

Uma imagem representando a base do Aprendizado Profundo
Consulte este notebook se você já conhece o básico.
Por que Aprendizado Profundo?
Há algum tempo, eu estava em uma missão para aprender sobre Aprendizado Profundo (Deep Learning), especificamente Aprendizado Profundo Generativo. Enquanto eu mergulhava no "vasto reino de recursos online", tropecei em inúmeros vídeos dedicados ao Aprendizado Profundo. No entanto, notei que havia apenas um punhado de tutoriais disponíveis para o Aprendizado Profundo Generativo naquele momento (a partir de 29 de maio de 2023). Embora esses vídeos fornecessem percepções valiosas sobre os conceitos matemáticos necessários, percebi que muitas vezes eles dependiam de bibliotecas de alto nível como TensorFlow e PyTorch para implementar os programas.
Mas minha curiosidade não diminuiu. Eu queria construir meu próprio programa do zero para realmente entender a essência do Aprendizado Profundo. Com a ajuda de tutoriais do YouTube e um pouquinho (realmente um pouquinho) de conhecimento matemático, embarquei em uma jornada para descobrir como as coisas funcionam. Isso me permitiu descobrir a estrutura fundamental que sustenta o Aprendizado Profundo, permitindo-me compreender verdadeiramente suas complexidades e liberar meu potencial criativo.
Básico de Aprendizado Profundo
Vamos construir um modelo de classificação de pontos e, ao fazer isso, aprender sobre Redes de Aprendizado Profundo.
Criação e Pré-processamento de Dados
Nesta etapa, você precisa coletar os dados e pré-processá-los para obter leituras precisas. O sucesso e a falha do modelo são determinados em grande parte pelos dados fornecidos ao modelo. Vamos criar um conjunto de dados simples para o nosso modelo.
# Cria um array de números de x a y com um stp de x
# np.arange(x, y, z)
x_values = np.arange(-2500, 2500, 0.1)
y_values = np.arange(-25000, 25000, 1)
# embaralha a posição dos valores no array
np.random.shuffle(x_values)
np.random.shuffle(y_values)
# Nossa função de gráfico parabólica
def parabola(x):
return round((0.8 * x**2) - 300*x + 50, 0)
dataset = []
for x, y in zip(x_values, y_values):
if y < parabola(x): # Os pontos estão dentro da parábola
label = 0
labels[0] += 1
else: # Os pontos estão dentro ou fora da parábola
label = 1
labels[1] += 1
dataset.append((x, y, label))
# Convertendo lista em array
dataset = np.array(dataset)
Ao criar os dados, vamos agora dividi-los em dados de treinamento e teste.
Os Dados de Treinamento são os dados usados durante o treinamento do modelo, enquanto os Dados de Teste são os dados usados durante o teste dos dados (para a saída final).
Normalmente, os Dados de Teste são menores em comparação com os Dados de Treinamento e ambos formam o conjunto de dados anterior.
