

Introdução
A classificação de imagens é uma das tarefas fundamentais em visão computacional, com aplicações que vão desde reconhecimento facial até diagnóstico médico baseado em imagens. Nos últimos anos, as Redes Neurais Convolucionais (Convolutional Neural Networks, ou CNNs) têm se mostrado extremamente eficazes para abordar esse desafio, alcançando resultados impressionantes em diversas áreas.
As CNNs são uma classe especial de redes neurais projetadas especificamente para o processamento de dados em formato de imagem. Ao contrário das redes neurais tradicionais, as CNNs exploram a estrutura espacial das imagens, levando em consideração a proximidade entre pixels e características locais, o que as torna especialmente adequadas para a análise de imagens.
As CNNs são inspiradas pelo córtex visual do cérebro humano e são projetadas para processar e reconhecer padrões em imagens de forma eficiente. Elas são compostas por várias camadas que aprendem automaticamente características hierárquicas das imagens durante o treinamento.
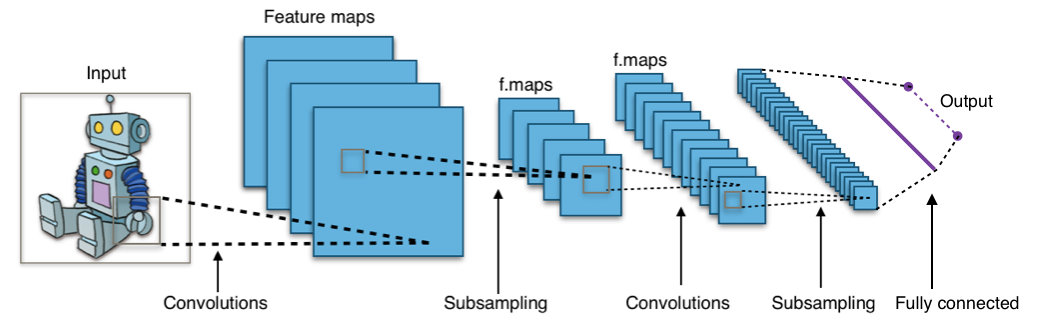
Uma CNN típica é composta por três tipos principais de camadas: camadas convolucionais, camadas de pooling (ou subamostragem) e camadas totalmente conectadas (ou densamente conectadas). Essas camadas trabalham em conjunto para extrair características relevantes da imagem e realizar a classificação.
Neste artigo, iremos explorar o uso de redes neurais convolucionais para a classificação de imagens. Vamos fornecer uma visão geral do funcionamento básico das CNNs, discutindo as principais camadas e conceitos envolvidos. Além disso, iremos realizar a implementação prática de uma CNN para classificar imagens utilizando Python, com exemplos de código para auxiliar na compreensão.
Antes de mergulharmos na implementação, abordaremos o pré-processamento de dados, incluindo redimensionamento, normalização e divisão em conjuntos de treinamento e teste. Em seguida, iremos detalhar a arquitetura de uma CNN, explicando a função das camadas convolucionais, camadas de pooling e camadas totalmente conectadas, bem como suas interações.
Durante a implementação em Python, iremos utilizar uma biblioteca popular, como TensorFlow ou PyTorch, para criar e treinar a CNN. Apresentaremos passo a passo o código necessário para construir o modelo, compilar, treinar e avaliar seu desempenho. Discutiremos a importância da função de perda, otimização e ajuste de hiperparâmetros para obter resultados satisfatórios.
Este artigo visa fornecer uma introdução prática às redes neurais convolucionais para classificação de imagens. Espero que, ao final da leitura, você tenha uma compreensão sólida sobre o funcionamento das CNNs e esteja pronto para aplicar esse conhecimento em suas próprias tarefas de classificação de imagens.
Visão Geral
Uma rede neural convolucional é uma arquitetura especializada em processamento de imagens que utiliza camadas convolucionais para extrair características relevantes das imagens e camadas totalmente conectadas para realizar a classificação. O funcionamento básico de uma CNN envolve uma sequência de etapas interligadas que permitem que a rede aprenda a reconhecer padrões e realizar a classificação correta.
A CNN recebe uma imagem como entrada e passa por uma série de camadas convolucionais. Essas camadas aplicam filtros convolucionais à imagem, deslizando-os sobre ela e calculando a soma ponderada dos valores dos pixels multiplicados pelos pesos do filtro. Isso gera mapas de características que representam diferentes aspectos da imagem, como bordas, texturas ou padrões.
Após a convolução, é aplicada uma função de ativação não linear, como a ReLU, para introduzir a não linearidade na rede. Isso permite que a CNN aprenda representações mais complexas e não lineares das imagens. Em seguida, as camadas de pooling reduzem a dimensionalidade dos mapas de características, preservando as informações mais relevantes enquanto diminuem o tamanho dos mapas.
