
Imagem do autor
Construir uma infraestrutura LLM (Large Language Models ou grandes modelos de linguagem) ou de IA em Rust pode oferecer vários benefícios, apesar do domínio do Python no espaço de IA.
- Desempenho: o Rust é conhecido por seu alto desempenho e controle de baixo nível, o que pode ser crucial para a construção de sistemas de IA em grande escala. Os modelos de linguagem, especialmente os modelos de aprendizado profundo, podem ser computacionalmente intensivos. O desempenho do Rust pode levar a melhorias significativas de velocidade em comparação com o Python, tornando-o mais adequado para lidar com eficiência com tarefas computacionalmente caras.
- Segurança da memória: as regras rígidas do compilador e o modelo de propriedade do Rust garantem a segurança da memória, evitando bugs comuns, como desreferências de ponteiro nulo e corridas de dados. Isso pode tornar os sistemas de IA baseados em Rust mais confiáveis e menos propensos a travamentos, o que é particularmente importante para modelos de linguagem de longa duração ou aplicações críticas de IA.
- Simultaneidade: o suporte integrado do Rust para simultaneidade e threads leves pode levar à utilização eficiente de processadores multicore. Isso pode ser valioso ao implementar o processamento paralelo para treinar grandes modelos de linguagem ou lidar com múltiplas solicitações de inferência simultaneamente.
Sim, vale lembrar que o extenso ecossistema do Python, as bibliotecas bem estabelecidas (por exemplo, TensorFlow, PyTorch) e a facilidade de uso fizeram dele a escolha certa para muitos projetos de IA. Mas, se você tiver um senso de exploração e definir seus requisitos específicos e Rust estiver no topo, esta pode ser uma leitura relevante para você.
Vamos tentar responder à pergunta: o Rust tem uma biblioteca completa, como o Python tem a langchain para trabalhar, com LLMs?
OBS: pode valer a pena exercitar alguns dos blocos de construção por trás da langchain em Python. Para isso, eu criei a langchain-llm-katas, experimente.
Blocos de construção de biblioteca de cadeia
Se nos distanciarmos por um minuto e ignorarmos os fluxos de trabalho de alto nível, como agentes, kits de ferramentas e casos de uso, estaremos olhando para a infraestrutura comum abaixo de todas aquelas que permitem a existência dessas construções de alto nível:
- LLM — carregar, chamar LLMs e suportar diferentes modelos, que precisam de:
- Incorporação e tokenização — transformar texto em incorporações, onde o texto é carregado com:
- Carregadores (loaders) - transformar vários formatos de documento em texto simples e digerível por LLM, que precisa ser pós-processado por:
- Divisores (splitters) — para criar partes legíveis e úteis do texto original, para trabalhar com os limites de token do LLM e serem armazenados em:
- Bancos de dados vetoriais - que são usados para formular prompts que são enviados aos LLMs e também para alimentar:
- Memória — que é feita para suportar contexto e sessões com LLMs. Mas também, temos a infraestrutura para:
- Modelos — que estruturam uma solicitação de um LLM, que pode conter uma chamada para:
- Ferramentas - que são uma coleção de ferramentas do mundo real, como uma calculadora ou um navegador para o LLM automatizar por meio da leitura de um prompt estruturado
Então, como é tudo isso atualmente em Rust?
Infraestrutura e blocos de construção
LLM e transformadores
llm é um ecossistema de bibliotecas Rust para trabalhar com grandes modelos de linguagem. Ele foi desenvolvido com base na biblioteca GGML, rápida e eficiente para aprendizado de máquina. É uma biblioteca sólida, expansiva e estável para trabalhar com modelos, a ponto de ser a única biblioteca a ser sempre escolhida, e é bom que não haja muitas alternativas.
