimensão. Ilustração feita com ícones do https://www.flaticon.com/
Pode haver muitas maneiras de traduzir texto em embeddings. A Stable Diffusion usa um modelo de linguagem grande transformador para concluir a tarefa. Se você estiver familiarizado com modelos de linguagem, o termo transformador pode soar familiar para você — é a arquitetura subjacente do GPT. Na verdade, a Stable Diffusion v1 usa o CLIP, que é um modelo com base no GPT da OpenAI. (O artigo de pesquisa original sobre Stable Diffusion usa o BERT, outro modelo de transformador; a Stable Diffusion V2 usa o OpenClip, uma versão maior do CLIP) [1] [6].
Esses modelos de codificadores são treinados em grandes conjuntos de dados de bilhões de pares de texto e imagem para aprenderem os significados das palavras e frases que usamos para descrever as imagens. O conjunto de dados vem das imagens na web com as tags de imagem (alt tags) que usamos para descrevê-las.
Essa etapa é crucial no modelo de texto para imagem, pois os pesquisadores descobriram que modelos de linguagem maiores podem melhorar muito a qualidade das imagens geradas, ainda mais do que modelos de difusão de imagens maiores [5]. Isso é compreensível - se o artista não consegue nem entender o que você quer, como esperar uma pintura de alta qualidade dele, certo? (Claro, se você não está tentando gerar uma imagem com base em texto, esta etapa é opcional — você pode usar outras orientações como imagens ou nenhuma orientação, deixando que ele desenhe uma imagem aleatória.)
O modelo de difusão pinta a imagem por meio da difusão
O modelo de difusão é o componente central da Stable Diffusion. É o componente que sintetiza uma imagem. Para treinar um modelo de difusão, há dois processos: um processo de difusão direta para preparar amostras de treinamento e um processo de difusão reversa para gerar as imagens. Esses dois processos são feitos no espaço latente na Stable Diffusion para maior velocidade.
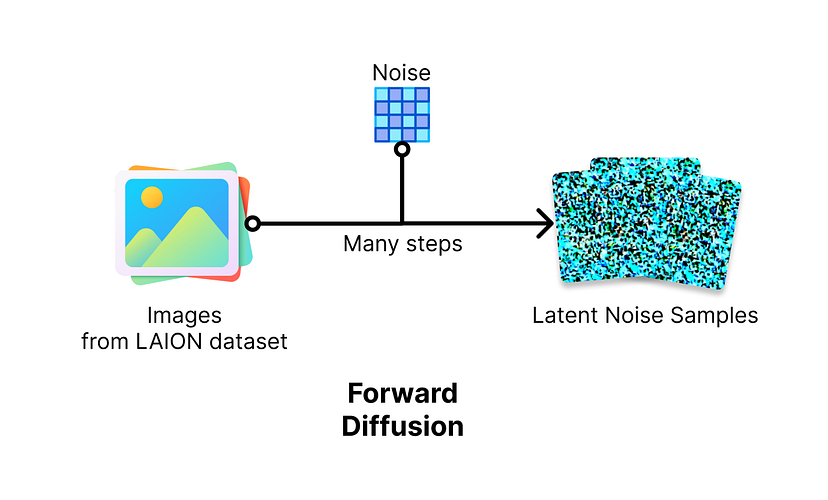 ######A difusão direta gradualmente adiciona ruído às imagens. Ilustração feita com ícones do https://www.flaticon.com/
######A difusão direta gradualmente adiciona ruído às imagens. Ilustração feita com ícones do https://www.flaticon.com/
No processo de difusão direta, o modelo adiciona gradualmente ruído gaussiano à imagem para transformar uma imagem clara em uma imagem com ruídos. A cada etapa, uma pequena quantidade de ruído é adicionada à imagem, repetida em várias etapas [1] [7]. Como o nome “difusão” sugere, esse processo é como deixar cair uma gota de tinta na água – a gota de tinta se difunde gradualmente na água, até que você não consiga mais ver que antes era uma gota de tinta. Os padrões de ruído adicionados nas imagens são aleatórios, assim como as partículas de tinta se difundem aleatoriamente nas partículas de água, mas a quantidade de ruído pode ser controlada. Esse processo é feito em muitas imagens do conjunto de dados LAION com diferentes quantidades de ruído adicionadas para criar muitas amostras com ruído para treinar o modelo de difusão reversa.