Após as camadas convolucionais e de pooling, a CNN passa por camadas totalmente conectadas. Essas camadas transformam as características extraídas em uma saída que representa a probabilidade de cada classe de classificação. Cada neurônio nessas camadas está conectado a todos os neurônios da camada anterior, formando uma rede densamente conectada.
Por fim, a função de ativação final, geralmente a softmax, é aplicada à saída da última camada totalmente conectada para transformar os valores em probabilidades normalizadas. Isso permite que a CNN faça uma previsão da classe mais provável para a imagem de entrada.
Durante o treinamento, os pesos das camadas convolucionais e totalmente conectadas são ajustados iterativamente usando um algoritmo de otimização, como o gradiente descendente. A CNN é treinada em um conjunto de imagens rotuladas, onde a função de perda é utilizada para medir o quão bem a rede está realizando a classificação. O objetivo é minimizar a função de perda e melhorar o desempenho da CNN na tarefa de classificação de imagens.
No geral, as CNNs são poderosas ferramentas para o processamento de imagens e têm sido amplamente utilizadas em diversas aplicações, como reconhecimento facial, detecção de objetos e diagnóstico médico. Sua capacidade de aprender características diretamente das imagens, juntamente com sua estrutura hierárquica e compartilhamento de parâmetros, tornam as CNNs eficientes e eficazes para a tarefa de classificação de imagens.
Pré-processamento de Dados para Classificação de Imagens
O pré-processamento de dados desempenha um papel fundamental na construção de um modelo de Rede Neural Convolucional eficaz para classificação de imagens. Essa etapa envolve uma série de técnicas que visam preparar os dados brutos das imagens antes de alimentá-los ao modelo. Nesta seção, discutiremos as principais técnicas de pré-processamento de dados para classificação de imagens usando CNNs.
Redimensionamento de Imagens:
As imagens de um conjunto de dados podem ter tamanhos diferentes, porém as CNNs geralmente requerem que todas as imagens de entrada tenham o mesmo tamanho. Portanto, é necessário redimensionar as imagens para um tamanho padrão. Isso pode ser feito mantendo a proporção original das imagens ou ajustando-as para um formato específico, como quadrado. O redimensionamento das imagens ajuda a garantir que todas as amostras tenham dimensões consistentes para a entrada da CNN.
Normalização de Pixels:
A normalização é uma técnica importante para garantir que os valores dos pixels estejam na mesma escala. Isso é especialmente relevante quando se trabalha com diferentes canais de cores, como o caso das imagens RGB. A normalização pode ser realizada dividindo-se os valores dos pixels pelo valor máximo (por exemplo, 255 para imagens RGB), resultando em valores normalizados no intervalo de 0 a 1. Essa etapa é crucial para o bom desempenho do modelo, pois ajuda a evitar que alguns recursos tenham influência desproporcional no processo de aprendizado.
Aumento de Dados (Data Augmentation):
O aumento de dados é uma técnica poderosa para melhorar o desempenho e a capacidade de generalização de modelos de CNN. Essa técnica envolve a aplicação de transformações aleatórias nas imagens existentes, gerando novas amostras de treinamento. Essas transformações podem incluir rotações, espelhamentos horizontais ou verticais, zooms, deslocamentos e alterações de brilho. O aumento de dados ajuda a aumentar a quantidade de dados de treinamento disponíveis, reduzindo o risco de superajustamento (overfitting) e melhorando a capacidade do modelo de generalizar para novas imagens.
Conversão para Tensores:
As imagens são inicialmente representadas como matrizes de pixels, mas as CNNs geralmente esperam tensores como entrada. Portanto, é necessário converter as imagens para tensores antes de alimentá-las à CNN. Dependendo da biblioteca utilizada, isso pode ser realizado por meio de funções ou métodos específicos que convertem as imagens em tensores de ordem 3 (se as imagens forem em escala de cinza) ou de ordem 4 (se as imagens forem coloridas).
Divisão em Conjuntos de Treinamento, Validação e Teste:
Uma prática comum no treinamento de modelos de CNN é dividir o conjunto de dados em três partes: treinamento, validação e teste. O conjunto de treinamento é usado para treinar o modelo, o conjunto de validação é usado para ajustar os hiperparâmetros e otimizar o desempenho do modelo, e o conjunto de teste é usado para avaliar o desempenho final do modelo. A divisão adequada do conjunto de dados ajuda a avaliar a capacidade de generalização do modelo, garantindo que ele seja capaz de classificar imagens não vistas anteriormente.
Durante a divisão dos conjuntos, é importante garantir uma distribuição balanceada das classes em cada conjunto, para evitar qualquer viés ou desequilíbrio nos dados de treinamento, validação e teste. Existem várias estratégias para realizar essa divisão, como a divisão aleatória simples ou a estratificada, que mantém a proporção de cada classe em cada conjunto.
Além dessas técnicas mencionadas, existem outras abordagens de pré-processamento que podem ser aplicadas dependendo do contexto do problema e do conjunto de dados específico. Por exemplo, em alguns casos, pode ser necessário remover ruídos ou outliers das imagens, aplicar técnicas de equalização de histograma para melhorar o contraste, ou até mesmo utilizar técnicas avançadas de segmentação para extrair regiões de interesse.