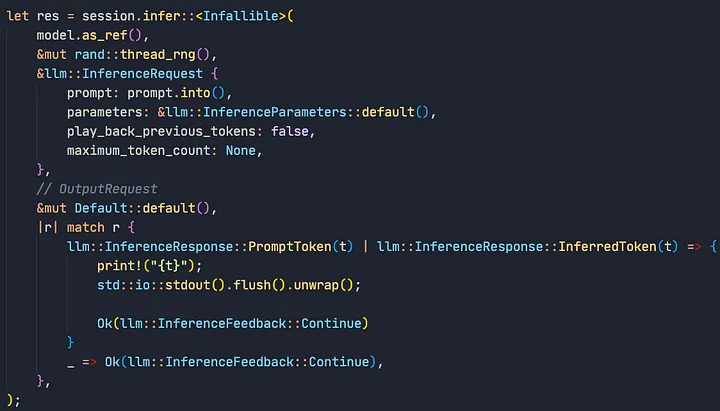
Veja como executar inferência usando apenas o crate llm :
let model = llm::load_dynamic(
Some(model_architecture),
&model_path,
tokenizer_source,
Default::default(),
llm::load_progress_callback_stdout,
)
.unwrap_or_else(|err| {
panic!("Falha ao carregar o modelo {model_architecture} do {model_path:?}: {err}")
});
let mut session = model.start_session(Default::default());
let res = session.infer::<Infallible>(
model.as_ref(),
&mut rand::thread_rng(),
&llm::InferenceRequest {
prompt: prompt.into(),
parameters: &llm::InferenceParameters::default(),
play_back_previous_tokens: false,
maximum_token_count: None,
},
// Requisito de saída
&mut Default::default(),
|r| match r {
llm::InferenceResponse::PromptToken(t) | llm::InferenceResponse::InferredToken(t) => {
print!("{t}");
std::io::stdout().flush().unwrap();
Ok(llm::InferenceFeedback::Continue)
}
_ => Ok(llm::InferenceFeedback::Continue),
},
);
Provavelmente a biblioteca mais versátil e produtiva que existe para Rust para o uso de modelos de transformadores, inspirada na biblioteca de transformadores da huggingface. Este é uma opção única para modelos de transformadores locais para diferentes tarefas, desde a tradução até a incorporação.
- Muitos casos de uso e exemplos.
- Muito ampla, assim como a biblioteca e transformadores original.
- Você pode fazer muitas coisas apenas usando esta biblioteca e talvez não precise de mais nada.
Em termos de casos de uso, aqui está um exemplo de análise de sentimentos:
let sentiment_classifier = SentimentModel::new(Default::default())?;
let input = [
"Provavelmente meu filme favorito de todos os tempos, uma história de abnegação, sacrifício e dedicação para uma causa nobre, mas não é enfadonho ou chato." ,
"Este filme tentou ser muitas coisas ao mesmo tempo: sátira política pungente, sucesso de bilheteria de Hollywood, comédia romântica sentimental, promoção de valores familiares ..." ,
"Se você gosta de risadas originais e dolorosas, você vai gostar deste filme. Se você é jovem ou velho, então você vai adorar esse filme, caramba, até minha mãe gostou dele." ,
];
let output = sentiment_classifier.predict(&input);
E incorporações:
let model = SentenceEmbeddingsBuilder::remote(
SentenceEmbeddingsModelType::AllMiniLmL12V2
).create_model()?;
let sentences = [
"esta é uma frase de exemplo" ,
"cada frase é convertida"
];
let output = model.encode(&sentences)?;
E muitos outros casos de uso.
Incorporações e Tokenização
Você pode fazer incorporações com o seguinte:
rust-bertllm
Esta biblioteca é construída com base na biblioteca tiktoken do OpenAI Rust e a estende um pouco. Deve ser uma boa escolha para suas necessidades de tokenização.
use tiktoken_rs::p50k_base;
let bpe = p50k_base().unwrap();
let tokens = bpe.encode_with_special_tokens(
"Esta é uma frase com espaços."
