
Série sobre Rede Neural Profunda do Zero em Rust
Espero que você tenha lido a parte 1 para entender a premissa de como uma rede neural funciona de maneira ampla e por que estamos usando o Rust para construir sua Rede Neural. Caso não tenha lido, eu recomendo fortemente que você navegue por este artigo: Rede Neural Profunda do Zero em Rust 🦀 - Parte 1 - Fundamentos da Rede Neural. Feito isso, vamos ver o que vamos aprender nesta parte da série.
- Iniciando um projeto Rust
- Adicionando e instalando dependências
- Carregando os dados para treinamento
- Criando uma estrutura de rede neural em Rust
- Implementando a inicialização aleatória dos parâmetros da rede neural
Iniciando um Projeto Rust
Se você não tiver o Rust instalado em seu computador, poderá começar facilmente visitando o site do Rust e seguindo as etapas de instalação. Além disso, você pode instalar a extensão rust-analyzer para o VS Code para melhorar sua experiência de programação em Rust. Uma vez instalado o Rust, vamos criar um novo projeto. Neste caso, iniciaremos o projeto Rust como uma biblioteca, já que nosso objetivo é criar um crate de rede neural que possa ser utilizado em várias aplicações de aprendizado de máquina. Para começar, abra seu terminal no diretório desejado para o projeto e execute o seguinte comando:
cargo new rust_dnn --lib
Aqui, rust_dnn é o nome de nossa biblioteca, e o sinalizador --lib indica que este projeto será usado como uma biblioteca em vez de um binário. Abra o diretório do projeto e inicie o VS Code nesta pasta.
Adicionando e Instalando Dependências
Você pode copiar o arquivo Cargo.toml seguindo o link do repositório Git fornecido abaixo ou executar os seguintes comandos da CLI do cargo no terminal a partir do diretório do projeto:
cargo add polars -F lazy
cargo add ndarray -F serde
cargo add rand
Estas são todas as dependências de que precisamos para esta parte. Podemos instalar essas dependências executando este comando:
cargo install
Carregando os Dados
Para nossa biblioteca de rede neural, vamos construir um classificador que possa identificar imagens de gatos e não gatos. Para simplificar o processo, converti essas imagens em matrizes de 3 canais de tamanho 64 x 64, que representam a resolução da imagem. Se achatarmos esta matriz, obtemos um vetor de tamanho (3 x 64 x 64), que é igual a 12288. Esse é o número de recursos de entrada que serão alimentados na rede. Embora possamos fazer a rede se adaptar a diferentes tamanhos de recursos de entrada, vamos projetá-la especificamente para este conjunto de dados por enquanto. Podemos generalizá-la ainda mais nas partes subsequentes.
Você pode baixar os conjuntos de dados de treinamento e teste como arquivos CSV daqui. Vamos criar uma função no arquivo lib.rs para carregar o arquivo CSV como um quadro de dados Polars. Isso nos permitirá pré-processar os dados, se necessário. No nosso caso, a única etapa de pré-processamento é separar os rótulos dos dados de entrada no arquivo CSV. A seguinte função realiza essa tarefa e retorna dois quadros de dados: um para os dados de entrada e um para os rótulos.
// lib.rs
use ndarray::prelude::*;
use polars::prelude::*;
use rand::distributions::Uniform;
use rand::prelude::*;
use std::collections::HashMap;
use std::path::PathBuf;
pub fn dataframe_from_csv(file_path: PathBuf) -> PolarsResult<(DataFrame, DataFrame)> {
let data = CsvReader::from_path(file_path)?.has_header(true).finish()?;
let training_dataset = data.drop("y")?;
let training_labels = data.select(["y"])?;
return Ok((training_dataset, training_labels));
}
Depois de carregar os dados como um quadro de dados Polars e separar os dados de entrada dos rótulos, precisamos converter os quadros de dados em ndarray, que pode ser usado como entrada para a rede neural. Esta função pode fazer isso para nós.
pub fn array_from_dataframe(df: &DataFrame) -> Array2<f32> {
df.to_ndarray::<Float32Type>().unwrap().reversed_axes()
}
Aqui você pode ver que invertemos os eixos. Isso ocorre porque precisamos dos dados de entrada no seguinte formato:
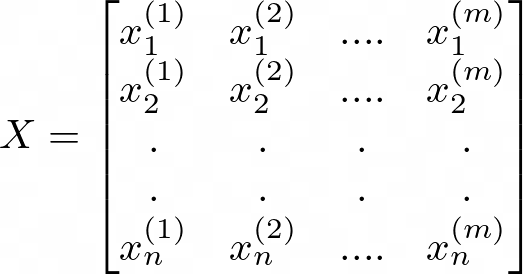
Representação em Matriz de n Recursos de Entrada e m Exemplos de Entrada
Onde m é o número de exemplos e n é o número de recursos para cada exemplo. Em nosso quadro de dados, tivemos a transposição disso. Então, invertemos os eixos para obter a forma correta de (n x m).