É importante ressaltar que o pré-processamento de dados é uma etapa iterativa e depende do domínio do problema, das características dos dados e dos requisitos específicos do modelo. Portanto, é recomendado experimentar diferentes técnicas e avaliar seus efeitos no desempenho do modelo para obter os melhores resultados.
Arquitetura Básica de uma Rede Neural Convolucional
A arquitetura básica de uma Rede Neural Convolucional é composta por camadas convolucionais, camadas de pooling e camadas totalmente conectadas. Cada camada desempenha um papel específico no processo de classificação de imagens. Vamos discutir a função de cada uma delas e como elas contribuem para a classificação.
Camadas Convolucionais:
As camadas convolucionais são responsáveis pela extração de características das imagens. Elas aplicam um conjunto de filtros convolucionais sobre a imagem de entrada, realizando operações de convolução. Cada filtro convolucional é responsável por detectar um padrão ou característica específica na imagem, como bordas, texturas ou formas. Durante a convolução, o filtro desliza pela imagem aplicando operações matemáticas para calcular a resposta em cada local. Essas respostas são chamadas de "mapas de características" e representam a presença ou ausência de características específicas em diferentes regiões da imagem.
A função das camadas convolucionais é aprender padrões hierárquicos de características à medida que a informação flui pela rede. À medida que as camadas convolucionais se aprofundam na rede, elas se tornam capazes de capturar características mais complexas e abstratas. Isso permite que a CNN aprenda a representação das imagens de forma progressiva, desde características simples, como bordas e texturas, até características mais complexas, como formas e objetos.
Camadas de Pooling:
As camadas de pooling são usadas para reduzir a dimensionalidade dos mapas de características gerados pelas camadas convolucionais. Essa redução é realizada por meio de operações de downsampling, onde cada região do mapa de características é resumida em um único valor. O pooling pode ser feito de várias maneiras, sendo o pooling máximo (max pooling) o mais comum. Nessa abordagem, cada região é reduzida ao valor máximo encontrado nessa região.
A função do pooling é fornecer invariância espacial parcial às características aprendidas. Ele ajuda a tornar a CNN mais robusta a pequenas variações ou distorções nas características aprendidas. Além disso, o pooling também reduz a dimensionalidade dos dados, o que pode ajudar a evitar o overfitting e reduzir a quantidade de parâmetros a serem aprendidos.
Camadas Totalmente Conectadas:
As camadas totalmente conectadas são camadas densas em que cada neurônio está conectado a todos os neurônios da camada anterior. Essas camadas são responsáveis pela classificação final das características aprendidas pela rede. Elas recebem as características extraídas pelas camadas convolucionais e de pooling e as transformam em probabilidades de classificação para as diferentes classes de interesse.
A função das camadas totalmente conectadas é aprender os padrões de classificação finais, combinando as características aprendidas em uma representação que permita distinguir as diferentes classes de imagens. Essas camadas geralmente são seguidas por uma camada de saída, como uma camada softmax, que normaliza as probabilidades de classificação para que somem 1.
A arquitetura da CNN é construída empilhando camadas convolucionais, camadas de pooling e camadas totalmente conectadas em sequência. À medida que a informação flui através da rede, as camadas convolucionais extraem características relevantes da imagem, as camadas de pooling reduzem a dimensionalidade e fornecem invariância espacial parcial, e as camadas totalmente conectadas realizam a classificação final.
Além dessas camadas principais, é comum incluir outras camadas adicionais para melhorar o desempenho e a capacidade de generalização da CNN. Alguns exemplos incluem:
Camadas de normalização: Essas camadas são usadas para normalizar as ativações dos neurônios, ajudando a estabilizar o processo de aprendizado e acelerar a convergência. A normalização pode ser realizada por lotes (batch normalization) ou por instância (instance normalization).
Camadas de regularização: Essas camadas são usadas para reduzir o overfitting e melhorar a capacidade de generalização da CNN. Alguns exemplos de camadas de regularização são a regularização L1 e L2, que aplicam penalidades nos pesos da rede durante o treinamento, e o dropout, que aleatoriamente desativa uma porcentagem dos neurônios durante o treinamento.
Camadas de ativação: Essas camadas aplicam uma função de ativação não linear às saídas dos neurônios. As funções de ativação mais comuns são a função ReLU (Rectified Linear Unit), que mapeia valores negativos para zero e mantém os valores positivos, e a função softmax, que é usada na camada de saída para gerar probabilidades de classificação.
A escolha da arquitetura da CNN depende do problema específico e da complexidade das imagens a serem classificadas. Arquiteturas populares incluem a LeNet-5, a AlexNet, a VGGNet, a GoogLeNet (Inception) e a ResNet. Essas arquiteturas variam em termos do número de camadas convolucionais, tamanhos dos filtros, tamanho das camadas de pooling e configurações das camadas totalmente conectadas.