);
println!("Conta do token: {}", tokens.len());
Carregadores
No momento em que este artigo foi escrito, não existia nenhum carregador unificado como o unstructured, que possa carregar e converter documentos sem se preocupar tanto com a implementação do provedor específico. Alguns deles podem precisar de um pouco de esforço para colocar o conteúdo em um formato plano semelhante a um documento LLM (texto simples, páginas), por exemplo, fazendo um loop e extraindo planilhas de arquivos Excel.
No entanto, aqui está um mapeamento sensato do formato de arquivo para uma biblioteca Rust apropriada:
- csv
- e-mail: eml, msg
- epub pandoc
- xls
- html pandoc
- images (ocr)
- md
- org mode (.org)
- open office pandoc
- txt (não há necessidade)
- pptx pandoc
- docx pandoc
- rst pandoc
- rft pandoc
- xml
Divisores
https://github.com/benbrandt/text-splitter
A única biblioteca prática o suficiente para divisão. Parece estar adotando uma abordagem de “dividir corretamente” (split properly), onde não é necessário escolher se deseja dividir por novas linhas, caracteres, recursivamente ou tokens. Ela descerá e usará um método apropriado para maximizar o tamanho das partes.
Prompts
No momento em que este artigo foi escrito, não havia um consenso geral e nenhuma biblioteca que unificasse o conceito de modelo como a langchain fez. No entanto, pegar uma biblioteca de modelos e construir em cima dela é uma ótima maneira de implementar prompts.
O Rust tem algumas bibliotecas de modelos fantásticas que se adequam à modelagem:
- Handlebars — para modelos padrão, familiares e de lógica mínima.
- Tera — para quem está familiarizado com jinja2.
- Liquid – para quem está familiarizado com liquid.
Na maioria das vezes, o handlebars é a melhor aposta, pois será familiar ao público em geral.
Bancos de dados vetoriais
Atualmente, não existe uma interface unificada para bancos de dados vetoriais que forneça um empacotador (wrapper) geral para muitos provedores. Pesquise alguns projetos de código aberto sobre LLMs. Você encontrará reimplementações das mesmas interfaces repetidamente, o que é uma pena, e ainda assim, nenhuma biblioteca fornece uma interface genérica.
Dada uma interface tão simplista, há um bom ROI (Return Of Investment ou retorno de investimento) na construção de uma biblioteca desse gênero. Deveria ser, basicamente:
add_documentssimilarity_search
Para sua informação: muitos bancos de dados de vetores individuais são implementados em Rust, tanto comerciais quanto de código aberto. Qdrant é provavelmente o de código aberto mais popular.
Memória
Existem alguns projetos que implementam memória ou histórico. A maioria deles implementa um serviço que armazena índices e históricos de pesquisa para você e também pode ser usado como referência sobre como fazer seu fluxo de trabalho em Rust lidando com IA.
Alguns interessantes são:
- memex - parte do spyglass, tem uma boa leitura de código e faz armazenamento de documentos e pesquisa semântica para projetos LLM.
- indexify – memória LLM de longo prazo.
- motorhead — recuperação de memória/informações.
Ferramentas
No momento em que este artigo foi escrito, nenhuma biblioteca de ferramentas/plugins era dedicada apenas a esse propósito. Ou seja, bibliotecas que fornecem uma interface sólida para:
- Declarar uma ferramenta;
- Capacidades;
- Executar uma ferramenta (com segurança ou não);
- Estruturar uma solicitação e resposta de ferramenta.
No entanto, essas implementações podem ser encontradas nas poucas implementações de cadeia que o Rust possui atualmente, que são discutidas abaixo.
Cadeias
Uma biblioteca de cadeia de pequeno escopo. Eu diria 30% do que a langchain-py tem.
- Primeiros tempos para este projeto;
- Boa quantidade de exemplos;
- Interfaces genéricas, mas focadas no Databend;
- Boa cobertura de teste (é um desafio testar a infra LLM em qualquer caso).