# obtendo a forma dos dados
m = dataset.shape[0]
# dividindo os dados em dados de teste e treinamento
data_test = dataset[:1000].T
x_test = data_test[0:2]
y_test = data_test[2]
data_train = dataset[1000:m].T
x_train = data_train[0:2]
y_train = data_train[2]
Criando a Rede Neural Profunda
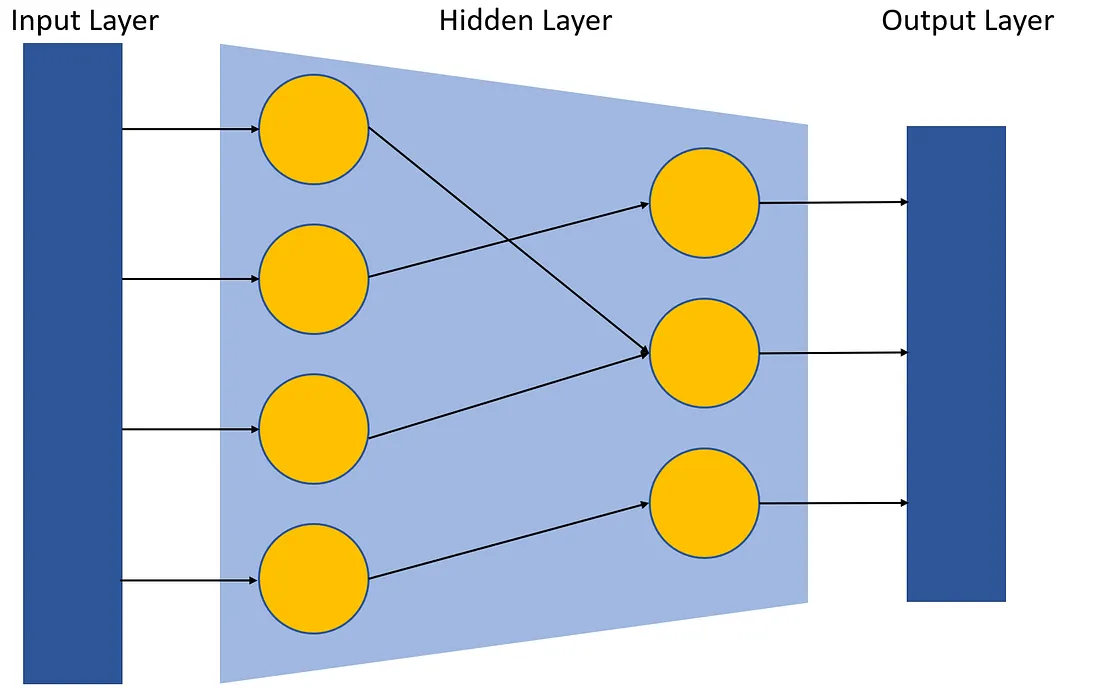
Como um Modelo de Aprendizado Profundo basicamente se parece
Qualquer Modelo de Aprendizado Profundo é dividido em 3 partes principais:
- A Camada de Entrada (input layer)
- A Camada Oculta (hidden layer)
- A Camada de Saída (output layer)
A Camada de Entrada
Esta é a camada onde todos os seus dados pré-processados são inseridos. Ela geralmente não precisa de nenhuma atenção especial dada às suas dimensões, pois deveríamos ser capazes de inserir dados de qualquer dimensão.
A Camada Oculta
A camada oculta em uma rede neural é uma camada intermediária entre as camadas de entrada e saída. Ela desempenha um papel crucial na captação de padrões e características complexas dos dados de entrada, permitindo que a rede aprenda e faça previsões precisas.
A Camada de Saída
A camada de saída em uma rede neural é responsável por produzir as previsões ou saídas finais com base nas informações aprendidas nas camadas anteriores. Normalmente, consiste em um ou mais neurônios, cada um representando uma classe específica ou valor de regressão, e a função de ativação usada na camada de saída depende da natureza do problema a ser resolvido.
Então, com isso de lado, vamos começar inicializando os parâmetros (pesos) de nossa rede neural.
# Inicializa os pesos e a base do gráfico para um valor entre -0,5 e 0,5
def init_params():
W1 = np.random.rand(2, 2) - 0.5
b1 = np.random.rand(2, 1) - 0.5
W2 = np.random.rand(2, 2) - 0.5
b2 = np.random.rand(2, 1) - 0.5
return W1, b1, W2, b2
Agora vamos inicializar nossas Funções de Ativação. As funções de ativação desempenham um papel integral nas redes neurais, introduzindo a não linearidade. Essa não linearidade permite que as redes neurais desenvolvam representações e funções complexas com base nas entradas que não seriam possíveis com um simples modelo de regressão linear.