Durante o treinamento da CNN, os pesos e os vieses de todas as camadas são ajustados por meio de um processo de otimização, como o gradiente descendente estocástico (SGD), para minimizar a função de perda. A função de perda mede a diferença entre as saídas previstas pela CNN e os rótulos de classe reais das imagens. O treinamento geralmente é realizado em lotes (batches) de imagens e é repetido por várias épocas para melhorar gradualmente o desempenho do modelo.
Espero que essa explicação tenha fornecido uma compreensão clara sobre a arquitetura básica de uma CNN e o papel das camadas convolucionais, de pooling e totalmente conectadas na classificação de imagens. Essa estrutura em camadas permite que as CNNs aprendam características hierárquicas das imagens e realizem classificações precisas em uma ampla variedade de tarefas de visão computacional.
Implementação de uma CNN em Python para Classificação de Imagens
Nesta seção, iremos explorar a implementação prática de uma Rede Neural Convolucional em Python para a tarefa de classificação de imagens. Utilizaremos uma biblioteca popular, como TensorFlow ou PyTorch, para facilitar o desenvolvimento do modelo. A seguir, apresentaremos um exemplo de implementação básica passo a passo, utilizando a biblioteca TensorFlow. Na raiz do seu computador, crie uma pasta cnn e dentro dela, crie o arquivo cnn_image.py.
No geral, o código e as etapas descritas fornecem uma base sólida, porém simplificada, para começar a construir e treinar uma CNN em Python. É sempre recomendado adaptar e ajustar a implementação de acordo com as necessidades específicas do problema em questão.
Passo 1: Importando as bibliotecas necessárias
Começamos importando as bibliotecas necessárias, como TensorFlow, NumPy e Matplotlib. O TensorFlow é uma biblioteca amplamente utilizada para construir e treinar redes neurais, enquanto o NumPy é útil para realizar operações numéricas eficientes e o Matplotlib permite visualizar os resultados.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
Passo 2: Preparando os dados
Em seguida, é importante preparar os dados para treinamento e teste. Neste exemplo, vamos considerar um conjunto de dados fictício chamado dataset. Suponha que ele contenha imagens e seus rótulos correspondentes. Realizamos a divisão do conjunto de dados em treinamento e teste:
# Carregar o conjunto de dados
dataset = ...
# Divisão dos dados em treinamento e teste
train_data = ...
train_labels = ...
test_data = ...
test_labels = ...
Passo 3: Pré-processamento dos dados
Aplicamos as técnicas de pré-processamento mencionadas anteriormente, como redimensionamento e normalização dos dados:
# Redimensionamento das imagens
train_data_resized = tf.image.resize(train_data, [32, 32])
test_data_resized = tf.image.resize(test_data, [32, 32])
# Normalização dos valores dos pixels
train_data_normalized = train_data_resized / 255.0
test_data_normalized = test_data_resized / 255.0
Passo 4: Construindo a arquitetura da CNN
Agora, é hora de definir a arquitetura da CNN. Para este exemplo, vamos criar uma arquitetura simples com uma camada de convolução (Conv2D), seguida por uma camada de pooling (MaxPooling2D) e uma camada totalmente conectada (Dense):
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax')
])
Passo 5: Compilando e treinando o modelo
Após construir a arquitetura da CNN, compilamos o modelo especificando a função de perda, o otimizador e as métricas de avaliação:
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Em seguida, treinamos o modelo usando os dados de treinamento:
history = model.fit(train_data_normalized, train_labels, epochs=10, validation_data=(test_data_normalized, test_labels))
Passo 6: Avaliando o modelo
Finalmente, podemos avaliar o desempenho do modelo usando os dados de teste e plotar a acurácia e a perda ao longo do tempo:
test_loss, test_accuracy = model.evaluate(test_data_normalized, test_labels)
print(f"Acurácia do teste: {test_accuracy}")
# Plotar a acurácia e a perda ao longo do tempo
plt.plot(history.history['accuracy'], label='Acurácia de treinamento')
plt.plot(history.history['val_accuracy'], label='Acurácia de validação')
plt.plot(history.history['loss'], label='Perda de treinamento')
plt.plot(history.history['val_loss'], label='Perda de validação')
plt.xlabel('Épocas')
plt.ylabel('Valor')
plt.legend()
plt.show()
Com isso, concluímos a implementação básica de uma CNN em Python para a classificação de imagens. É importante lembrar que esse é apenas um exemplo simplificado e que existem várias variações e técnicas avançadas que podem ser exploradas para melhorar o desempenho do modelo, como o uso de camadas adicionais, otimização de hiperparâmetros e regularização.
A implementação da CNN pode variar dependendo da biblioteca utilizada, como TensorFlow ou PyTorch, mas os conceitos fundamentais permanecem os mesmos. Experimente diferentes arquiteturas, ajuste os hiperparâmetros e explore outras técnicas para obter o melhor desempenho possível em seu problema de classificação de imagens.