Criando uma Classe de Modelo de Rede Neural Profunda
A seguir, vamos criar uma estrutura que conterá os parâmetros de nossa Rede Neural, como o número de camadas, o número de unidades ocultas em cada camada e a taxa de aprendizado. No futuro, podemos adicionar mais parâmetros a esta estrutura.
struct DeepNeuralNetwork{
pub layers: Vec<usize>,
pub learning_rate: f32,
}
Inicializando Parâmetros Aleatórios
Precisamos inicializar os parâmetros da rede neural. Vejamos como os parâmetros podem ser representados para uma camada l de nossa rede.
Digamos, por exemplo, que temos uma rede de 3 camadas ocultas com número de unidades ocultas representadas por [100, 4,3,6], ou seja, 100 unidades de entrada, 4 unidades ocultas na primeira camada oculta, 3 na segunda e 6 na terceira. Para isso, a forma da matriz de peso (weight) para a primeira camada será (4 x 100), para a segunda camada (3x4) e para a terceira camada (6x4). E a forma da matriz de viés (bias) será (4x1) para a primeira camada, (3x1) para a segunda camada e (6x1) para a terceira camada. Em geral, esta é a representação matemática da matriz de peso e viés de qualquer camada l da rede.
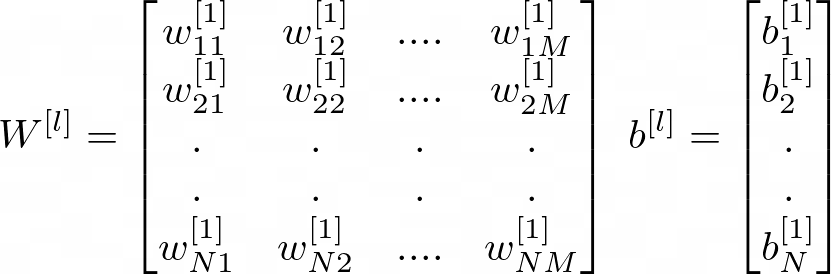
Matriz de Peso e Matriz de Viés

Aqui está uma implementação initialize_parameter para a estrutura DeepNeuralNetwork que cria essas matrizes e inicializa os pesos e vieses aleatoriamente:
impl DeepNeuralNetwork {
/// Inicializa os parâmetros da rede neural.
///
/// Retorna um dicionário mapa de hash de pesos e vieses inicializados
/// aleatoriamente.
pub fn initialize_parameters(&self) -> HashMap<String, Array2<f32>> {
let between = Uniform::from(-1.0..1.0); // número aleatório entre -1 e 1
let mut rng = rand::thread_rng(); // gerador de números aleatórios
let number_of_layers = self.layers.len();
let mut parameters: HashMap<String, Array2<f32>> = HashMap::new();
// Inicie o loop da primeira camada oculta para a camada de saída.
// Não estamos começando do 0 porque a camada zero é a camada de entrada.
for l in 1..number_of_layers {
let weight_array: Vec<f32> = (0..self.layers[l]*self.layers[l-1])
.map(|_| between.sample(&mut rng))
.collect(); //crie uma matriz de pesos achatados de valores (N * M)
let bias_array: Vec<f32> = (0..self.layers[l]).map(|_| 0.0).collect();
let weight_matrix = Array::from_shape_vec((self.layers[l], self.layers[l - 1]), weight_array).unwrap();
let bias_matrix = Array::from_shape_vec((self.layers[l], 1), bias_array).unwrap();
let weight_string = ["W", &l.to_string()].join("").to_string();
let biases_string = ["b", &l.to_string()].join("").to_string();
parameters.insert(weight_string, weight_matrix);
parameters.insert(biases_string, bias_matrix);
}
parameters
}
Nesta implementação, usamos o crate rand para gerar números aleatórios. Criamos uma distribuição uniforme entre -1 e 1 e usamos isso para amostrar números aleatórios para a inicialização de peso. Inicializamos os vieses para 0.0. Os pesos e vieses são armazenados em um HashMap (mapa de hash, tabela de dispersão), onde as chaves são strings representando o número da camada seguido por "W" para weights (pesos) ou "b" para bias (viés).
E é isso para esta parte! Cobrimos o início de um projeto Rust, adicionando dependências, carregando dados e inicializando parâmetros de rede neural. Na próxima parte, continuaremos construindo nossa rede neural implementando a propagação para frente. Fique ligado!
Siga-me no Medium para ficar atualizado sobre o próximo lançamento.
Quer se conectar?
Artigo original publicado por Akshay Ballal. Traduzido por Paulinho Giovannini.