# Para este modelo, usaremos o RelU e a Função Sigmóide
# Seus gráficos são dados abaixo
# Eles são inicializados da seguinte forma
def ReLU(Z):
return np.maximum(Z, 0)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
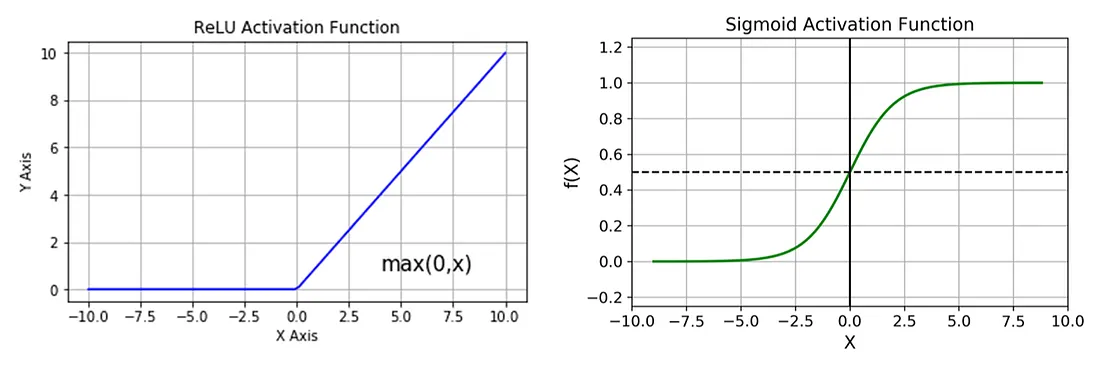
O gráfico das funções ReLU (unidade linear retificada) e Sigmóide
Vamos agora inicializar a propagação para frente do nosso modelo. A propagação para frente é o processo de passar os dados de entrada através da rede neural para calcular as previsões ou ativações de saída de cada camada. Envolve multiplicar os dados de entrada pelos pesos aprendidos, aplicar funções de ativação e propagar os resultados para a frente através da rede.
# Z1 é o produto dos nós e seus pesos, adicionado de algum viés
# A1 é a ativação realizada por ReLU e Sigmoid
def forward_prop(W1, b1, W2, b2, X):
Z1 = W1.dot(X) + b1
A1 = ReLU(Z1)
Z2 = W2.dot(A1) + b2
A2 = sigmoid(Z2)
return Z1, A1, Z2, A2
Agora vamos codificar algumas funções utilitárias para a propagação para trás. O ReLU_deriv (derivada da função ReLU) é a inclinação das funções ReLU em diferentes pontos. É dada pela seguinte fórmula.
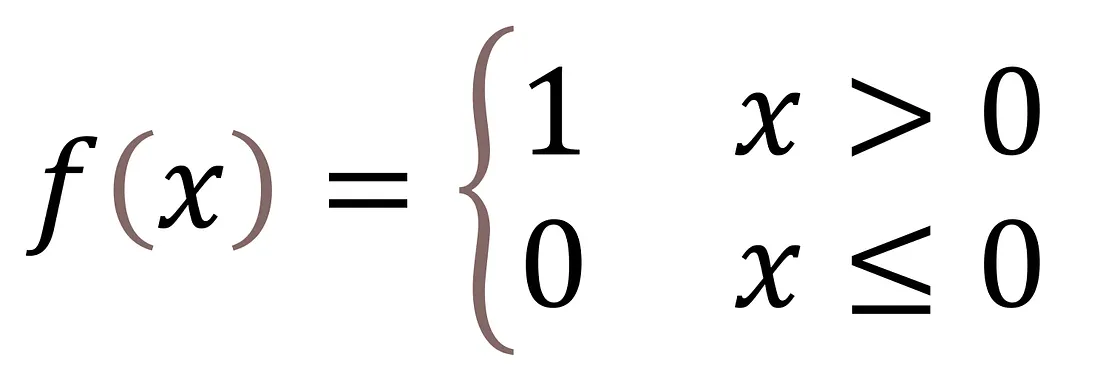
Função ReLU Derivada
A codificação one-hot é uma técnica popular usada em aprendizado de máquina (machine learning) para representar variáveis categóricas como vetores binários. Ela converte uma variável categórica em uma matriz binária esparsa onde cada coluna corresponde a uma categoria única, e um valor de 1 indica a presença dessa categoria.