Treinamento e Avaliação do Modelo
Após preparar os dados e definir a arquitetura da CNN, é necessário treinar o modelo usando os conjuntos de dados de treinamento e validação. Nesta seção, abordaremos o processo de treinamento da CNN, incluindo a função de perda, otimização, ajuste de hiperparâmetros e avaliação do desempenho do modelo. Vou explicar o processo de treinamento da CNN usando conjuntos de dados de treinamento e validação e fornecendo exemplos de código em Python utilizando a biblioteca TensorFlow.
Função de Perda
A função de perda (loss function) é uma medida que quantifica o quão bem o modelo está performando durante o treinamento. Ela compara as previsões do modelo com os rótulos verdadeiros das imagens e calcula a diferença entre eles. O objetivo do treinamento é minimizar a função de perda, ajustando os pesos da CNN para tornar as previsões o mais próximas possível dos rótulos verdadeiros.
Para problemas de classificação de imagens, uma função de perda comumente utilizada é a Entropia Cruzada Categórica Esparsa (Sparse Categorical Crossentropy). Essa função calcula a diferença entre as distribuições de probabilidade preditas pelo modelo e as distribuições de probabilidade reais dos rótulos. Quanto menor a perda, melhor o modelo está performando na tarefa de classificação.
Otimização
A otimização refere-se ao processo de ajuste dos pesos da CNN para minimizar a função de perda. Isso é feito por meio de algoritmos de otimização que iterativamente atualizam os pesos com base no gradiente da função de perda em relação aos pesos. O algoritmo de otimização mais comumente utilizado é o Gradiente Descendente (Gradient Descent).
Existem variações do Gradiente Descendente, como o Gradiente Descendente Estocástico (Stochastic Gradient Descent - SGD) e o Adam, que são algoritmos mais avançados que ajustam os pesos de maneira mais eficiente. Esses algoritmos têm hiperparâmetros próprios, como taxa de aprendizado (learning rate), que controlam a magnitude das atualizações de peso. A escolha correta do otimizador e seus hiperparâmetros é fundamental para um treinamento eficaz da CNN.
# Definição da função de perda
loss_function = tf.keras.losses.SparseCategoricalCrossentropy()
# Definição do otimizador
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
Nesse exemplo, utilizamos a função de perda SparseCategoricalCrossentropy, que é comumente utilizada em problemas de classificação. Além disso, utilizamos o otimizador Adam com uma taxa de aprendizado de 0.001. Essas escolhas podem variar dependendo do problema e do conjunto de dados.
Ajuste de Hiperparâmetros
Os hiperparâmetros são parâmetros do modelo que não são aprendidos durante o treinamento, mas que afetam o comportamento e o desempenho da CNN. Antes de iniciar o treinamento, é possível ajustar os hiperparâmetros da CNN. Os hiperparâmetros incluem o número de épocas, o tamanho do lote, o tamanho dos filtros convolucionais, entre outros. Um exemplo de ajuste de hiperparâmetros é mostrado abaixo:
# Definição dos hiperparâmetros
num_epochs = 10
batch_size = 32
# Treinamento do modelo
history = model.fit(train_data, train_labels, epochs=num_epochs, batch_size=batch_size, validation_data=(val_data, val_labels))
Nesse exemplo, definimos o número de épocas (num_epochs) como 10 e o tamanho do lote (batch_size) como 32. Esses valores podem ser ajustados experimentalmente para obter o melhor desempenho do modelo.
A escolha adequada dos hiperparâmetros é crucial para obter um bom desempenho da CNN. O processo de ajuste de hiperparâmetros envolve a experimentação de diferentes valores e a avaliação do desempenho do modelo com cada combinação. O ajuste de hiperparâmetros pode ser realizado por meio de métodos de busca, como busca em grade (grid search) ou busca aleatória (random search), combinado com validação cruzada para avaliar o desempenho em conjuntos de dados de validação.
Treinamento com Conjuntos de Dados de Treinamento e Validação
Ao treinar a CNN, os dados de treinamento são alimentados à rede em lotes (batches) de tamanho definido. Um lote consiste em um conjunto de imagens e seus rótulos correspondentes. O modelo é ajustado iterativamente para cada lote, atualizando os pesos da rede com base no gradiente da função de perda.
Durante o treinamento, é comum dividir o conjunto de treinamento em mini lotes (mini-batches) para acelerar o processo de treinamento e permitir uma atualização mais frequente dos pesos. Cada mini lote é processado pela CNN, e os gradientes são calculados para ajustar os pesos. Esse processo é repetido para todos os mini lotes até que todos os exemplos do conjunto de treinamento tenham sido utilizados.
Durante o treinamento, também é necessário monitorar o desempenho do modelo nos dados de validação. Isso é importante para avaliar a capacidade de generalização do modelo e detectar sinais de overfitting (sobreajuste). Em cada época (iteração completa pelos dados de treinamento), o modelo é avaliado nos dados de validação e as métricas de desempenho, como acurácia ou perda, são registradas.