Vejamos algumas das abstrações:
Incorporação
pub trait Embedding: Send + Sync {
async fn embed_query(&self, input: &str) -> Result<Vec<f32>>;
async fn embed_documents(&self, inputs: &Documents) -> Result<Vec<Vec<f32>>>;
}
LLM
pub trait LLM: Send + Sync {
async fn embedding(&self, inputs: Vec<String>) -> Result<EmbeddingResult>;
async fn generate(&self, input: &str) -> Result<GenerateResult>;
async fn chat(&self, _input: Vec<String>) -> Result<Vec<ChatResult>> {
unimplemented!("")
}
}
- As integrações atualmente são: OpenAI, Azure-OpenAI e Databend, então provavelmente a mistura de dados do Databend com a IA foi o gatilho para tudo isso.
Documento
#[derive(Debug, Clone, Eq, PartialEq)]
pub struct Document {
pub path: String,
pub content: String,
pub content_md5: String,
}
impl Document {
pub fn create(path: &str, content: &str) -> Self {
Document {
path: path.to_string(),
content: content.to_string(),
content_md5: format!("{:x}", md5::compute(content)),
}
}
pub fn tokens(&self) -> usize {
chat_tokens(&self.content).unwrap().len()
}
pub fn size(&self) -> usize {
self.content.len()
}
}
#[derive(Debug)]
pub struct Documents {
documents: RwLock<Vec<Document>>,
}
Prompt
pub trait Prompt: Send + Sync {
fn template(&self) -> String;
fn variables(&self) -> Vec<String>;
fn format(&self, input_variables: HashMap<&str, &str>) -> Result<String>;
}
- Substituição simples de variáveis apenas com base em texto.
- Nível único, sem prompts avançados dependentes ou parciais.
Armazenamento de vetores
#[async_trait::async_trait]
pub trait VectorStore: Send + Sync {
async fn init(&self) -> Result<()>;
async fn add_documents(&self, inputs: &Documents) -> Result<Vec<String>>;
async fn similarity_search(&self, query: &str, k: usize) -> Result<Vec<Document>>;
}
- Suporte para
databendapenas como provedor. - Falta de MMR para pesquisa (como em todas as interfaces que vi até agora).
- Abstração de salvar/carregar em falta (mas será que isso pertence a uma característica?).
No Geral
- Base de código relativamente sólida e boas abstrações.
- Divisores (sem abstração ou estratégia para escolher, mas este é o caso de todas as implementações de cadeia em Rust que vi até agora).
- Memória (apenas nos primeiros tempos, parece).
cadeia llm
Uma biblioteca de cadeia mais popular, dividida em crates do Rust, bons idiomas de Rust e estrutura. Não é uma cobertura completa como a langchain-py tem. Talvez 30%, e ainda nos primeiros tempos aqui, como acontece com todas as outras bibliotecas.
Vejamos as abstrações aqui:
Incorporação
#[async_trait]
pub trait Embeddings {
type Error: Send + Debug + Error + EmbeddingsError;
async fn embed_texts(&self, texts: Vec<String>) -> Result<Vec<Vec<f32>>, Self::Error>;
async fn embed_query(&self, query: String) -> Result<Vec<f32>, Self::Error>;
}
Armazenamento de vetores
#[async_trait]
pub trait VectorStore<E, M = EmptyMetadata>
where
E: Embeddings,
M: serde::Serialize + serde::de::DeserializeOwned,
{
type Error: Debug + Error + VectorStoreError;
async fn add_texts(&self, texts: Vec<String>) -> Result<Vec<String>, Self::Error>;
async fn add_documents(&self, documents: Vec<Document<M>>) -> Result<Vec<String>, Self::Error>;
async fn similarity_search(
&self,
query: String,
limit: u32,
) -> Result<Vec<Document<M>>, Self::Error>;
}
Divisores
Parece que um divisor é um tokenizador (Tokenizer):
pub trait Tokenizer {
fn tokenize_str(&self, doc: &str) -> Result<TokenCollection, TokenizerError>;
fn to_string(&self, tokens: TokenCollection) -> Result<String, TokenizerError>;
fn split_text(
&self,
doc: &str,
max_tokens_per_chunk: usize,
chunk_overlap: usize,
) -> Result<Vec<String>, TokenizerError>;
}
Prompt
Prompt é uma construção que permite operar com uma abstração de mensagens de Chat ou Text. A modelagem é poderosa e baseada em tera.