No processo de difusão reversa, um detector de ruído é treinado para prever o ruído adicionado à imagem original, de modo que o modelo possa remover o ruído previsto da imagem com ruído para obter uma imagem mais nítida (no espaço latente). Você pode pensar nesse processo como olhar para uma gota de tinta parcialmente difusa na água e tentar prever o local em que ela caiu antes.
O detector de ruído é um U-Net baseado em um backbone ResNet (um tipo de arquitetura de rede neural). Ele é treinado no conjunto de dados de treinamento preparado anteriormente por difusão direta e seu objetivo é estimar o ruído para que a imagem sem ruído fique o mais próximo possível da imagem original. Uma vez treinado, ele “lembrará” as representações da imagem em seus pesos e poderá ser usado para “gerar” imagens a partir de um tensor de imagem com ruído inicial aleatório. A imagem real e a qualidade da imagem dependem muito do conjunto de dados da imagem original porque ele está tentando voltar às imagens originais. Esse processo de difusão reversa é feito gradualmente por meio de várias etapas para remover o ruído. Quanto mais etapas de remoção de ruído forem executadas, mais clara a imagem se tornará.
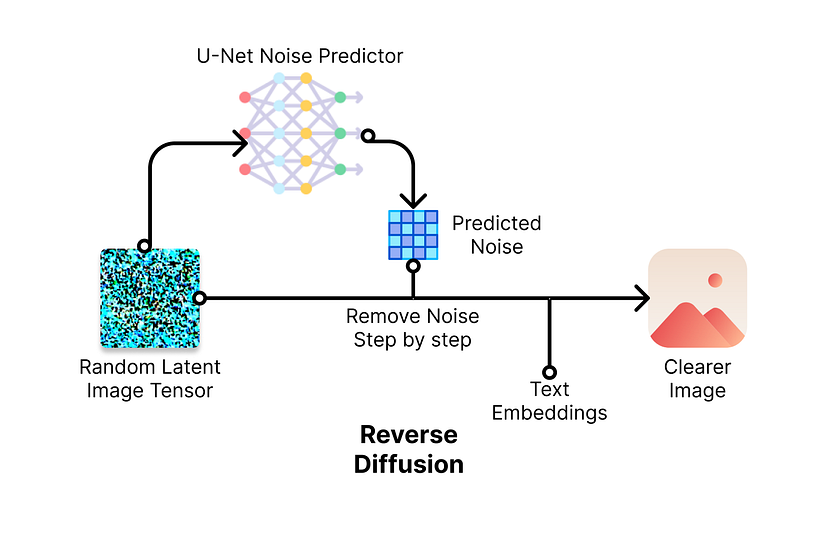 ######A difusão reversa remove gradualmente o ruído, condicionado pela orientação do texto, para criar uma imagem mais nítida. Ilustração feita com ícones do https://www.flaticon.com/
######A difusão reversa remove gradualmente o ruído, condicionado pela orientação do texto, para criar uma imagem mais nítida. Ilustração feita com ícones do https://www.flaticon.com/
Durante esse processo de difusão reversa para obter uma imagem mais nítida, os pesquisadores queriam controlar a aparência da imagem por meio de um processo chamado condicionamento. Se estivermos usando texto, isso é chamado de condicionamento de texto. Ele funciona passando os embeddings de texto da etapa de codificação de texto para a U-Net por meio de um mecanismo de atenção cruzada. O mecanismo de atenção cruzada basicamente mescla os embeddings de texto com os resultados de cada etapa da difusão reversa. Por exemplo, se você tiver um prompt de entrada “gato”, pode pensar no condicionamento como dizendo ao detector de ruído: “Para a próxima etapa de redução de ruído, a imagem deve se parecer mais com um gato. Agora vá para o próximo passo.” O condicionamento também pode ser feito com outras orientações além do texto, como imagens, mapas semânticos, representações, etc.