É possível ajustar o treinamento da CNN por meio de técnicas como regularização, que ajudam a evitar o overfitting, ou early stopping, que interrompe o treinamento se o desempenho nos dados de validação parar de melhorar. A escolha dessas técnicas depende da natureza do problema e da complexidade da CNN.
Avaliação do Desempenho do Modelo
Após o treinamento, é importante avaliar o desempenho final do modelo nos dados de teste. Os dados de teste são usados para fornecer uma estimativa imparcial e objetiva do desempenho real da CNN em novas amostras. O modelo é avaliado usando métricas como acurácia, precisão, recall e F1-score, dependendo da natureza do problema e das classes envolvidas.
Além disso, é útil visualizar e interpretar os resultados obtidos pela CNN. Isso pode ser feito por meio da criação de uma matriz de confusão, que mostra as classificações corretas e incorretas para cada classe, ou pela plotagem de curvas ROC para avaliar a capacidade de distinguir entre classes positivas e negativas.
É importante ressaltar que a avaliação do desempenho do modelo não deve ser baseada apenas nos resultados obtidos no conjunto de teste. É recomendado realizar uma validação cruzada, dividindo os dados em diferentes conjuntos de treinamento, validação e teste, para obter uma avaliação mais robusta e evitar conclusões enviesadas.
# Avaliação do modelo nos dados de teste
test_loss, test_accuracy = model.evaluate(test_data, test_labels)
print(f"Acurácia do teste: {test_accuracy}")
# Previsões do modelo
predictions = model.predict(test_data)
Após o treinamento, podemos avaliar o desempenho do modelo nos dados de teste. Utilizamos a função evaluate para calcular a perda e a acurácia do modelo nos dados de teste. Além disso, podemos obter as previsões do modelo para análises adicionais.
Em resumo, o processo de treinamento de uma CNN envolve a definição da função de perda, a escolha do otimizador e o ajuste de hiperparâmetros para minimizar a perda. A CNN é treinada em lotes de dados de treinamento, e o desempenho é monitorado nos dados de validação. Após o treinamento, o modelo é avaliado nos dados de teste para obter uma estimativa do desempenho real da CNN.
Resultados e Discussões
Os resultados obtidos pelo modelo treinado podem ser avaliados por meio da acurácia no conjunto de testes e da análise das curvas de treinamento, que mostram a evolução da acurácia e da perda ao longo das épocas.
A acurácia do teste, obtida através do comando test_accuracy = model.evaluate(test_data_normalized, test_labels), representa a porcentagem de imagens corretamente classificadas pelo modelo. Quanto maior a acurácia, melhor o desempenho do modelo na tarefa de classificação de imagens.
Ao analisar as curvas de treinamento, geradas pelo código plt.plot(history.history['accuracy'], label='Acurácia de treinamento') e plt.plot(history.history['val_accuracy'], label='Acurácia de validação'), é possível verificar a evolução da acurácia durante o treinamento tanto no conjunto de treinamento quanto no conjunto de validação. Se as curvas de acurácia estiverem aumentando e se aproximando, é um indicativo de que o modelo está aprendendo corretamente. Já as curvas de perda, geradas pelo código plt.plot(history.history['loss'], label='Perda de treinamento') e plt.plot(history.history['val_loss'], label='Perda de validação'), mostram a redução da perda durante o treinamento, indicando que o modelo está se ajustando aos dados.
Para discutir a eficácia do modelo, é importante comparar os resultados obtidos com outros modelos ou abordagens existentes na literatura para a mesma tarefa de classificação de imagens. Além disso, é necessário levar em consideração a complexidade e a variabilidade dos dados utilizados no conjunto de teste.
As limitações e desafios enfrentados na classificação de imagens podem incluir:
Dificuldade em obter dados de treinamento representativos: A disponibilidade de um conjunto de dados grande e diversificado é fundamental para treinar um modelo de classificação de imagens eficaz. A falta de dados suficientes ou desbalanceamento das classes pode afetar negativamente o desempenho do modelo.
Complexidade e variação dos objetos nas imagens: Imagens contendo objetos com diferentes poses, escalas, iluminação e variações de fundo podem dificultar a classificação correta. Modelos simples podem ter dificuldade em lidar com essas variações e podem exigir arquiteturas mais complexas ou técnicas avançadas de pré-processamento.
Overfitting: É comum que modelos de classificação de imagens apresentem overfitting, ou seja, eles se ajustam muito bem aos dados de treinamento, mas têm dificuldade em generalizar para dados não vistos. Isso pode ser mitigado com o uso de técnicas de regularização, como dropout e regularização L1/L2, ou aumentando a quantidade de dados de treinamento.
Otimização de hiperparâmetros: A escolha adequada dos hiperparâmetros do modelo, como taxa de aprendizado, tamanho do lote e número de camadas, pode ser um desafio. É necessário realizar experimentos e ajustes para encontrar a combinação ideal de hiperparâmetros que maximize o desempenho do modelo.