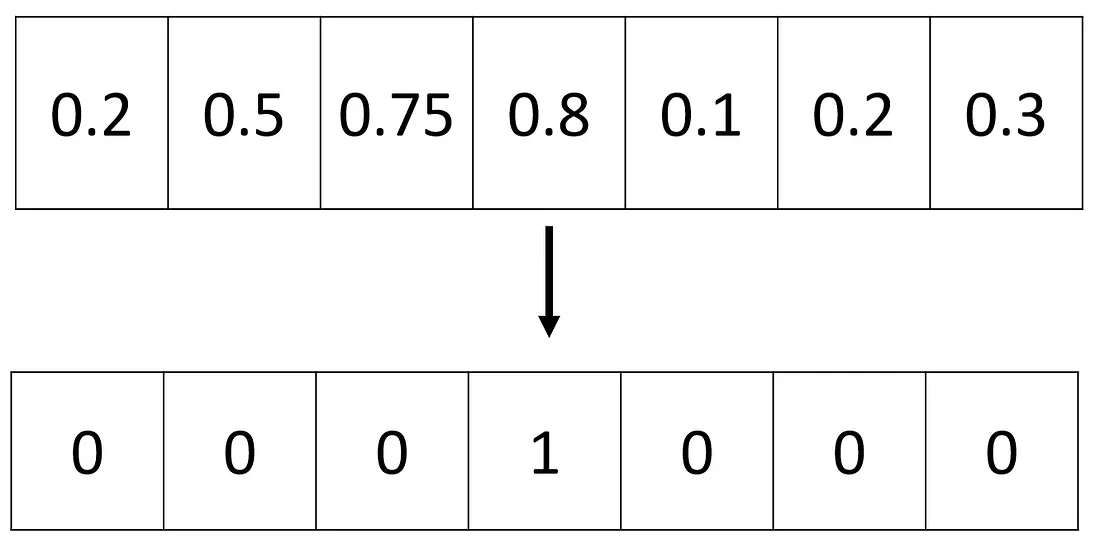
A codificação One Hot normaliza cada valor para zero, mantendo o valor requerido em 1
def ReLU_deriv(Z):
return Z > 0
def one_hot(Y):
one_hot_Y = np.zeros((Y.size, int(np.ceil(Y.max()))))
one_hot_Y[np.arange(Y.size), np.ceil(Y).astype(int) - 1] = 1
one_hot_Y = one_hot_Y.T
return one_hot_Y
Agora, vamos avançar para a Propagação para Trás. É um passo chave no treinamento de redes neurais. Envolve o cálculo e a atualização dos gradientes dos parâmetros do modelo com base no erro ou perda calculada na propagação para a frente, permitindo que a rede aprenda e melhore seu desempenho ao longo do tempo.
def backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y):
one_hot_Y = one_hot(Y)
dZ2 = A2 - one_hot_Y
const = 1/m
dW2 = const * dZ2.dot(A1.T)
db2 = const * np.sum(dZ2)
dZ1 = W2.T.dot(dZ2) * ReLU_deriv(Z1)
dW1 = const * dZ1.dot(X.T)
db1 = const * np.sum(dZ1)
return dW1, db1, dW2, db2
E agora, atualizamos todos os pesos com base nas mudanças de valor que recebemos da propagação para trás.
def update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, learn_rate):
W1 = W1 - learn_rate * dW1
b1 = b1 - learn_rate * db1
W2 = W2 - learn_rate * dW2
b2 = b2 - learn_rate * db2
return W1, b1, W2, b2
E agora, finalmente, podemos combinar todas as nossas funções em uma função de descida do gradiente e ver a mágica acontecer. A descida do gradiente é um algoritmo de otimização usado para minimizar a perda ou erro de um modelo de aprendizado de máquina. Ele ajusta iterativamente os parâmetros do modelo na direção de descida mais íngreme da função de perda, aproximando-se gradualmente dos valores ótimos. Ao atualizar os parâmetros com base no gradiente da perda, a descida do gradiente ajuda o modelo a convergir para uma solução melhor.