O decodificador de imagem traduz a imagem do espaço latente para pixels
Como a difusão e o condicionamento que fizemos estão no espaço latente, não podemos ver as imagens geradas diretamente. Precisamos converter a imagem latente de volta em pixels que possamos ver. Essa tradução é feita por meio de um decodificador de imagem.
Este tradutor na Stable Diffusion é um autoencoder variacional (VAE). No processo anterior de difusão direta, usamos a parte do codificador do VAE para traduzir as imagens de treinamento originais dos pixels para o espaço latente para adicionar ruídos. E agora, usamos a parte do decodificador do VAE para traduzir as imagens latentes de volta para os pixels.
A razão pela qual a Stable Diffusion faz todo o processamento, difusão e condicionamento no espaço latente em vez do espaço de pixel, é que o espaço latente é menor. Podemos fazer esse processo muito mais rápido sem consumir uma grande quantidade de recursos computacionais.
Técnicas para melhorar os resultados da Stable Diffusion
Até agora, você deve ter uma noção melhor de como o processo de treinamento é feito na difusão direta e como ele gera uma imagem baseada em sua entrada de texto no processo de difusão reversa. Mas acho que isso é só o começo, a parte mais curiosa é como podemos adaptar o processo para produzir imagens de maior qualidade com base no que queremos. Pesquisadores e entusiastas criaram muitas técnicas diferentes para melhorar os resultados da Stable Diffusion. Deixe-me examiná-los rapidamente para que você possa escolher a técnica mais adequada para seu produto ou projeto.
A maioria desses métodos funciona por meio da extensão de um modelo de Stable Diffusion treinado. Um modelo treinado significa que ele já viu e aprendeu a gerar imagens com seus pesos de modelo (números que instruem como o modelo deve funcionar).
Outro grupo de técnicas funciona na parte do codificador de texto da Stable Diffusion, incluindo a inversão textual e o DreamArtist. A inversão textual funciona aprendendo uma nova incorporação de palavra-chave para cada novo conceito ou estilo que você deseja gerar [8]. Você pode pensar na inversão textual como se dissesse ao tradutor “Lembre-se que este novo objeto se chama 'gato-cachorro' e da próxima vez que eu disser 'gato-cachorro', você deve dizer ao artista para desenhar este objeto”. O DreamArtist trabalha aprendendo palavras-chave positivas e negativas para descrever uma imagem de referência [9]. É como se dissesse ao tradutor “Aqui está uma imagem, lembre-se de como ela se parece e chame-a do que achar melhor para descrevê-la”.
Outro grupo de técnicas trabalha principalmente no U-Net, o componente de geração de imagens, incluindo o DreamBooth, o LoRA e a Hypernetworks. O DreamBooth ajusta o modelo de difusão com um conjunto de dados de novas imagens até entender o novo conceito [10]. O LoRA funciona adicionando um pequeno conjunto de pesos adicionais sobre o modelo de difusão no modelo de atenção cruzada e treinando apenas esses pesos adicionais [11]. As Hypernetworks usam uma rede secundária para prever novos pesos e sequestrar a parte de atenção cruzada no detector de ruído para inserir novos estilos [12]. Esses métodos estão basicamente dizendo ao artista para aprender algumas novas pinturas, seja por si só (DreamBooth), ajustando os estilos existentes (LoRA) ou com alguma ajuda externa (Hypernetworks). O DreamBooth é eficaz, mas requer mais armazenamento, enquanto o LoRA e a Hypernetworks são relativamente mais rápidos de treinar porque não precisam treinar um modelo de Stable Diffusion inteiro.
A comunidade de código aberto é simplesmente incrível, pois continuam apresentando novas ideias, eficientes e melhores para melhorar a Stable Diffusion. Eles também estão experimentando modelos de texto para vídeo ou texto para 3D. Esta é a era da explosão da IA generativa e minha lista aqui não está completa.