Para melhorar o desempenho do modelo de classificação de imagens, algumas possíveis melhorias incluem:
Aumentar a capacidade do modelo: É possível explorar arquiteturas mais complexas de CNN, como redes residuais (ResNet), redes convolucionais em cascata (DenseNet) ou redes neurais convolucionais de atenção (Attention-based CNNs). Essas arquiteturas têm demonstrado um desempenho superior em várias tarefas de classificação de imagens.
Data augmentation: Aumentar o tamanho do conjunto de dados através de técnicas de data augmentation pode ajudar a melhorar o desempenho do modelo. Essas técnicas envolvem a aplicação de transformações nas imagens, como rotações, zooms, deslocamentos e reflexões, para criar novas imagens de treinamento que são realistas e mantêm as mesmas classes.
Transfer learning: Utilizar transfer learning é outra abordagem que pode ser explorada. Em vez de treinar o modelo a partir do zero, pode-se aproveitar modelos pré-treinados em grandes conjuntos de dados, como o ImageNet, e adaptá-los para a tarefa específica de classificação de imagens. Isso permite que o modelo se beneficie do conhecimento prévio aprendido em tarefas semelhantes.
Ajuste de hiperparâmetros: Realizar uma busca sistemática de hiperparâmetros pode ser útil para encontrar uma combinação ideal que otimize o desempenho do modelo. Isso pode ser feito usando técnicas como busca em grade ou busca aleatória, variando os valores de hiperparâmetros como taxa de aprendizado, tamanho do lote, número de camadas e tamanho dos filtros.
Regularização: Implementar técnicas de regularização, como dropout, regularização L1/L2 ou normalização em lotes (batch normalization), pode ajudar a reduzir o overfitting e melhorar a generalização do modelo para novos dados.
Explorar outras abordagens: Além das CNNs, existem outras arquiteturas de rede neural que podem ser exploradas, como redes neurais recorrentes (RNNs) ou redes neurais convolucionais 3D (3D CNNs), dependendo da natureza das imagens ou dos padrões que precisam ser identificados.
É importante ressaltar que a melhoria do desempenho do modelo de classificação de imagens é um processo iterativo. É recomendado experimentar diferentes técnicas, arquiteturas e abordagens para encontrar a melhor combinação para o problema específico em questão.
Principais Aplicações das Redes Neurais Convolucionais
As redes neurais convolucionais têm demonstrado um desempenho impressionante em várias tarefas de processamento de imagens. Suas capacidades de aprendizado hierárquico e extração de características relevantes tornam-nas adequadas para uma ampla gama de aplicações. Neste tópico, discutiremos algumas das principais aplicações das CNNs e forneceremos exemplos de como elas são utilizadas em cada contexto.
Classificação de Imagens: A classificação de imagens é uma das aplicações mais comuns das CNNs. Elas são utilizadas para categorizar imagens em diferentes classes ou rótulos. Por exemplo, as CNNs podem ser treinadas para classificar imagens de animais em gatos, cães, pássaros e assim por diante. Essa aplicação é fundamental em sistemas de reconhecimento de objetos, sistemas de segurança e até mesmo em assistentes virtuais baseados em visão.
Detecção de Objetos: As CNNs são amplamente utilizadas na detecção de objetos em imagens. Essa tarefa envolve identificar e delimitar a presença de objetos específicos em uma imagem. Por exemplo, uma CNN treinada para detecção de carros pode ser capaz de identificar a localização e a classe de carros em uma cena. Essa aplicação é utilizada em sistemas de vigilância por vídeo, veículos autônomos, entre outros.
Segmentação de Imagens: A segmentação de imagens refere-se à tarefa de dividir uma imagem em regiões semelhantes, permitindo a identificação precisa dos objetos presentes. As CNNs são utilizadas para realizar a segmentação semântica, onde cada pixel da imagem é rotulado com uma classe específica. Essa aplicação é fundamental em áreas como medicina, onde a segmentação de imagens médicas pode ajudar na identificação de órgãos, tumores ou outras estruturas relevantes.
Reconhecimento Facial: O reconhecimento facial é uma aplicação-chave das CNNs, permitindo a identificação e autenticação de pessoas com base em suas características faciais. As CNNs podem ser treinadas para extrair características distintas do rosto, como formato dos olhos, nariz e boca, e utilizá-las para reconhecer indivíduos em diferentes contextos, como sistemas de segurança, desbloqueio facial em dispositivos móveis e sistemas de vigilância.
Processamento de Vídeo: As CNNs também têm aplicações no processamento de vídeo, permitindo a análise de sequências de imagens em movimento. Isso inclui tarefas como rastreamento de objetos, análise de movimento, reconhecimento de ações e compreensão de cenas em vídeos. Essas aplicações são relevantes em áreas como monitoramento de tráfego, análise de vídeos de segurança e análise de vídeos para fins de entretenimento.