# getPrediction e getAccuracy são funções bastante padronizadas
def get_predictions(A2):
return np.argmax(A2, 0)
def get_accuracy(predictions, Y):
return np.sum(predictions == Y) / Y.size
# esta função gradiente descendente é a etapa final para treinar nosso modelo
def gradient_descent(X, Y, alpha, iterations):
W1, b1, W2, b2 = init_params()
for i in range(iterations + 1):
Z1, A1, Z2, A2 = forward_prop(W1, b1, W2, b2, X)
dW1, db1, dW2, db2 = backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y)
W1, b1, W2, b2 = update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, alpha)
if i % 25 == 0:
print("Iteration: ", i)
predictions = get_predictions(A2)
print(get_accuracy(predictions, Y))
return W1, b1, W2, b2
E aqui finalmente executamos isso:
# E aqui está o comando final para testar nosso modelo
W1, b1, W2, b2 = gradient_descent(x_train, y_train, 0.10, 500)
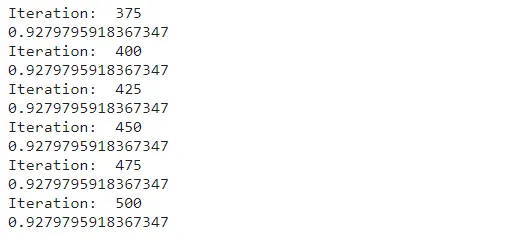
Após executar a função final de descida do gradiente, obtemos a precisão final de nossos dados de treinamento, ou seja, 0.92 ou 92 por cento. (PS: você pode obter um valor ligeiramente diferente devido à aleatoriedade na inicialização dos parâmetros). Se quiser aumentar a eficiência, você pode modificar a taxa de aprendizado.
Vamos agora encontrar a precisão desses dados em nossos dados de teste (PS: criamos isso no início):
# testar previsões
def make_predictions(X, W1, b1, W2, b2):
_, _, _, A2 = forward_prop(W1, b1, W2, b2, X)
predictions = get_predictions(A2)
return predictions
def test_prediction(index, W1, b1, W2, b2):
current_image = x_train[:, index, None]
prediction = make_predictions(x_train[:, index, None], W1, b1, W2, b2)
label = y_train[index]
print("Prediction: ", prediction)
print("Label: ", label)
dev_predictions = make_predictions(x_test, W1, b1, W2, b2)
get_accuracy(dev_predictions, y_test)
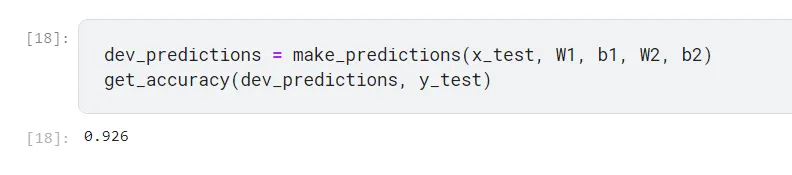
Captura de tela dos comandos finais do nosso programa
Uma precisão de 92,6% em dados que esse modelo nunca viu (Dados de Teste) é bem boa, considerando que usamos apenas 2 camadas empilhadas em nossa Rede Neural.
Parabéns para quem acompanhou este artigo.
Conclusão
Neste artigo, vimos como criar um simples Modelo de Aprendizado Profundo do zero, sem usar nenhuma abstração de bibliotecas de alto nível para nos ajudar a entender completamente a maneira como esses Modelos de Aprendizado Profundo funcionam.
Referências
Gostaria de agradecer a todos os seguintes artigos e vídeos que consultei enquanto criava este artigo.
[1] Samson Zhang: Building a neural network FROM SCRATCH [2] AI Solutions: Complete Deep Learning Course (Playlist) [3] Alexander Amini: MIT Introduction to Deep Learning | 6.S191 [4] Learn With Aparna: What is Generative AI | Difference between AI and Generative AI
Artigo original publicado por Steve Fernandes. Traduzido por Paulinho Giovannini.