Aprendizado
Neste artigo, tentei explicar como funciona a Stable Diffusion com termos simples. Aqui estão alguns aprendizados rápidos:
- Stable Diffusion é um modelo de geração de imagem que gera principalmente imagens a partir de texto (texto condicionado), mas também pode gerar imagens com outras instruções como imagens/representações.
- O processo de treinamento da Stable Diffusion envolve a adição gradual de ruídos às imagens (difusão direta) e o treinamento de um detector de ruído para remover gradualmente os ruídos para gerar uma imagem mais nítida (difusão reversa).
- O processo de geração (difusão reversa) começa com uma imagem com ruído aleatória (tensor) no espaço latente e gradualmente se difunde em uma imagem nítida, condicionada por prompts.
- Há muitas técnicas para melhorar o resultado da Stable Diffusion, incluindo inversão textual e o DreamArtist na camada de incorporação o LoRA, DreamBooth e a Hypernetworks no modelo de difusão. E a lista de técnicas continua crescendo.
Espero que este artigo possa lhe dar uma melhor compreensão de como funciona a Stable Diffusion. Se você é um criador com medo de que a IA tire seu emprego, você se sente aliviado ou mais estressado depois de saber como funciona? Se você deseja usar essas IAs generativas como ferramentas de produtividade, está mais claro como usá-las para obter resultados de maior qualidade?
Referências e Leituras Adicionais
[1] “Síntese de imagens de alta resolução com modelos de difusão latente”. Computer Vision & Learning Group, https://ommer-lab.com/research/latent-diffusion-models/. Acessado em 3 de abril de 2023.
[2] Mansimov, Elman, et al. Gerando imagens a partir de legendas com atenção. arXiv, 29 de fevereiro de 2016. arXiv.org, https://doi.org/10.48550/arXiv.1511.02793.
[3] Reed, Scott, et al. “Texto contraditório generativo para síntese de imagem.” Conferência Internacional sobre Aprendizado de Máquina. PMLR, 2016.
[4] DALL·E: Criando imagens a partir de texto. https://openai.com/research/dall-e. Acessado em 3 de abril de 2023.
[5] Saharia, Chitwan, et al. Modelos fotorrealistas de difusão de texto para imagem com compreensão profunda da linguagem. arXiv, 23 de maio de 2022. arXiv.org, https://doi.org/10.48550/arXiv.2205.11487.
[6] Stability-AI/stablediffusion. GitHub, https://github.com/Stability-AI/stablediffusion.
[7] ALAMMAR, Jay. A Stable Diffusion ilustrada. https://jalammar.github.io/illustrated-stable-diffusion/. Acessado em 4 de abril de 2023.
[8] Inversão textual_. _https://huggingface.co/docs/diffusers/main/en/training/text_inversion. Acessado em 4 de abril de 2023.
[9] Dong, Ziyi, et al. DreamArtist: Rumo à Geração One-Shot Controlável de Text-to-Image via Contrastive Prompt-Tuning. arXiv, 16 de março de 2023. arXiv.org, https://doi.org/10.48550/arXiv.2211.11337.
[10] Ruiz, Nataniel, et al. DreamBooth: Modelos de difusão de texto para imagem de ajuste fino para geração orientada por assunto. arXiv, 15 de março de 2023. arXiv.org, https://doi.org/10.48550/arXiv.2208.12242.
[11] cloneofsimo. "lora"; GitHub, 2023, https://github.com/cloneofsimo/lora. Acessado em 4 de abril de 2023.
[12] NovelAI. “Aprimoramentos da NovelAI na Stable Diffusion.” NovelAI Blog, 2022, https://blog.novelai.net/novelai-improvements-on-stable-diffusion-e10d38db82ac. Acessado em 4 de abril de 2023.
Artigo escrito por Guodong (Troy) Zhao e traduzido por Marcelo Panegali.