Documento
#[derive(Debug)]
pub struct Document<M = EmptyMetadata>
where
M: serde::Serialize + serde::de::DeserializeOwned,
{
pub page_content: String,
pub metadata: Option<M>,
}
Mais semelhante do que diferente em comparação com o documento da langchain-py.
Armazenamento de documento (Carregador?)
#[async_trait]
pub trait DocumentStore<T, M>
where
T: Send + Sync,
M: Serialize + DeserializeOwned + Send + Sync,
{
type Error: std::fmt::Debug + std::error::Error + DocumentStoreError;
async fn get(&self, id: &T) -> Result<Option<Document<M>>, Self::Error>;
async fn next_id(&self) -> Result<T, Self::Error>;
async fn insert(&mut self, documents: &HashMap<T, Document<M>>) -> Result<(), Self::Error>;
}
No geral
- Boa separação entre recursos e crates.
- Parece compatível com o Rust.
- Falta divisores e carregadores.
- Falta integrações em geral e, especialmente, armazenamento de vetores.
SmartGPT
Esta não é uma biblioteca nem uma infraestrutura, mas os componentes internos estão bem construídos e podem ser de boa utilidade para uma biblioteca de cadeia. Vamos dar uma olhada nas abstrações:
LLM
pub trait LLMModel : Send + Sync {
async fn get_response(&self, messages: &[Message], max_tokens: Option<u16>, temperature: Option<f32>) -> Result<String, Box<dyn Error>>;
async fn get_base_embed(&self, text: &str) -> Result<Vec<f32>, Box<dyn Error>>;
fn get_token_count(&self, text: &[Message]) -> Result<usize, Box<dyn Error>>;
fn get_token_limit(&self) -> usize;
fn get_tokens_from_text(&self, text: &str) -> Result<Vec<String>, Box<dyn Error>>;
}
Alguns métodos foram removidos porque eram implementados por padrão.
Mensagem
#[derive(Clone, Debug)]
pub enum Message {
User(String),
Assistant(String),
System(String)
}
Modelando uma mensagem em um padrão User-AI-System (Sistema-IA-usuário).
Sistema de memória (histórico?)
pub trait MemorySystem : Send + Sync {
async fn store_memory(&mut self, llm: &LLM, memory: &str) -> Result<(), Box<dyn Error>>;
async fn get_memory_pool(&mut self, llm: &LLM, memory: &str, min_count: usize) -> Result<Vec<RelevantMemory>, Box<dyn Error>>;
async fn get_memories(
}
…
Uma boa interface de memória.
Comando (ferramenta?)
pub trait CommandImpl : Send + Sync {
async fn invoke(&self, ctx: &mut CommandContext, args: ScriptValue) -> Result<CommandResult, Box<dyn Error>>;
fn box_clone(&self) -> Box<dyn CommandImpl>;
}
No geral
- Este projeto possui uma coleção de ferramentas relativamente rica e pode ser o melhor começo para uma biblioteca genérica que implementa ferramentas.
- A base de código é muito pragmática porque quase tudo está realmente em uso.
- Onde a funcionalidade não era necessária - ela não existe (naturalmente), e é aqui que falta na base de código, em comparação com a langchain: divisores, carregadores, modelos de prompt, armazenamentos de vetores e uma sensação geral de vários provedores.
- Usá-la como uma biblioteca langchain de uso geral seria estranho, a menos que você atingisse os casos de uso que este projeto já resolve. O que eu acho que não será suficiente rápido.
Obrigado por ler.
Este artigo foi escrito por Dotan Nahum e traduzido por Isabela Curado Nehme. Seu original pode ser lido aqui.






Latest comments (0)