Diagnóstico Médico: As CNNs têm sido empregadas em tarefas de diagnóstico médico, auxiliando na detecção e classificação de doenças em imagens médicas, como radiografias, ressonâncias magnéticas e tomografias computadorizadas. Elas podem ajudar na identificação de anomalias, como câncer, lesões ou doenças oculares, permitindo diagnósticos mais rápidos e precisos.
Reconhecimento de Texto em Imagens: As CNNs também podem ser usadas para reconhecimento óptico de caracteres (OCR), permitindo a extração de texto de imagens e documentos. Isso é útil em aplicações de processamento de documentos, como digitalização de textos, tradução automática de placas de trânsito e reconhecimento de caracteres em imagens de câmeras de segurança.
Arte Generativa e Estilo de Transferência: As CNNs são utilizadas em aplicações de arte generativa, onde podem aprender estilos artísticos e aplicá-los a outras imagens. Isso permite criar obras de arte únicas, transformar fotos em estilos de pintura famosos ou até mesmo gerar imagens completamente novas com base em padrões aprendidos.
Análise de Sentimentos em Imagens: As CNNs podem ser empregadas na análise de sentimentos em imagens, reconhecendo expressões faciais e interpretando o estado emocional das pessoas retratadas. Essa aplicação é útil em pesquisas de mercado, análise de mídia social e desenvolvimento de sistemas de interação humano-computador mais avançados.
Realidade Aumentada e Realidade Virtual: As CNNs têm um papel importante no rastreamento de objetos e detecção de pontos de referência em aplicações de realidade aumentada e realidade virtual. Elas podem ajudar a identificar e posicionar objetos virtuais em um ambiente real, tornando as experiências de AR e VR mais imersivas e interativas.
Esses são apenas alguns exemplos das diversas aplicações das redes neurais convolucionais. À medida que a tecnologia avança, novos usos e combinações de técnicas surgem, ampliando ainda mais o potencial das CNNs no processamento de imagens e além.
Conclusão
Em conclusão, as redes neurais convolucionais têm se estabelecido como uma ferramenta poderosa no campo do processamento de imagens e visão computacional. Seu design especializado permite a extração de características relevantes e o reconhecimento de padrões em dados de imagem, impulsionando avanços significativos em várias aplicações.
Ao longo deste artigo, exploramos os principais conceitos por trás das CNNs e fornecemos uma visão prática de como implementá-las para tarefas de classificação de imagens. A partir disso, destacamos também outras aplicações relevantes, como detecção de objetos, segmentação de imagens, reconhecimento facial e diagnóstico médico, demonstrando a versatilidade dessas redes.
É importante ressaltar que o campo das CNNs continua a evoluir rapidamente, impulsionado por avanços em hardware, algoritmos e disponibilidade de dados. À medida que a tecnologia avança, espera-se que as CNNs desempenhem um papel cada vez mais crucial no desenvolvimento de soluções inovadoras e na resolução de problemas complexos.
Dominar as CNNs torna-se uma habilidade valiosa para profissionais de visão computacional e aprendizado de máquina, abrindo portas para oportunidades de pesquisa, desenvolvimento e aplicação prática. À medida que novas técnicas e arquiteturas são desenvolvidas, as CNNs têm o potencial de impulsionar avanços em áreas como medicina, automação industrial, robótica, realidade virtual e muito mais.
Em resumo, as CNNs representam uma ferramenta poderosa para lidar com tarefas de processamento de imagens e têm o potencial de impactar positivamente várias áreas da sociedade. Ao continuarmos explorando e desenvolvendo essas redes, podemos esperar resultados cada vez mais promissores e inovadores. Espero que este artigo tenha fornecido uma base sólida para a compreensão das CNNs e inspire você a explorar e aplicar essa tecnologia fascinante em seus próprios projetos.
Obrigado por ler! Até a próxima!
Referências:
S. Albawi, T. A. Mohammed and S. Al-Zawi, "Understanding of a convolutional neural network." 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 2017, pp. 1-6, doi: 10.1109/ICEngTechnol.2017.8308186.
WU, Jianxin. Introduction to convolutional neural networks. National Key Lab for Novel Software Technology. Nanjing University. China, v. 5, n. 23, p. 495, 2017.
CHAUHAN, Rahul; GHANSHALA, Kamal Kumar; JOSHI, R. C. Convolutional neural network (CNN) for image detection and recognition. In: 2018 first international conference on secure cyber computing and communication (ICSCCC). IEEE, 2018. p. 278-282.
HIJAZI, Samer et al. Using convolutional neural networks for image recognition. Cadence Design Systems Inc.: San Jose, CA, USA, v. 9, p. 1, 2015.
TRAORE, Boukaye Boubacar; KAMSU-FOGUEM, Bernard; TANGARA, Fana. Deep convolution neural network for image recognition. Ecological informatics, v. 48, p. 257-268, 2018.
Publicação por Paulinho Giovannini.